Common high-availability means of the Internet. For example, service redundancy deployment, asynchronous design, load balancing, service current limiting and downgrading fuse, architecture splitting, service governance, distributed storage, etc. Today we mainly talk about the disaster recovery architecture mode of multi-computer room deployment to ensure High availability of services.
::: hljs-center
Common Architecture Patterns
:::
There are several common modes of disaster recovery architecture, which are basically divided into multi-centers in the same city, multi-centers across cities, and multi-centers across countries. Literally, these architectural patterns seem to be similar, only the difference in distance, and other feelings are similar. However, the difference in simple distance will lead to a big difference in the key application scenarios and technical essence in the architecture.
::: hljs-center
1. Intra-city multi-center architecture
:::
The most typical multi-centers in the same city are double centers and triple centers.
Double center in the same city
Simply put, it is to deploy two computer rooms in the same city. As shown in the figure below, IDC-1 and IDC-2. The two computer rooms are connected by high-speed optical fiber. Some of its key features are:
(1) In the same city, the distance is more than 50km. Why does it need to be above 50km? As far as the construction of the computer room is concerned, there is nothing wrong with it, and it can be built at a distance of 5km. But we do dual computer rooms for high availability disaster recovery or backup. A simple example, if the distance is too close, it is likely to belong to a district. If there is a power outage, it is likely to be a power outage in one area. In this way, the two computer rooms are unavailable. (2) Optical fiber interconnection (3) Network delay in the computer room <2ms
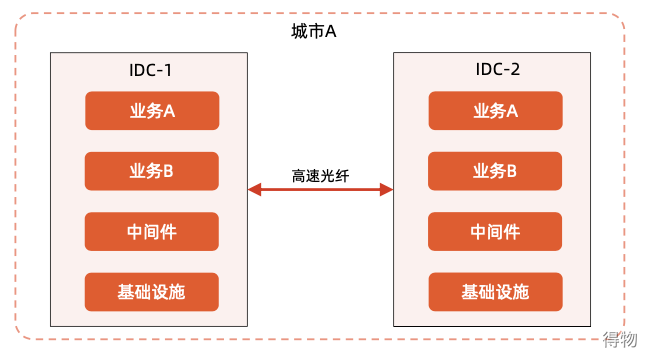
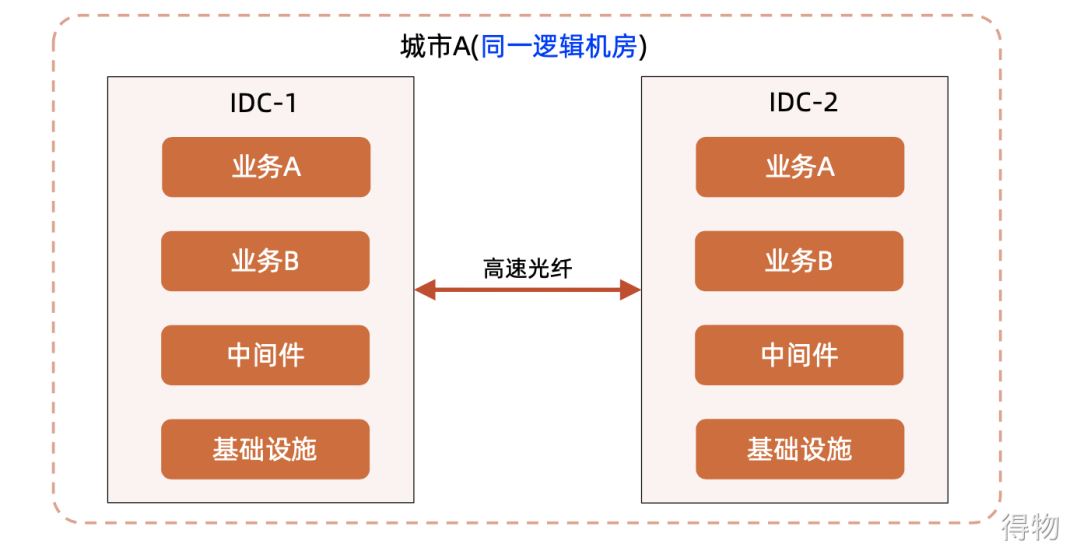
The essence of the architecture of the dual centers in the same city is that the dual centers in the same city can be regarded as a logical computer room. That is, the nodes on the same cluster are deployed in two physical computer rooms. This can deal with disasters at the computer room level. As shown below
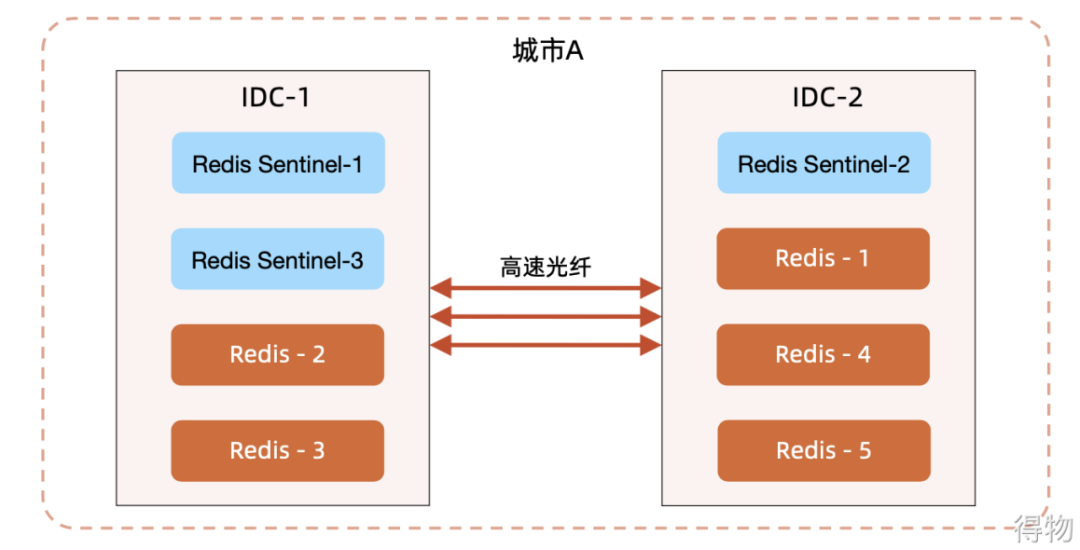
