I. Introduction

GaussDB is a new generation of distributed database released by Huawei on June 7, 2023. It adopts the share-nothing architecture , automatically shards data, and achieves strong transaction consistency through GTM-Lite technology. There is no central node performance bottleneck. It is independently developed by Huawei based on openGauss A distributed relational database, it is also known as the world's first artificial intelligence native (AI-Native) database. The product supports distributed transactions, cross-AZ deployment in the same city, zero data loss, supports expansion capabilities of 1000+ nodes, and PB-level mass storage. At the same time, it has key capabilities such as high availability, high reliability, high security, elastic scaling, one-click deployment, fast backup and recovery, and monitoring and alarming on the cloud. It can provide enterprises with comprehensive, stable, reliable, scalable, and superior performance enterprise-level databases. Serve. The default port of the GaussDB instance is 8000; for more information, please refer to the product official website and product documentation ; Among them, GaussDB is Huawei's commercial cloud-native database (not open source), and OpenGaussDB was announced on September 19, 2019. Huawei will open source its GaussDB database, open source The later product was named openGauss, and it was finally officially released as open source on June 30, 2020. The first official public version, openGauss 1.0.1, was released on October 12 to meet the high performance and high availability of databases for enterprise users. , high security requirements, and performance optimization with Kunpeng, based on the 2-way Kunpeng server, the data volume of 1000wh can run to 1.5 million tmpC, which is more than 50% of the performance of mainstream products in the industry, and 60% of the full-load failover time in the active-standby mode within 10 seconds. The core of openGauss is derived from PostgreSQL. OpenGauss supports stand-alone and one master and multiple backup deployment methods, but does not support distributed cluster deployment. In addition, we also have a domestic database TiDB;

GSDB can be used in various scenarios. At present, GaussDB has been applied in Huawei's internal IT system and core business systems of multiple industries. In the future, GaussDB will deeply cultivate financial scenarios, and move from the financial industry to other industries that have high requirements for databases.

Product advantages:
❥High security : GaussDB has TOP-level commercial database security features: data dynamic desensitization, TDE transparent encryption, row-level access control, secret state calculation, database audit, encryption authentication. It can meet the core security demands of government, enterprise and financial customers. It supports cross-computer rooms, same city, different places, multi-active high availability, supports distributed strong consistency, and zero data loss (RPO=0, RTO<10s).
❥Sound tools and service capabilities
GaussDB already has Huawei Cloud, commercial service deployment capabilities, and supports ecological tools such as DAS and DRS. Effectively guarantee the daily work needs of users such as development, operation and maintenance, optimization, monitoring, and migration.
❥The full-stack self-developed
GaussDB is based on the Kunpeng ecology, and is currently the only domestic brand in China that can achieve full-stack independent control . At the same time, GaussDB can continuously optimize the bottom layer based on hardware advantages to improve the overall performance of the product.
❥The open-source ecosystem
GaussDB has supported the open-source community and provided downloads of the main and backup versions.
❥High performance : strong performance, server-side connection pool, support 10,000-level concurrency, and provide up to 15 million tpmC (measures the transaction processing capability of the computer system, that is, the number of new orders processed by the system per minute") transactions at a scale of 32 nodes Processing capacity. 3-node TPCH standard performance pressure test, 500GB<200s, 1000GB<500s, the maximum data volume of a single cluster exceeds 4PB. ❥
High scalability: Through the optimization of distributed global transaction consistency , it breaks the traditional distributed performance bottleneck and realizes computing Free horizontal expansion of storage and storage, while supporting online data redistribution of new shards (online expansion without business interruption).
❥ Composite application scenarios: Row storage supports frequent business data update scenarios. Column storage supports business data addition and analysis scenarios. Memory tables, supporting high throughput, low latency, and extremely high performance scenarios.
☛ Related resources : openGauss community official website , openGauss code hosting platform , openGauss version 3.0.0 official documents , knowledge graph
Domestic database Top3:

