Editor's note: When we look back at the development of artificial intelligence in the past ten years, we can see a transformation that is still ongoing, which has had a profound impact on the way we work, business operations and interpersonal behavior. From AlexNet in 2013 to variational autoencoders, to the recent generative large models, the continuous breakthroughs in artificial intelligence technology have promoted the vigorous development of the entire field.
This article will give you an in-depth interpretation of these key technological breakthroughs, and look forward to the future development trend of artificial intelligence. Whether you are a developer or researcher in the AI industry, or a general reader who is curious about the latest AI technology development, we eagerly hope that this article can provide you with some help.
Let us explore and embrace artificial intelligence together!
The following is the translation, Enjoy!
Author | Thomas A Dorfer
Compile | Yue Yang
Table of contents
- 01 2013: AlexNet and variational self-encoding
- 02 2014: Generative Adversarial Networks
- 03 2015: Breakthroughs in ResNets and NLP
- 04 2016: AlphaGo
- 05 2017: Transformer architecture and language model
- 06 2018: GPT-1, BERT and graph neural networks
- 07 2019: GPT-2 and improved generative models
- 08 2020: GPT-3 and self-supervised learning
- 09 2021: AlphaFold 2, DALL-E and GitHub Copilot
- 10 2022: ChatGPT and Stable Diffusion
- 11 2023: LLMs and Bots
- 12 Looking back & looking to the future
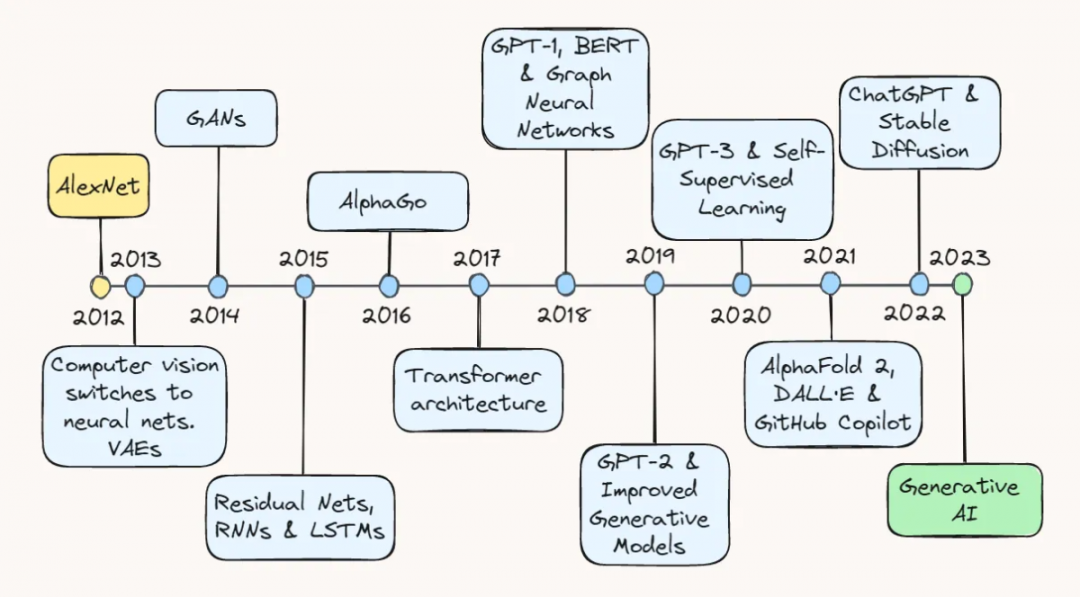
Image by the Author.
The past decade has been an exciting time for the field of artificial intelligence. From the initial exploration of the potential of deep learning to the explosion of the entire field, applications in the field today include recommendation systems for e-commerce, object detection for self-driving cars, and generative models (creating realistic images, coherent text, etc.) content.
In this post, we'll take a walk down memory lane and revisit some of the key technological breakthroughs that got us to where we are today. Whether you're a veteran artificial intelligence practitioner or simply interested in the latest developments in the field, this article will provide you with a comprehensive overview of the technological advances that have made artificial intelligence (AI) a household term.
01 2013: AlexNet and Variational Autoencoder
2013 is considered by many to be the year in which deep learning came of age, due to major advances in computer vision. According to a recent interview by Geoffrey Hinton [1], by 2013, "almost all computer vision research has turned to neural networks" . The craze was largely fueled by a rather surprising breakthrough in image recognition a year ago (2012).