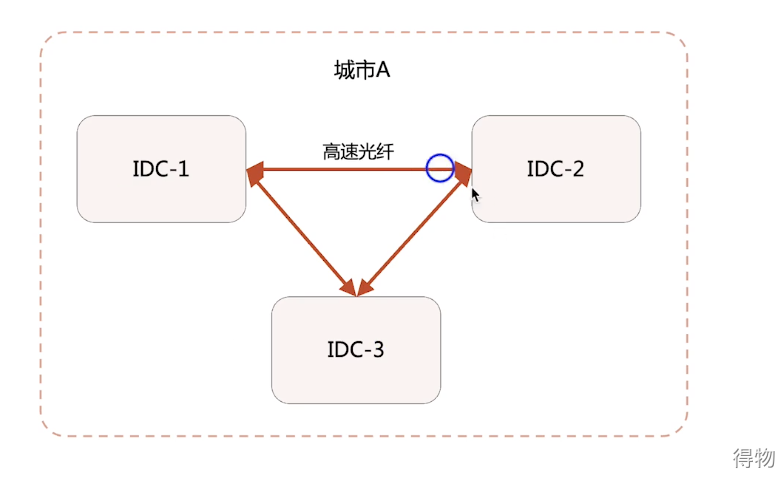
It should be noted that if the same cluster is deployed in two data centers, multiple optical fiber lines are generally used, otherwise split brains are prone to occur. In addition, there are some special cases, as shown in the figure below, it can be found that if IDC-2 is down, IDC-1 can serve normally. But if the entire IDC-1 hangs up, the Redis cluster of DIC-2 is unavailable. This is because the sentinel node cannot complete the election, and the design must be considered in terms of architecture. Of course, there is also a way, which is to deploy a node in idc-3 and only deploy the sentinel cluster to avoid this problem. In IDC-3, there is no need to build a complete computer room, and only some services related to decision-making and elections need to be deployed. There is a certain cost, but the overall cost is still relatively low.
Three Centers in the same city
Compared with the double center in the same city, the three center is to deploy three computer rooms in the same city, and connect each other through high-speed optical fiber. Three centers, each center has the same positioning and responsibilities. For example, if the business needs to be deployed, all three will be deployed. In fact, very few companies adopt this architecture. The main reason is that the cost of the three centers in the same city is relatively high, but the high availability has not been improved much. If a city-level disaster occurs, such as an earthquake, typhoon, etc., the three computer rooms will be affected. Therefore, if you want to build three computer rooms, you usually have two centers in the same city, and then deploy the other computer room to other cities.
The figure below is just a schematic diagram, and the actual architecture is much more complicated.
::: hljs-center
2. Cross-city multi-center architecture
:::
Cross-city multi-centers are also divided into cross-city double centers and cross-city three or four centers. See the figure below. The structure of the cross-city dual center is similar to the structure of the same city dual center. The difference is that the city where the computer room is located is different. Some key features of the cross-city dual center are: different cities, fiber optic interconnection.
