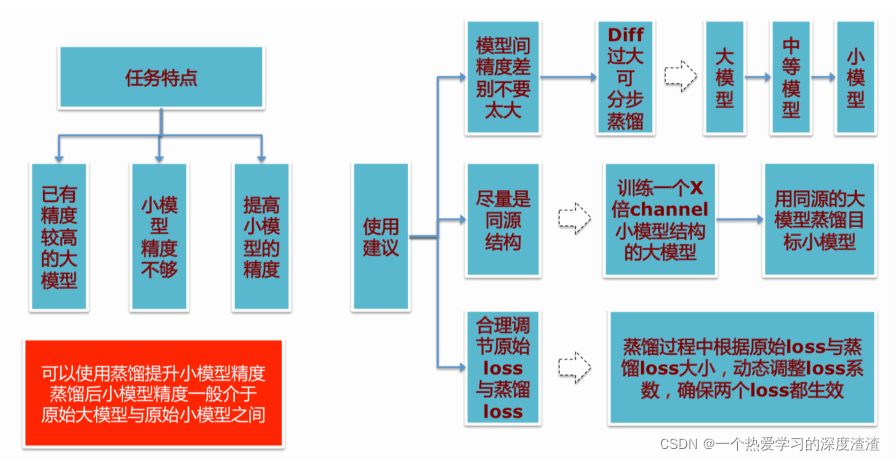
I. Overview
In one sentence : transfer the predictive power of a complex model to a smaller network;
(complex models are called teacher models, smaller models are called student models)
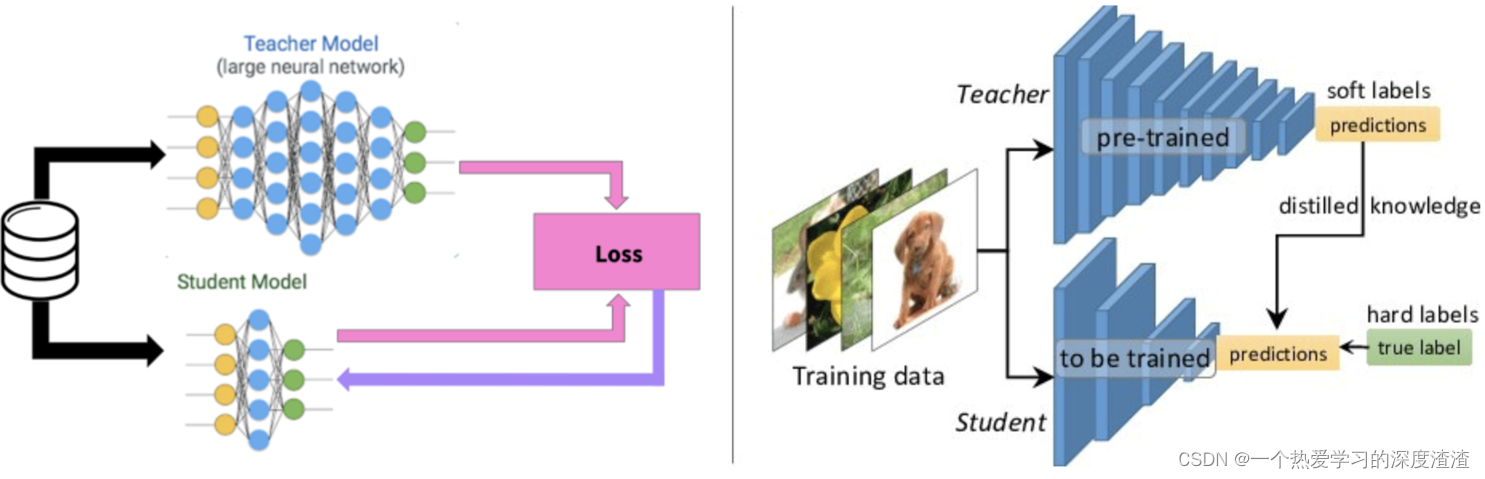
The concept of Teacher and Student:
- "Distill" the knowledge learned by the large network and transfer it to the small network, and the performance of the small network can be close to that of the large network;
- The distillation model (Student) is trained to imitate the output of the large network (Teacher), rather than just training directly on the original data. In this way, the small network can learn the abstract feature ability and generalization ability of the large network;
Second, the detailed process
method one
The simple process is as follows:
1. Train a teacher network on the data set;
2. Train a student network to "imitate" the teacher network;
3. Let the small network simulate the logits of the large network (following explanation);
Advantages: Teacher can help filter some noise labels. For Students, learning a continuous value is more efficient than 0, 1 labels, and the amount of information learned is greater;
What do logits mean?