In September 2012, AlexNet [2], a deep convolutional neural network (CNN), achieved record-breaking results in the ImageNet Large-Scale Visual Recognition Competition (ILSVRC), demonstrating the potential of deep learning in image recognition tasks. Its Top-5 error rate [3] is 15.3%, which is 10.9% lower than its closest competitor.
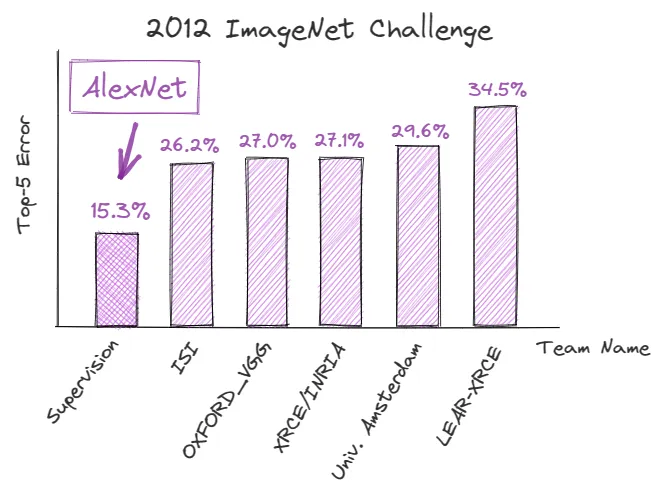
Image by the Author.
The technological improvements behind this success have greatly facilitated the development of artificial intelligence and dramatically changed the perception of deep learning.
首先,AlexNET的作者采用了一个由五个卷积层(convolutional layers)和三个全连接线性层(fully-connected linear layers)组成的deep CNN——该网络架构当时被许多人认为是不实用的。此外,由于网络的深度产生了大量参数,训练是在两个图形处理单元(GPUs)上并行进行的,证明了在大型数据集上进行快速训练的能力。通过使用更高效的修正线性单元(Rectified Linear Unit,ReLU)[4],传统的激活函数(如sigmoid和tanh)被替换,更进一步缩短了训练时间。
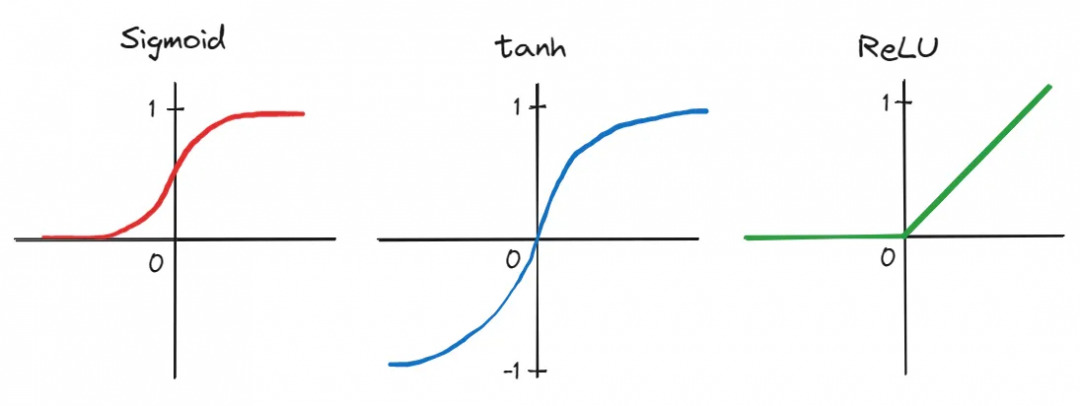
Image by the Author.
这些技术进展共同推动了AlexNet的成功,使其成为人工智能历史上的一个转折点,并引发学术界和科技界对深度学习的兴趣激增。因此,许多人认为2013年是深度学习真正开始起飞的一座分水岭。
同样也发生在2013年的(尽管有点被AlexNet的浩大声势所掩盖)是变分自编码器(或被称为VAEs[5])的发展——生成式模型可以学习表达(represent)和生成数据(如图像和声音)。它们通过学习输入数据在低维空间(称为隐空间(latent space))的压缩表示来工作。这使它们能够通过从已学习的隐空间中进行采样生成新的数据。后来,VAEs被认为开辟了新的生成模型(generative modeling)和数据生成途径,并在艺术、设计和游戏等领域得到应用。
02 2014年:生成式对抗网络
这之后第二年,即2014年6月,Ian Goodfellow及其同事提出了生成式对抗网络(GANs)[6],这是深度学习领域又一个重大的进展。
GANs are a type of neural network capable of generating new data samples similar to the training set. Essentially two networks are trained simultaneously: (1) a generator network that generates fake or synthetic samples, and (2) a discriminator network that evaluates their authenticity. The training takes place in a game-like setting, where the generator tries to create samples that can fool the discriminator, and the discriminator tries to correctly identify fake samples.