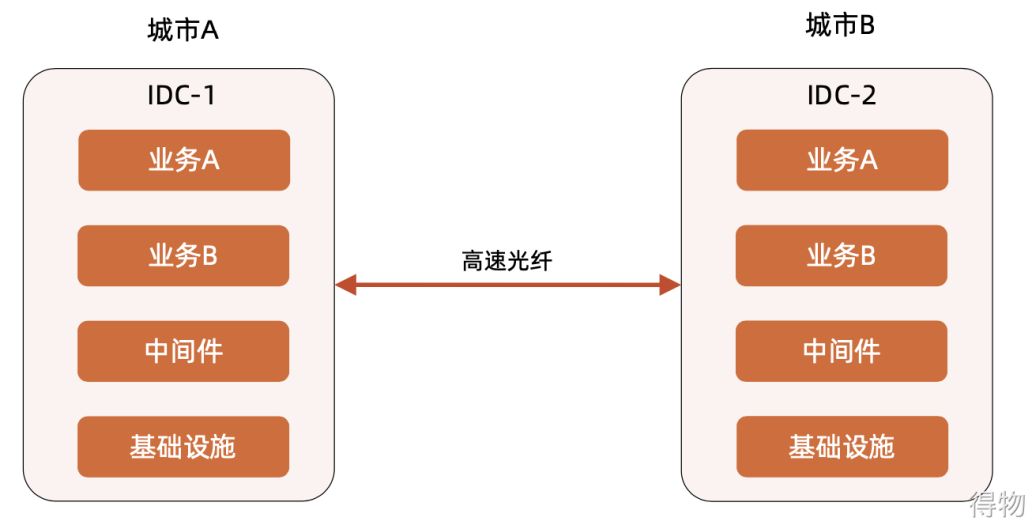
The main application scenarios of cross-city dual centers are:
- Carry out city-level disaster preparedness
- User division, for example, two cities are deployed far away, city A is in Beijing, city B is in Shenzhen, then users in the south can connect to the computer room in Shenzhen, and users in the north can connect to the computer room in Beijing;
- Live more in different places
Not all cross-city multi-center architectures can meet these application scenarios. Different cross-city dual-center architectures have different application scenarios. From the perspective of the distance of the city, it is divided into the scene of the nearby city and the scene of the far city.
Cross-city double center - neighboring cities
The key point of this architecture is to choose two similar cities, such as Shanghai-Hangzhou, Beijing-Tianjin, and Guangdong-Shenzhen. The delay of the computer room should be <10ms, which can be used as the same logical computer room.
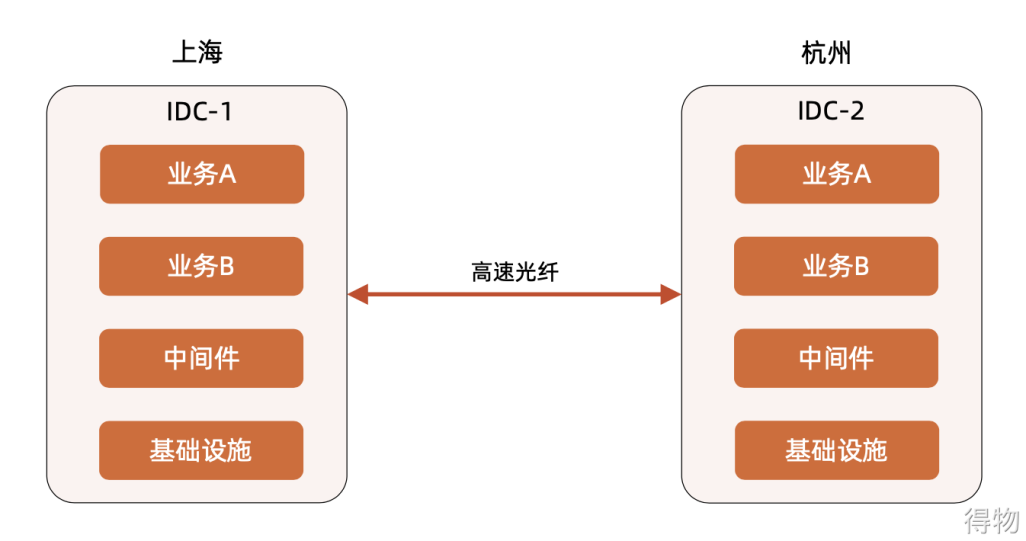
Application scenario:
- Avoid city-level disasters, but not regional ones
- Do multi-active in different places, but not user partition. The distance is relatively short, and user partition access is meaningless
Cross-city double center - remote city
The key feature of the remote city architecture model is to select two distant cities; the delay of the computer room is >30ms, and cannot be regarded as the same logical computer room;
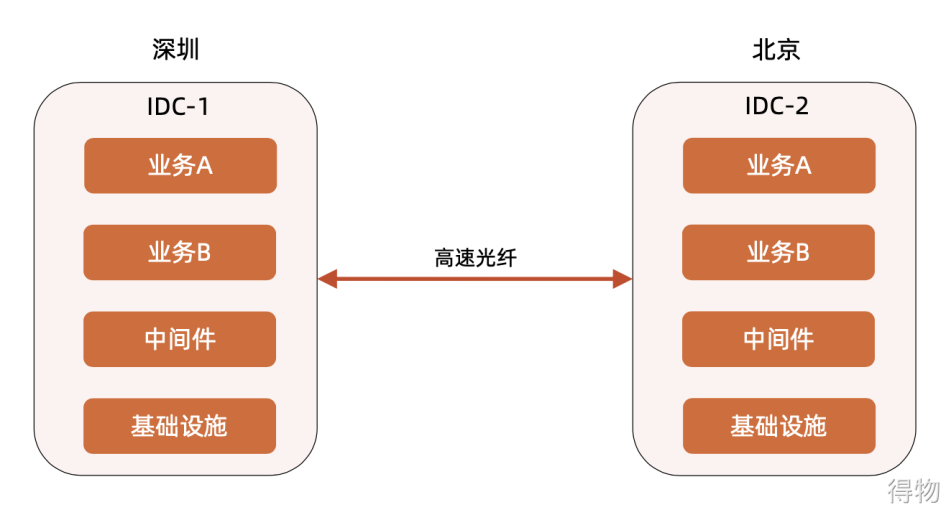
Application Scenario
- Avoiding Disasters at the City and Regional Levels
- Adapt to the multi-active architecture in different places
- Can do partition architecture
Cross-city multi-center
The general application scenarios of cross-city multi-centers are user partitioning, nearby access, and multi-activity in different places.