Using the probability generated by the large model as the "soft target" of the small model can transfer the generalization ability of the large model to the small model. In this transfer stage, the same training set or a separate data set can be used to train the large model;
When the soft target entropy is high, it can provide more information and less gradient variance than hard targets during training, so small models can usually use fewer training samples and larger learning rates;
Note : The soft target here represents a specific probability value, and the output of values of 0 and 1 is usually called a hard target;
Let's look at a training process diagram:
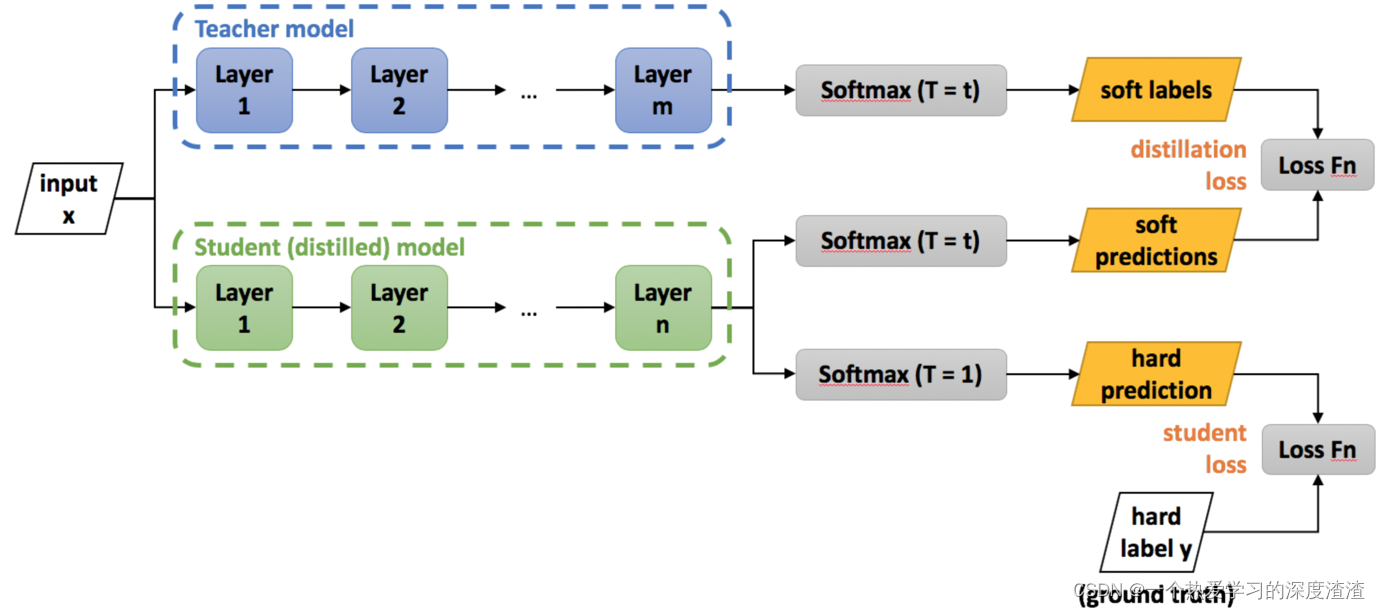
illustrate:
1. The output of the teacher network is used as the soft label of the student network, that is, the soft label, and the output value is a continuous value;
2. The output of the student network has two branches, one is soft predictions and the other is hard predictions, where hard means hard label, and the output value is in one-hot form;
3. The final Loss is the output of the student network and the soft labels of the teacher network and the actual hard labels to calculate the loss value, and finally combine the Loss values of the two;
A trick about softmax:
For the task of knowledge distillation, the softmax output function formula is improved;
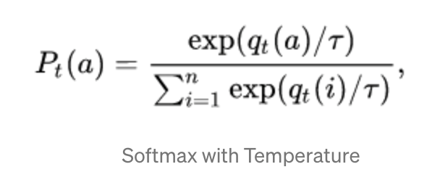
Explanation: A weight T variable is added. When T is large, the probability of all categories is almost the same, and the probability will be softer. When T is small, the probability of the category with the highest expected reward approaches 1; in the process of distillation, Increase the value of T until the teacher model produces a suitable set of soft targets, and then use the same T value to match these soft targets when training the student model;
The figure below is a practical example:

Method Two
FitNets:
Principle: The student uses the intermediate hidden layer information from the teacher to get better performance;
FitNets is a student network, narrower but deeper than the teacher network, adding a "guidance layer" to the student network, that is, learning from a hidden layer in the teacher network;
Let's take a look at the effect of the experiment:

3. Status analysis
1. The research on knowledge distillation has become extensive and specific in some fields, so that it is difficult to evaluate the generalization performance of a method;