At the time, GANs represented a powerful and novel data generation tool, not only for generating images and videos, but also for music and art. GANs demonstrate the possibility of generating high-quality data samples without relying on explicit labels (explicit labels), this possibility has made a large contribution to the progress of unsupervised learning, and this field has been widely used before. considered relatively underdeveloped and challenging.
03 2015: Breakthroughs in ResNets and NLP
In 2015, the field of artificial intelligence made considerable progress in both computer vision and natural language processing (NLP).
Kaiming He and colleagues published a paper called "Deep Residual Learning for Image Recognition" [7], which proposed the concept of residual neural networks (ResNets) . This architecture makes it easier for information to flow through the network by adding shortcuts. Unlike conventional neural networks, where each layer takes the output of the previous layer as input, in ResNet, additional residual connections (residual connections) are added, skipping one or more layers and directly connecting to deeper layers in the network.
Therefore, ResNets are able to solve the vanishing gradients [8] problem, making it possible to train deeper neural networks. This in turn has led to significant advances in processing image classification and object recognition tasks.
大约在同一时间,研究人员在循环神经网络(RNNs) [9]和长短期记忆(LSTM) [10]模型的开发方面也取得了相当大的进展。尽管这些模型自20世纪90年代以来就已经存在,但是它们直到2015年左右才开始引起一定的关注,主要是由于以下因素:
(1)2015年时可用于训练的数据集更大、更多样化;
(2)计算能力和硬件的改进,可训练更深层次、更复杂的模型;
(3)从这些模型出现到2015年的这段时间中所进行的模型改进,如更复杂的门控机制(gating mechanisms)。
因此,这些架构使语言模型能够更好地理解文本的语境和含义,从而在语言翻译、文本生成和情感分析等任务中得到了极大的改进。当时RNNs和LSTMs的成功为我们今天所见到的大语言模型(LLMs)的开发铺平了道路。
04 2016年:AlphaGo
1997年,加里·卡斯帕罗夫(Garry Kasparov)被IBM的深蓝(Deep Blue)打败之后,人类和机器之间的另一场比赛于2016年掀起了轩然大波:谷歌的AlphaGo击败了围棋世界冠军李世石。

Photo by Elena Popova on Unsplash.
Lee Sedol's defeat marked another major milestone in the history of artificial intelligence: It showed that machines could beat even the most skilled human players at games once considered too complex to be handled by computers. AlphaGo analyzed millions of positions from previous games and evaluated the best possible moves using a combination of deep reinforcement learning [11] and Monte Carlo tree search [12] Location - This strategy far exceeds human decision-making capabilities in this case.
05 2017: Transformer architecture and language model
Arguably, 2017 was arguably the most pivotal year in laying the groundwork for the breakthrough advances in generative AI we see today.
In December 2017, Vaswani and colleagues released a basic paper called "Attention is all you need" [13], introducing Transformer that uses the concept of self-attention (self -attention) [14] to process sequential input data architecture. This makes the processing of long-range dependencies more efficient, which is still a challenge for traditional recurrent neural network structures.

Photo by Jeffery Ho on Unsplash.
Transformer consists of two important components: encoder and decoder . The encoder is responsible for encoding the input data, which can be a sequence of words. Then, it takes an input sequence and applies multiple layers of self-attention and feed-forward neural nets to capture the relationships and features present within sentences and learn meaningful representations.
Essentially, self-attention enables the model to understand the relationship between different words in a sentence. Unlike traditional models, which process words in a fixed order, the transformer actually considers all words at the same time . They assign each word a metric called attention scores, based on how related the word is to other words in the sentence.
On the other hand, the decoder takes as input the encoded representation of the encoder and produces an output sequence. In tasks such as machine translation or text generation, a decoder generates translation sequences based on the input it receives from an encoder. Similar to the encoder, the decoder also includes multiple layers of self-attention and feed-forward neural networks. However, it also includes an additional attention mechanism that enables it to focus on the output of the encoder . This way, the decoder can take into account relevant information from the input sequence when generating output.