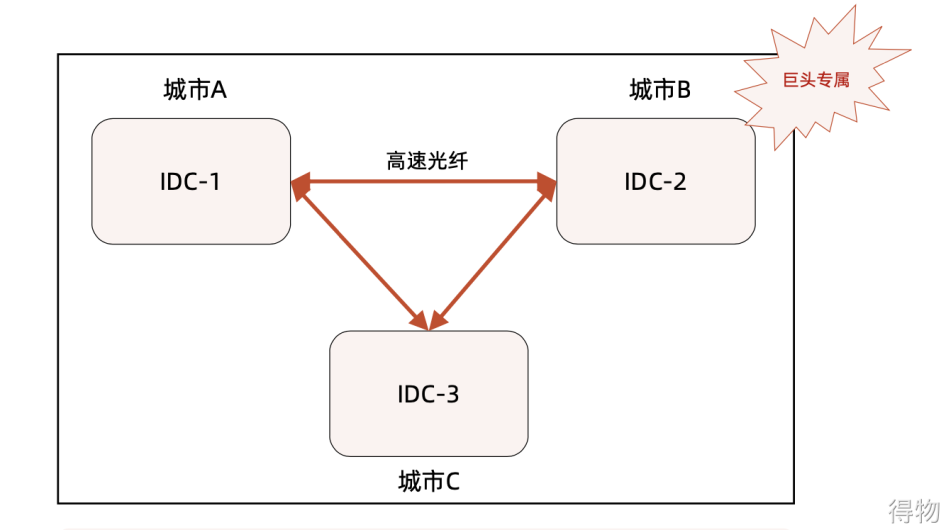
It can be understood in combination with OceanBase's official recommended architecture. As shown in the figure below, the deployment mode of two near (delay 10ms) and one far (delay 30~50ms) can cope with city-level faults, and the reliability is the highest; however, the cost is also the highest. Why 2 near and 1 far? In fact, this is related to the technical implementation of oceanBase itself. In order to ensure consistency, the bottom layer is guaranteed by continuous communication and voting through the proxy protocol. It is necessary to ensure the performance of communication between services. One far is to guarantee against city-level failures.
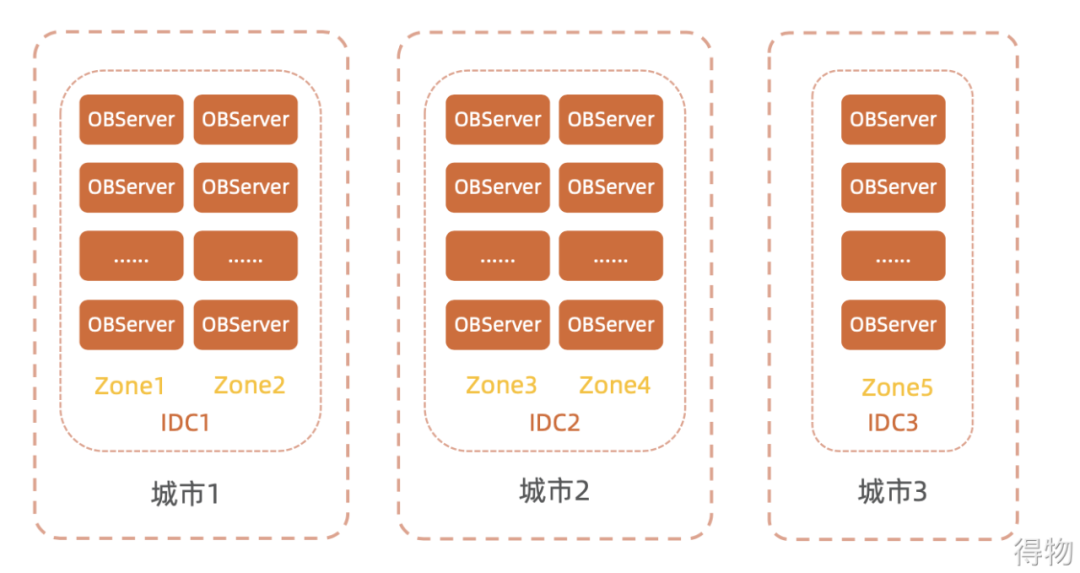
::: hljs-center
3. Multinational Data Center Architecture
:::
Multinational Data Center
The basic characteristics of multinational data centers: (1) Global deployment (2) Compliance and supervision, data regulations in different regions are different, such as user privacy information (3) Regional user partitions (4) Cannot do more than one place live. One reason is the time delay, and the other is compliance and supervision. The compliance and supervision of data privacy protection in different regions are different, and there is no way to do more work in different places.