2. Unlike other model compression techniques, distillation does not need to have a similar structure to the original network, which also means that knowledge extraction is very flexible and can theoretically be adapted to a wide range of tasks;
Advantages and disadvantages analysis:
Advantages: If there is a well-trained teacher network, less training data is required to train a smaller student network, and the less the network, the faster the speed; there is no need to maintain structural unity between the teacher and student networks;
Disadvantages: If there is no pre-trained teacher network, a larger data set and more time are required for distillation;
4. Code case
First of all, we first calculate the mean and variance of the data set, which is also a value often used in Normal;
Code example:
def get_mean_and_std(dataset):
"""计算数据集(训练集)的均值和标准差"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=2)
# 创建两个矩阵保存均值和标准差
mean = torch.zeros(3)
std = torch.zeros(3)
print('==> Computing mean and std..')
for inputs, targets in dataloader:
# 这里要注意是三个通道,所以要遍历三次
for i in range(3):
mean[i] += inputs[:, i, :, :].mean()
std[i] += inputs[:, i, :, :].std()
# 最后用得到的总和除以数据集数量即可
mean.div_(len(dataset))
std.div_(len(dataset))
return mean, std
The following is a simple case of knowledge distillation;
background:
teacher model: VGG16;
Student model: a custom model, which reduces some layers compared to VGG16;
Dataset: cifar10 dataset;
The steps of loading the two models during the distillation process are not shown here, specifically in the definition of the loss function:
# 默认交叉熵损失
def _make_criterion(alpha=0.5, T=4.0, mode='cse'):
# targets为teacher网络的输出,labels为student网络的输出
def criterion(outputs, targets, labels):
# 根据传入模式用不同的损失函数
if mode == 'cse':
_p = F.log_softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = -torch.mean(torch.sum(_q * _p, dim=1))
elif mode == 'mse':
_p = F.softmax(outputs/T, dim=1)
_q = F.softmax(targets/T, dim=1)
_soft_loss = nn.MSELoss()(_p, _q) / 2
else:
raise NotImplementedError()
# 还原原始的soft_loss
_soft_loss = _soft_loss * T * T
# 用softmax交叉熵计算hard的loss值
_hard_loss = F.cross_entropy(outputs, labels)
# 将soft的loss值和hard的loss值加权相加
loss = alpha * _soft_loss + (1. - alpha) * _hard_loss
return loss
return criterion
The above code is the most important part of knowledge distillation.
5. Expansion
You can refer to the summary papers of knowledge distillation in recent years: Papers
Summarize
Some suggestions for using knowledge distillation: