Model compression can be roughly divided into five types:
- Model pruning: remove components that have less effect on the results, such as reducing the number of heads and removing layers with less effect, shared parameters, etc. ALBERT belongs to this category;
- Quantization: For example, reduce float32 to float8;
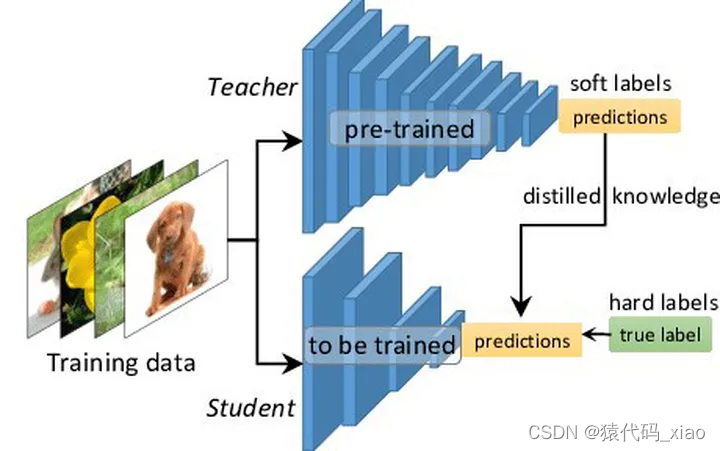
- Knowledge Distillation: Distill the ability of the teacher to the student. Generally, the student will be smaller than the teacher. We can distill a large and deep network to a small network, and we can also distill an integrated network to a small network.
- Parameter sharing: By sharing parameters, the purpose of reducing network parameters is achieved, such as ALBERT sharing the Transformer layer;
- Parameter matrix approximation: achieve the purpose of reducing matrix parameters by low-rank decomposition of the matrix or other methods;