You can take a look at the multinational data centers of Google and Facebook. The picture above is Google’s and the picture below is Facebook’s.
Multinational data centers. Mainly deployed in North America, Europe, and Asia.
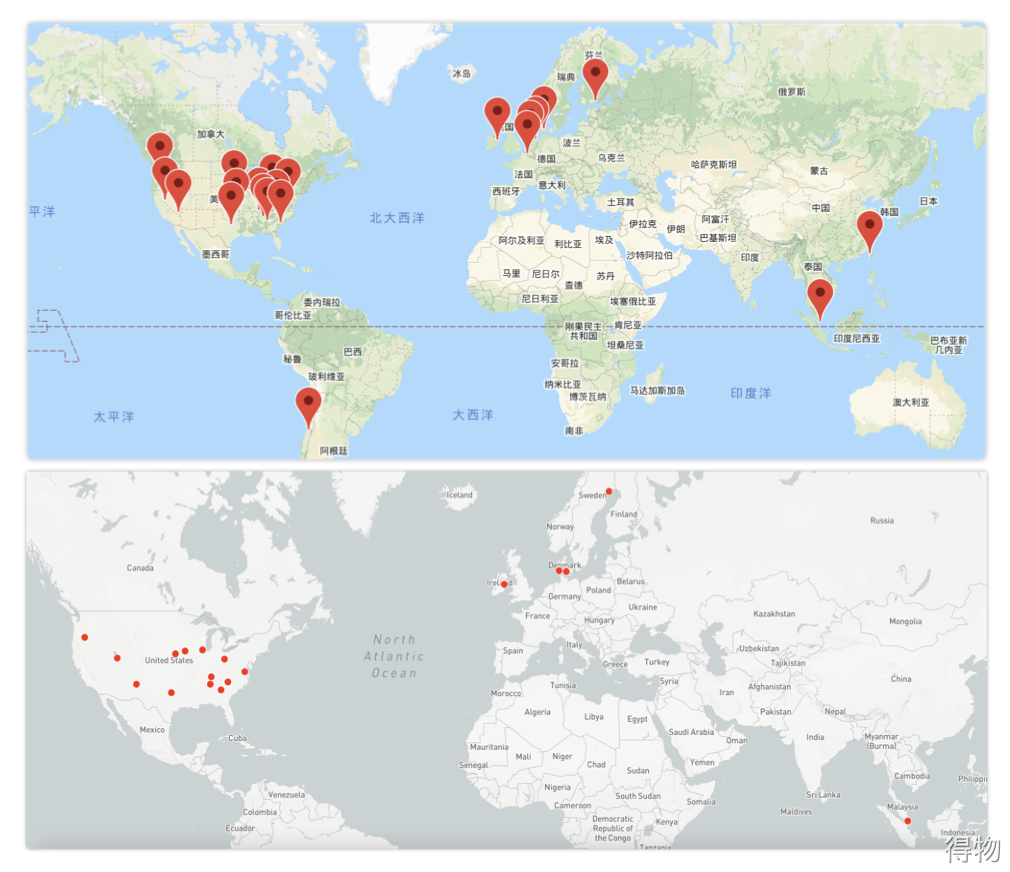
::: hljs-center
4. Comparison of five architectures
:::
Mainly look at the differences between several architectures from the perspective of application scenarios
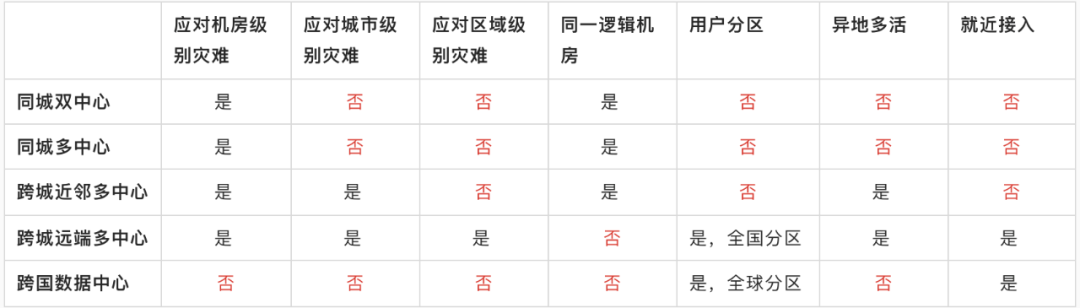
Common cold standby, dual-machine hot standby, intra-city active-active, remote active-active, and remote multi-active are basically the application of the above architectural models based on their own business scenarios and development stages. Let's talk about the centralized mode of multiple activities in different places.
::: hljs-center
Three modes of living in different places
:::
The implementation of off-site multi-active can be summarized as three major models, business-customized off-site multi-active, business general off-site multi-active, and business storage off-site multi-active.