2. Structure
2.1. Overall Architecture of Huawei GaussDB Distributed Form

The smallest management unit of GaussDB is an instance , and an instance represents an independently running database. Users can create and manage GaussDB instances on the console. GaussDB supports distributed and active/standby instances. The distributed form can support a large amount of data, and provides the ability of horizontal expansion, which can increase the data capacity and concurrency of the instance through capacity expansion. The master and backup versions are suitable for scenarios where the amount of data is small and the data will not increase significantly in the long run, but there are certain requirements for data reliability and business availability.
CN (Coordinator Node scheduling node): Responsible for database system metadata storage, decomposition and partial execution of query tasks, and aggregation of query results in DN.
DN (Data Node): Responsible for actually executing table data storage and query operations.

2.2. Logic structure diagram

In the figure above, the green part belongs to the core part of the openGauss database, and the total code volume of this part is about 950,000 lines. For more information: https://www.modb.pro/db/41842
2.3, openGauss architecture diagram

The OpenGauss database comes from the PostgreSQL-XC project, and the kernel comes from Postgres 9.2.4. The total code volume is about 120W lines, of which the kernel code is about 95W lines. Based on the needs of enterprise-level scenarios, Huawei has deeply integrated its years of experience in the database field, and added or modified about 700,000 lines of kernel code. The proportion of kernel code modification accounts for about 74% of the total kernel code, which is almost completely refactored. The original PostgreSQL interface and public function code (about 25W lines) are retained, and only these codes are properly optimized, which also makes openGauss better ecologically compatible with the existing PG. openGauss is a single-process, multi-threaded database. The client can use JDBC/ODBC/Libpq/Psycopg and other drivers to initiate a connection request to the back-end management thread GaussMaster of openGauss. The openGauss open source project led by Huawei has done a lot of optimization on the database architecture, transaction management, storage engine, SQL optimizer, and Kunpeng chip, realizing the key value features of the enterprise level: high performance, high security, easy operation and maintenance, and full openness . Therefore, openGauss can also be understood as an enhanced version of PostgreSQL.
When the GaussMaster thread receives the service request sent by the client program, it will immediately fork() a sub-thread according to the received information. After the sub-thread successfully authenticates the request, it becomes the corresponding back-end business processing sub- thread ( gaussdb ). Afterwards, the request sent by the client will be processed by this business processing sub-thread ( gaussdb ). When the business processing sub-thread (gaussdb) receives the query (SQL) sent by the client, it will call the SQL engine of openGauss to perform lexical analysis, syntax analysis, semantic analysis, query rewriting and other processing operations on the SQL statement, and then use the query The optimizer generates the least-cost query path plan. Afterwards, the SQL executor will execute the SQL statement according to the established optimal execution plan, and feedback the execution result to the client.
During the execution of the SQL executor, the memory shared buffer (such as: shared buffer, cstore buffer, MOT, etc.) is usually accessed first. The memory shared buffer caches the frequently accessed indexes, table data, execution plans, etc. of the database. The high-speed RAM hardware of the shared buffer provides an efficient operating environment for SQL execution, greatly reduces disk IO, and greatly improves database performance. It is one of the most important components of the database.
The shared buffer is the buffer used by the row storage engine by default. The row storage engine of openGauss stores tables on the hard disk partition by row. It adopts MVCC multi-version concurrency control. The reading and writing between transactions do not conflict with each other, and has good concurrency performance. , suitable for OLTP scenarios.
cstore buffers is the buffer used by the column storage engine by default. The column storage engine divides the entire table into several CUs (Compression Units) according to different columns, and manages them in units of CUs, which is suitable for OLAP scenarios.
MOT is the default buffer used by the memory engine. The index structure and overall data organization of openGauss' MOT memory engine are based on the Masstree model. Its optimistic concurrency control and efficient cache block utilization enable openGauss to fully utilize the performance of memory , at the same time, on the premise of ensuring high performance, the memory engine has parallel persistence and checkpoint capabilities compatible with the original mechanism of openGauss (CALC logic consistency asynchronous checkpoint), ensuring permanent storage of data, suitable for high throughput and low Latency business processing scenarios.
The operation of the SQL executor on the data page in the shared buffer will be recorded in the WAL buffer . When the client initiates a transaction commit request, the content of the WAL buffer will be flushed to disk by the WalWriter thread and saved in the WAL log file . Make sure that those committed transactions are permanently recorded and cannot be lost. However, it should be noted that when the write operation of the wal writer cannot keep up with the actual needs of the database, the regular backend thread still has the right to perform WAL log flushing. This means that WALWriter is not a necessary process and can be shut down quickly when requested.
maintenance_work_mem is generally used when openGauss performs maintenance operations, such as: VACUUM, CREATE INDEX, ALTER TABLE ADD FOREIGN KEY and other operations. The size of the maintenance_work_mem memory area determines the execution efficiency of maintenance operations.
temp_buffer is a LOCAL temporary buffer used by each database session, which mainly caches the temporary table data accessed by the session. It should be noted that openGauss supports global temporary tables and session-level temporary tables. The table definition of global temporary tables is global, while the data of temporary tables is private to each session.
work_mem is the memory buffer used before the transaction performs internal sorting or the Hash table is written to the temporary file.