Since the advent of the Transformer architecture, it has become a key component of LLM development and has made breakthroughs in NLP fields such as machine translation, language modeling, and question answering.
06 2018: GPT-1, BERT and graph neural networks
A few months after Vaswani et al. published their paper, OpenAI launched the Generative Pre-Training Transformer (ie, GPT-1) [15] in June 2018, which leverages the Transformer architecture to efficiently capture long-range dependencies in text. GPT-1 was one of the first models to demonstrate the effects of fine-tuning for specific NLP tasks after unsupervised pre-training.
In addition, Google also used the Transformer architecture, which was still very new at the time, to release and open source their own pre-training method at the end of 2018, called Bidirectional Encoder Representations from Transformers, or BERT [16]. Unlike previous models (including GPT-1) that process text in a unidirectional manner, BERT simultaneously considers the context of each word in both directions. To illustrate this point, the author provides a very intuitive example:
...in the sentence "I visit a bank account", the unidirectional contextual model will represent "bank" based on "I visit" rather than "account". However, BERT uses its context—"I access ... account"—to mean "bank". Starting from the bottom layer of the deep neural network, it is deeply bidirectional.
Bidirectionality is very strong, allowing BERT to outperform current NLP systems on various benchmark tasks.
In addition to GPT-1 and BERT, graph neural networks (GNN) [17] also caused a bit of a stir that year. They belong to a class of neural networks specifically designed to work with graph data. GNN uses a message passing algorithm to propagate information on the nodes and edges of the graph. This allows the network to learn the structure and relationships of the data in a more intuitive way.
This work allows researchers to extract deeper information from data, thereby expanding the scope of applications of deep learning. With GNNs, AI has made significant progress in areas such as social network analysis, recommender systems, and drug research.
07 2019: GPT-2 and improved generative models
In 2019, generative models had some important progress, especially the introduction of GPT-2 [18]. The model has state-of-the-art performance in many NLP tasks, truly eclipsing similar models, and is also capable of generating highly realistic text content. It now appears that this heralds the upcoming "big bang" in this field.
Other advances in the field that year included DeepMind's BigGAN [19], which generated high-quality images virtually indistinguishable from real images, and NVIDIA's StyleGAN [20], which allowed for greater control over the appearance of these generated images.
Collectively, these advances in what is now called generative AI push the boundaries of the field of artificial intelligence even further, and…
08 2020: GPT-3 and self-supervised learning
…Shortly after, another model came out, one that became a household name even outside the tech world: GPT-3 [21]. This model represents a dramatic increase in the size and capabilities of LLMs. GPT-1 has only 1.17 million parameters, while GPT-2 has increased to 1.5 billion, and GPT-3 has reached 175 billion.
Such a huge parameter enables GPT-3 to generate very coherent text in various prompts and tasks, and it also shows the much-anticipated performance and excellence in the completion of NLP tasks such as text completion, question answering and even creative writing.
Furthermore, GPT-3 again highlights the potential of using self-supervised learning , which allows models to be trained on large amounts of unlabeled data. The benefit of self-supervised learning is that the model can acquire a general understanding of language without extensive task-specific training, which makes it more affordable.
Yann LeCun tweeted a New York Times article about self-supervised learning
09 2021: AlphaFold 2, DALL-E and GitHub Copilot
From protein folding to image generation to automated coding assistants, 2021 is a year full of surprises thanks to the release of AlphaFold 2, DALL·E, and GitHub Copilot.
AlphaFold 2 [22] is a solution to the decades-old unsolved protein folding problem. Researchers at DeepMind extended the Transformer architecture and created evoformer (a structure that uses evolutionary strategies for model optimization) to build a model that can predict the three-dimensional structure of proteins from one-dimensional amino acid sequences. This breakthrough has enormous potential to revolutionize drug discovery, bioengineering, and our understanding of biological systems.
OpenAI also became the focus of news again this year, they released DALL·E [23]. Essentially, this model combines GPT-style language models with the concept of image generation, making it possible to create high-quality images from textual descriptions.
To demonstrate the power of this model, take a look at the image below, generated from the Prompt “Oil painting of a futuristic world with flying cars”.

Image produced by DALL·E.