::: hljs-center
1. Business customized multi-activity in different places
:::
To put it simply, the business-customized remote multi-active is to sort according to the priority of the business, and give priority to ensuring the core business remote multi-active. Then, based on the process and data of the core business, design a customized remote multi-active architecture. However, the solution made by business A cannot be directly applied to business B. For example, the active-active e-commerce business cannot be used in social business, and the architecture solution is not universal. As shown in the diagram below:
- A business is realized through database + message queue synchronization,
- Business B realizes multi-active in different places through database + algorithm.
- The implementation methods of the two services are determined according to their own business scenarios.
The advantage of this mode is that there are no strong requirements for infrastructure, such as computer room deployment, storage systems, and latency. It is generally deployed in two distant cities and can support regional-level fault handling. The disadvantages are also obvious, it is not universal, and each business needs to be done independently in different places, and the business needs to be transformed. Difficult to expand, if there is a major change in the core business, the remote multi-active solution needs to be redesigned.
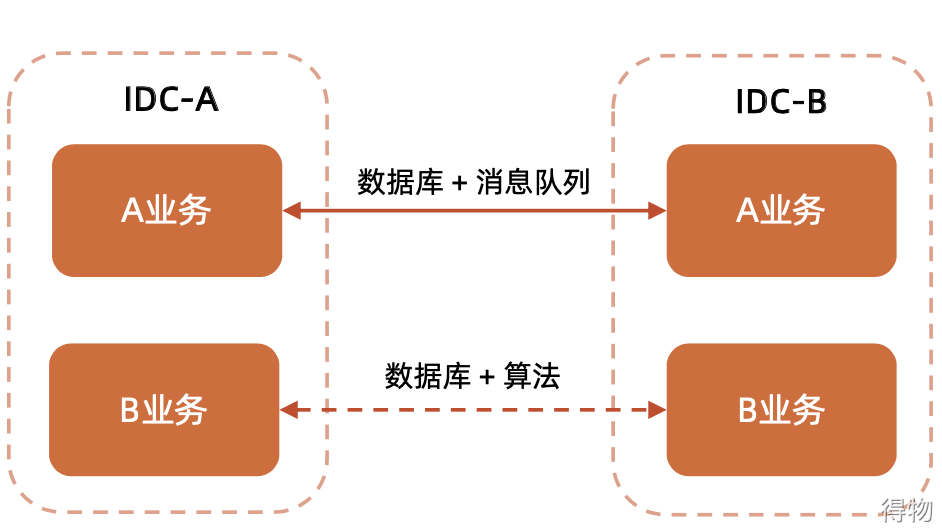
::: hljs-center
2. Multi-active in different places for general purpose business
:::
This method generally supports multiple activities in different places through supporting services. Compared with the business-customized architecture, there is generally no need to select certain businesses according to priority to achieve multi-active in different places. You only need to judge whether the business can be multi-active in different places. Of course, there may be stages or gray-scale processes when the business is actually implemented, and Not in one step. Pros and cons of this architecture:
-
advantage
a. There are no strong requirements for hardware infrastructure, such as computer room deployment, storage system, delay, etc., and are generally deployed in two distant cities, which can support regional-level fault handling.
b. The business basically does not need to be transformed or undergoes minor transformation. It is only necessary to judge whether the business supports BASE, and if it supports it, it can be multi-active in different places. If it does not support it, it can be deployed at a single point. This also depends on the early design of the business system.
-
shortcoming
a. Complicated supporting services, including traffic scheduling, disaster recovery switching, site building platform, configuration management, etc.
b. There is a global single point of service. Such as inventory, sellers and other related businesses
When the computer room is far away, the RTO is relatively large and may reach the level of minutes. The basic theory of remote multi-active is Base, and the final consistency is reached within a certain period of time. This time range may be longer, and it may reach the minute level.
Diagram 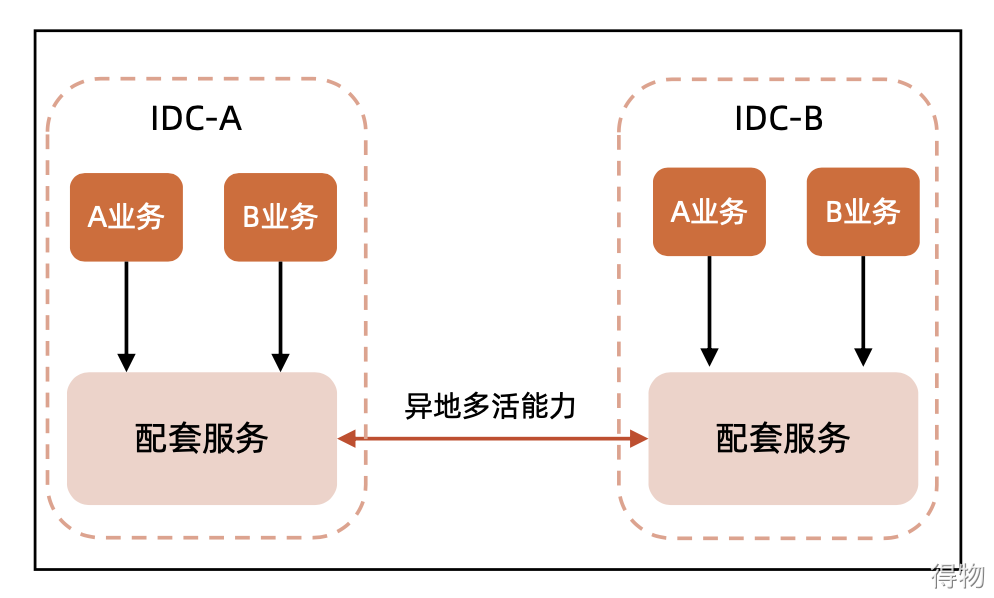 " Case " Taobao's unitized architecture divides the business into many units, and most of the requests for each business can be completed in this unit. Different users are assigned to different units. In addition to the unit there is a center point. Such as inventory information, full product and seller data. Then copy the data to each unit.