3. Deployment
3.1. Resources
The resource utilization rate should be controlled between 40% and 70% as much as possible. If it is lower than 40%, it is recommended to reduce the capacity, and if it is higher than 70%, it is recommended to expand the capacity.
3.2. Database usage specification
See Huawei Recommendations .
3.3. Deployment method
1) Centralized deployment
Centralized deployment includes two types: stand-alone and active/standby.
Taking active backup as an example, it supports 1+2 (maximum protection) active backup, hot backup based on database log replication, and provides high availability when the stand-alone performance can meet the demand.
Among them, 1+1 (maximum availability) means that data will be written to the standby machine synchronously. However, if there is an impact such as the network, the synchronous operation cannot be completed, and it will be converted to asynchronous. Subsequent network recovery will automatically catch up. During data out-of-sync, there will be data loss during handover.
1+2 (maximum protection) means that the data will be written to the standby machine synchronously, and a confirmation is required before being returned to the client. High reliability.
The centralized version has an open source ecosystem, and users can directly download it through the open source website. As the only open source database in China, it is also the best proof that Huawei is open source, open, and does not lock in a single vendor.
2) Distributed deployment:
In terms of distributed deployment, data is divided into shards, and read and write loads expand quasi-linearly to meet large-scale business scenarios and support high-availability deployments in two locations and three centers. In addition, the distributed version carries HUAWEI CLOUD's self-developed distributed component system, which is a strong guarantee for traditional enterprises to embrace the Internet and face the challenges of future massive transaction scenarios, and is suitable for HUAWEI CLOUD deployment.
3.4. Deployment process
See: https://opengauss.org/zh/blogs/jiajunfeng/openGauss2-0-0%E4%B8%BB%E5%A4%87%E5%AE%89%E8%A3%85%E9%83% A8%E7%BD%B2.html
3.5. Directory description
| directory name | illustrate |
|---|---|
| base | The openGauss database objects are stored in this directory by default, such as the default database postgres, user-created databases and associated tables, etc. |
| global | Store openGauss shared system tables or shared data dictionary tables |
| pg_tblspc | That is, the table space directory of openGauss, which stores the directory soft links of the table spaces defined by openGauss, and these soft links point to the actual storage directory of the openGauss database table space files |
| pg_xlog | Stores the WAL log files of the openGauss database |
| pg_clog | Store openGauss database transaction submission status information |
| pg_csnlog | Store the snapshot information of the openGauss database. When the openGauss transaction starts, a CSN snapshot will be created. Under the MVCC mechanism, the CSN is used as the logical time stamp of openGauss to simulate the internal timing of the database to determine whether other transactions are visible to the current transaction. |
| pg_twophase | Store two-phase transaction commit information to ensure data consistency |
| pg_serial | Store committed serializable transaction information |
| pg_multixact | Store multi-transaction status information, generally used for shared row locks (shared row locks) |
| Archived WAL | Archive directory of openGauss database WAL logs, save historical WAL logs of openGauss |
| pg_audit | Store audit log files for the openGauss database |
| pg_replslot | Store replicated transaction slot data for the openGauss database |
| pg_llog | Save the state data at the time of logical replication |
| file name | illustrate |
|---|---|
| postgresql.conf | The configuration file of openGauss, which will be read when the gaussmaster thread starts to obtain configuration information such as listening address, service port, memory allocation, function settings, etc., and according to this file, shared memory and semaphore pools will be created when openGauss starts |
| pg_hba.conf | Host-based access authentication configuration file, which mainly saves authentication information (such as: databases allowed to access, users, IP segments, encryption methods, etc.) |
| pg_ident.conf | The configuration file for client authentication mainly saves user mapping information, and maps the users of the host operating system with the users of the openGauss database |
| gaussdb.state | Mainly save the current state information of the database (such as: the role of the active and standby HA, rebuild progress and reason, sync state, LSN information, etc.) |
4. Scenario application
4.1. Financial transaction system scenario: large capacity, high availability, concurrent high performance