Finally, GitHub released Copilot [24]. This is made possible by Github in partnership with OpenAI, which provides an underlying language model, Codex, that was trained using a large amount of publicly available code and learned to understand and generate code in various programming languages. Developers can simply provide a code comment stating the problem they are trying to solve, and the model will write the code to implement the solution. There are other features, including describing the entered code in natural language and converting code between various programming languages.
10 2022: ChatGPT and Stable Diffusion
The rapid development of artificial intelligence in the past decade has culminated in a groundbreaking development : OpenAI released ChatGPT in November 2022 [25]. The tool is considered to represent the state-of-the-art in natural language processing, capable of generating coherent and contextual responses to various queries and prompts. In addition, it can hold conversations, provide explanations of problems, offer creative suggestions, assist with problem solving, write and explain code, and even simulate different personalities or writing styles.

Image by the Author.
人们可以在简单而直观的界面与机器人进行互动也刺激了可用性(usability)的急剧上升。以前,主要是技术界会琢磨最新的基于人工智能的新技术。然而现在,AI工具已经渗透到几乎所有专业领域,从软件工程师到作家、音乐家和广告商。许多公司也在使用这种模型来实现服务自动化(automate services),如客户支持、语言翻译或回答常见问题。事实上,我们现在正看到的自动化浪潮(the wave of automation) 已经重新引起了一些担忧,并引发了对自动化有关风险的讨论。
虽然2022年ChatGPT获得了很多关注,但图像生成方面也有了重大的进展。Stability AI发布了Stable diffusion[26],一种潜在的文转图扩散模型,能够通过文本描述生成逼真的照片。
Stable diffusion是传统扩散模型的延伸,它迭代地向图像添加噪声,然后逆转过程来恢复数据。它被设计成不直接在输入图像上操作,而是在它们的低维表示或隐空间(latent space)上操作,从而加速这一过程。 此外,扩散过程是通过向网络添加来自用户的transformer-embedded text prompt来修改的,从而使其在每次迭代中引导图像生成过程。
总的来说,2022年发布的ChatGPT和Stable diffusion突显了多模态、生成式AI的潜力,并引发了对该领域进一步发展和投资的推动。
11 2023年:LLMs和Bots
今年无疑是LLMs和chatbots大展身手的一年。越来越多的大模型正以迅猛的速度问世和迭代。
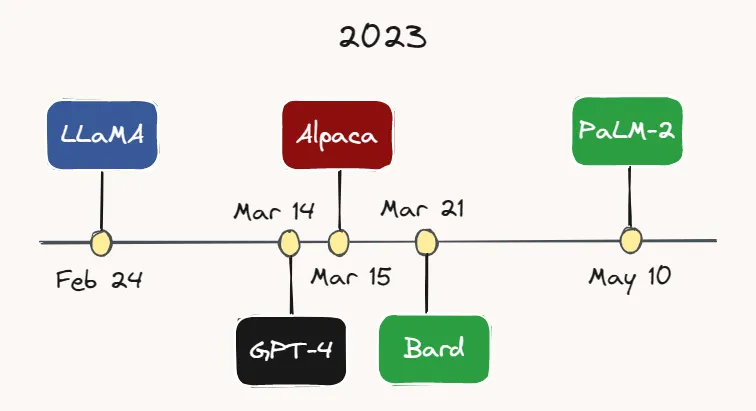
Image by the Author.
For example, Meta AI released LLaMA [27] — an LLM that performs better than GPT-3 with a much smaller number of parameters — on February 24. Less than a month later, on March 14, OpenAI released GPT-4 [28] — a larger, more capable and multimodal version of GPT-3. While the exact number of parameters for GPT-4 is unknown, it is speculated that it could be in the trillions.
On March 15th, researchers at Stanford University released Alpaca [29], a lightweight language model based on LLaMA via instruction-following The method of fine-tuning the model) was fine-tuned. A few days later, on March 21, Google launched its ChatGPT competitor: Bard [30]. Google also just released its latest LLM — PaLM-2 [31] on May 10 earlier this month. At this rate of development, it's quite possible that by the time you're reading this, yet another new model will have emerged.
We are also seeing more and more companies integrating these models into their products. For example, Duolingo announced the launch of GPT-4-based Duolingo Max [32], a new subscription service that aims to provide language lessons tailored to each individual. Slack has also launched an AI assistant called Slack GPT [33] that can complete tasks such as drafting responses and summarizing conversations. In addition, Shopify has introduced a ChatGPT-powered assistant in its store app, which can help customers identify desired products through various prompts.