" Case " Taobao's unitized architecture divides the business into many units, and most of the requests for each business can be completed in this unit. Different users are assigned to different units. In addition to the unit there is a center point. Such as inventory information, full product and seller data. Then copy the data to each unit.
Schematic diagram 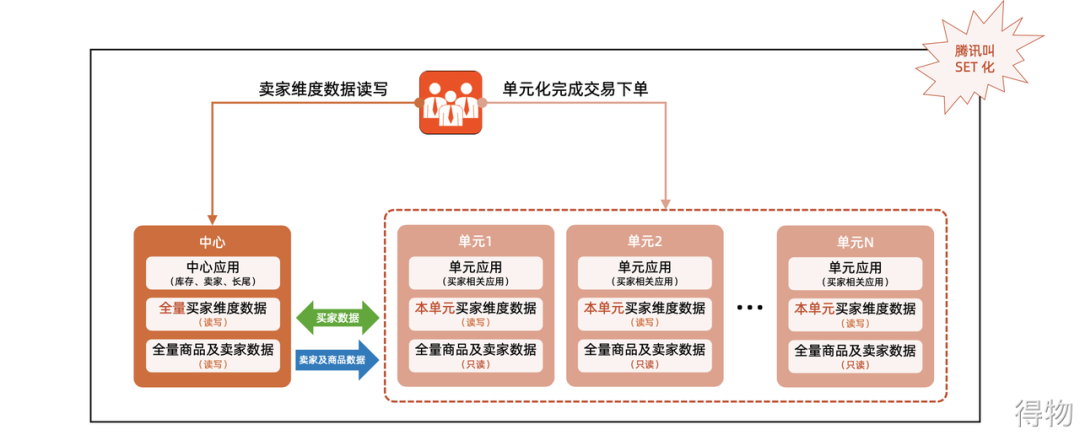 [Unit] A unit (that is, the deployment unit of the unitized application service product layer) refers to a self-contained collection that can complete all business operations. This collection contains all the services required by all businesses, and the units assigned to this unit The data. The unitized architecture is to use the unit as the basic unit of deployment, and deploy multiple units in all computer rooms of the whole station. The number of units in each computer room is not fixed, and any unit deploys all the applications required by the system. A part after some dimension division.
[Unit] A unit (that is, the deployment unit of the unitized application service product layer) refers to a self-contained collection that can complete all business operations. This collection contains all the services required by all businesses, and the units assigned to this unit The data. The unitized architecture is to use the unit as the basic unit of deployment, and deploy multiple units in all computer rooms of the whole station. The number of units in each computer room is not fixed, and any unit deploys all the applications required by the system. A part after some dimension division.
::: hljs-center
3. Store general-purpose off-site multi-active
::: Based on the general business architecture, some businesses cannot meet the base theory, so it is impossible to achieve multiple activities in different places. Is there a way to achieve a multi-active architecture design that is not strongly related to the business? The answer must be yes, from the storage system, using a storage system that already supports consistency, to achieve multi-active storage in different places.
The advantage of the storage general-purpose multi-active remote architecture solution is that it naturally supports multi-active remote operations. Except for switching storage systems, other businesses basically do not need to be modified. There is no need to analyze your own business scenarios and priorities.
The disadvantage is
(1) It needs distributed and consistent storage system support. At present, there are not many such storage systems to choose from, such as zookeeper, etcd, and OceanBase. In fact, zookeeper and etcd are not suitable for storing large amounts of data.