4.2. Enterprise ERP/CRM integration
Its excellent performance in scenarios such as long transactions and ultra-complex SQL can well meet the complex business models of ERP/CRM.

4.3. Government and enterprise office scenarios: multi-tenant resource management
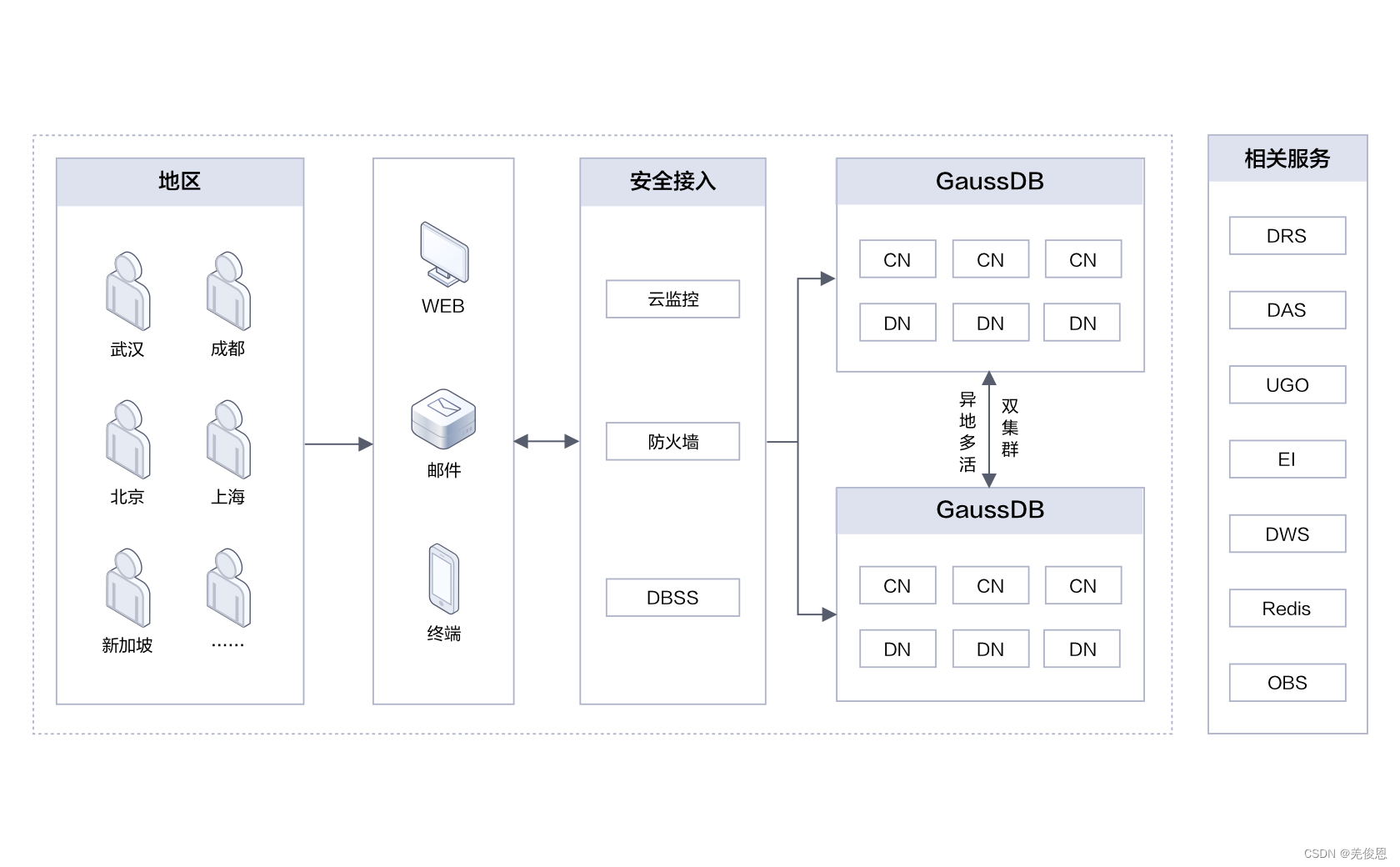
5. Appendix:
5.1. Cloud platform region and AZ
Region : Divided from the dimensions of geographical location and network latency, public services such as elastic computing, block storage, object storage, VPC network, elastic public network IP, and mirroring are shared within the same Region. Regions are divided into general regions and dedicated regions. A general region refers to a region that provides general cloud services for public tenants; a dedicated region refers to a dedicated region that only carries the same type of business or only provides business services for specific tenants.
Availability Zone (AZ, Availability Zone): An AZ is a collection of one or more physical data centers, with independent wind, fire, water and electricity. In the AZ, resources such as computing, network, and storage are logically divided into multiple instances. Multiple AZs in a Region are connected through high-speed optical fibers to meet the needs of users to build high-availability systems across AZs.
5.2. Capabilities to be met
Deployment and implementation of openGaussDB products;
implementation and maintenance of openGaussDB product-related projects;
openGaussDB product customer technical questions answering, product training, troubleshooting;
openGaussDB product peripheral operation and maintenance tool development;
5.3, database driver
JDBC : JDBC (Java Database Connectivity, Java database connection) is a Java API for executing SQL statements, which can provide a unified access interface for various relational databases, and applications can operate data based on it. The openGauss library provides support for JDBC 4.0 features. It needs to use JDK1.8 version to compile the program code, and does not support the JDBC bridging ODBC method.