Shopify announces its ChatGPT-powered AI assistant on Twitter
Interestingly, AI chatbots are even considered as a replacement for human therapists these days. For example, the American chatbot application Replika [34] provides users with an "AI companion who cares about you, always listens and talks to you, and is always by your side". Its founder, Eugenia Kuyda, says the app's clientele ranges from autistic children looking to "warm up before socializing" to lonely adults who just need a friend.
Finally, I want to highlight the high point of AI development in the last decade : people use Bing ! Earlier this year, Microsoft launched its GPT-4-based “copilot for the web”[35], custom-built for search, and for the first time in a long time, it became a serious competitor to Google in the search business .
12 Looking back & looking to the future
When we look back at the evolution of AI over the past decade, it’s clear that we’ve been witnessing a transformation that has had a profound impact on the way we work, our business models, and our human interactions. Significant progress has been made recently in generative models, especially LLMs. The development of generative models seems to adhere to a common belief that "bigger is better", of course referring to the total number of adjustable parameters contained within the model (the parameter space of the models). This is especially evident in the GPT series, which starts with 1.17 million parameters (GPT-1) and increases by about an order of magnitude with each subsequent version of the model, culminating in GPT-4 with potentially trillions of parameters.
However, in a recent interview [36], OpenAI CEO Sam Altman argued that we have reached the end of the era of "bigger is better" parameters. Looking ahead, he still sees an upward trend in the number of parameters, but the main focus of future model improvements will be on increasing the functionality, utility, and safety of the model.
This last point is especially important. These powerful AI tools are now in the hands of the masses and no longer confined to the controlled environment of research labs, and now more than ever we need to exercise caution to ensure these tools are safe and in the best interest of humanity . Hopefully we will see the same development and investment in AI security as in other fields.
END
References
1.https://venturebeat.com/ai/10-years-on-ai-pioneers-hinton-lecun-li-say-deep-learning-revolution-will-continue/
2.https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
3.https://machinelearning.wtf/terms/top-5-error-rate/
4.https://www.cs.toronto.edu/~fritz/absps/reluICML.pdf
5.https://arxiv.org/abs/1312.6114
6.https://proceedings.neurips.cc/paper_files/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
7.https://arxiv.org/abs/1512.03385
8.https://en.wikipedia.org/wiki/Vanishing_gradient_problem
9.https://en.wikipedia.org/wiki/Recurrent_neural_network
10.https://pubmed.ncbi.nlm.nih.gov/9377276/
11.https://en.wikipedia.org/wiki/Deep_reinforcement_learning
12.https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
13.https://arxiv.org/abs/1706.03762
14.https://en.wikipedia.org/wiki/Attention_(machine_learning)
15.https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
16.https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
17.https://en.wikipedia.org/wiki/Graph_neural_network
18.https://openai.com/research/gpt-2-1-5b-release
19.https://www.deepmind.com/open-source/big-gan
20.https://github.com/NVlabs/stylegan
21.https://arxiv.org/abs/2005.14165
22.https://www.nature.com/articles/s41586-021-03819-2
23.https://openai.com/dall-e-2/
24.https://github.com/features/copilot
25.https://openai.com/blog/chatgpt
26.https://stability.ai/blog/stable-diffusion-public-release
27.https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
28.https://openai.com/product/gpt-4
29.https://crfm.stanford.edu/2023/03/13/alpaca.html
30.https://blog.google/technology/ai/bard-google-ai-search-updates/
31.https://ai.google/discover/palm2
32.https://blog.duolingo.com/duolingo-max/
33.https://slack.com/blog/news/introducing-slack-gpt
34.https://replika.com/
35.https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/
36.https://techcrunch.com/2023/04/14/sam-altman-size-of-llms-wont-matter-as-much-moving-forward/?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS8&guce_referrer_sig=AQAAAANxF1G0qEgpUn-9mD7CxuZrc77IDr8t-QvyX3Do6Koa10eGy5DYiq3lzXDAJRakptl0Jy49OkuxXU8zD-3-8l-h3YJxFgKRwk5HqIHdhG2BIXavq5Tfn1HHz6IKk8-y86xZbyHXZJwE_Q_OFXr4nrHygrl48-WxX7vdgTft_lhw
This article is authorized by the original author and compiled by Baihai IDP. If you need to reprint the translation, please contact us for authorization.
Original link :
https://towardsdatascience.com/ten-years-of-ai-in-review-85decdb2a540