ODBC : ODBC (Open Database Connectivity, Open Database Interconnection) is an application programming interface for accessing databases proposed by Microsoft based on X/OPEN CLI. The application program interacts with the database through the API provided by ODBC, which enhances the portability, scalability and maintainability of the application program. openGauss currently provides support for ODBC 3.5. However, it should be noted that the current database ODBC driver is based on the open source version. For tinyint, smalldatetime, and nvarchar2 types, incompatibility may occur when obtaining data types.
Libpq : Libpq is the C language programming interface of openGauss. The client application can send query requests to the openGauss backend service process through Libpq and obtain the returned results. It should be noted that, as mentioned in the official document, openGauss has not verified the use of this interface in the application development scenario. It is not recommended that users use this interface for application development. It is recommended that users use ODBC or JDBC interfaces instead.
Psycopg : Psycopg can provide a unified Python access interface for the openGauss database to execute SQL statements. The openGauss database supports Psycopg2 features. Psycopg2 is a package of libpq, which is mainly implemented in C language, which is efficient and safe. It has client-side and server-side cursors, asynchronous communication and notifications, and supports "COPY TO/COPY FROM" functions. Supports multiple types of Python out of the box, and adapts to PostgreSQL data types; through a flexible object adaptation system, it can be extended and customized. Psycopg2 is Unicode and Python 3 compatible.