(2) There are strong requirements for the deployment of the computer room. If multi-active in different places is realized, only the neighbor deployment can be used. The distributed consistency framework needs to communicate through the protocol. This requires performance and speed requirements. If the communication performance of the nodes between distributed storage systems is poor, it will lead to the read and write performance of the system. It will be very poor, and it will not meet the business needs. 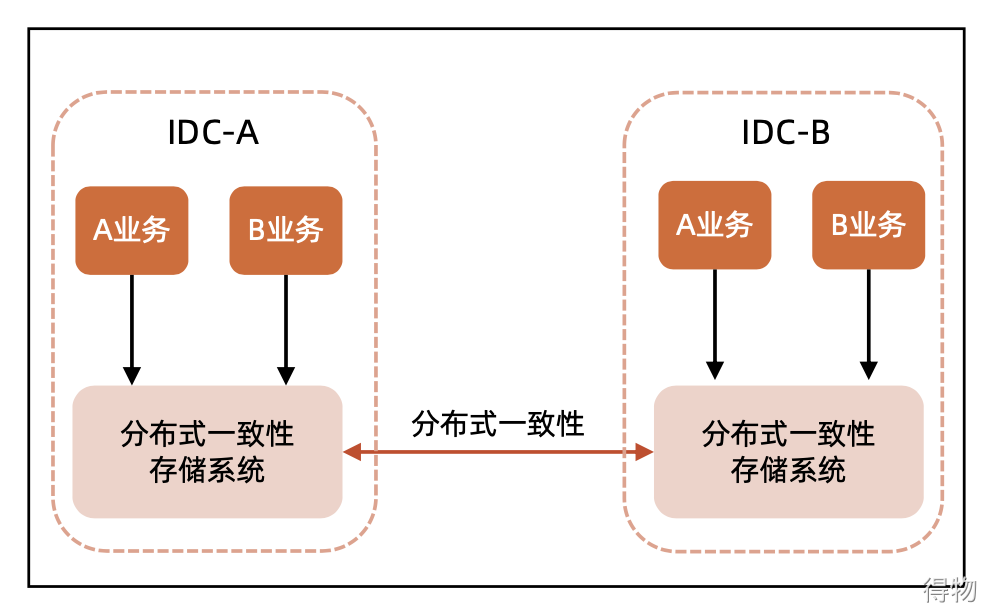 " Case " Ant's OceanBase So far, OceanBase is a typical distributed storage, and it is a distributed and consistent storage system that has really landed. A simple understanding of OceanBase is a distributed consistent storage system based on the Paxos algorithm. [Refer to the official introduction] As shown
" Case " Ant's OceanBase So far, OceanBase is a typical distributed storage, and it is a distributed and consistent storage system that has really landed. A simple understanding of OceanBase is a distributed consistent storage system based on the Paxos algorithm. [Refer to the official introduction] As shown 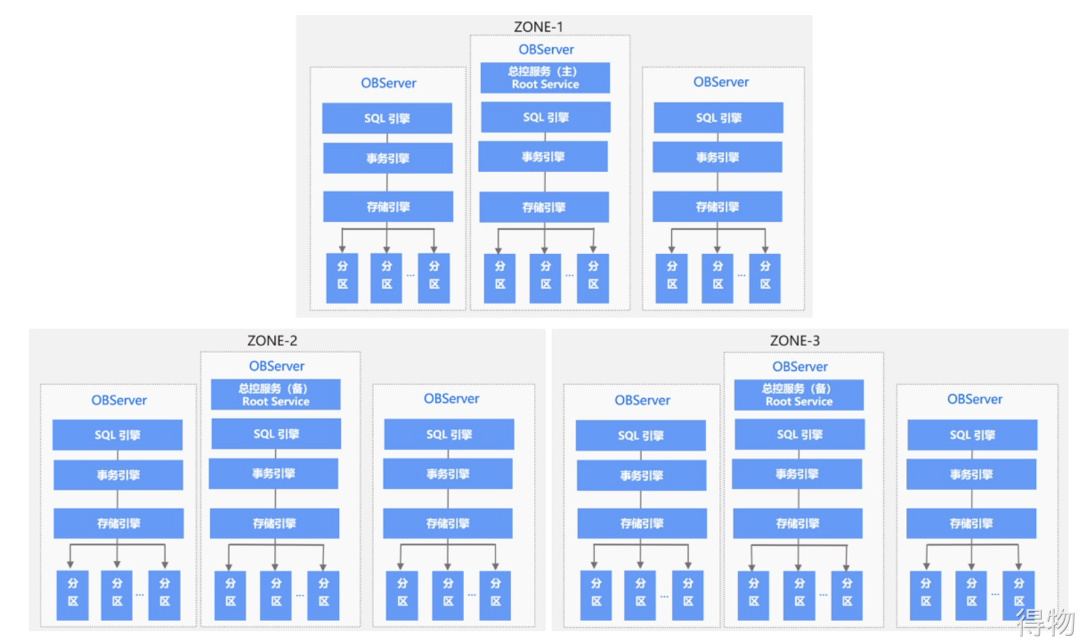 in the above picture, simple understanding:
in the above picture, simple understanding:
(1) Zone is a group of servers in a computer room, including multiple OceanBase database servers (OBServer), which generally distribute multiple copies of data in different Zones, so that a single Zone failure does not affect database services.
(2) Each OBServer includes a SQL engine, a transaction engine, and a storage engine, and serves multiple data partitions. Among them, one OBServer in each Zone will enable the root service at the same time to perform cluster management and server management. , automatic load balancing and other operations.
(3) The SQL engine, transaction engine and storage engine will run on OBServer, and the user's SQL query will be converted into an internal call of the transaction engine and storage engine after being parsed and optimized by the SQL engine.
(4) The OceanBase database also executes strongly consistent distributed transactions, thereby implementing database transaction ACID on distributed clusters. (Reference link: https://zhuanlan.zhihu.com/p/41139701)
Refer to the figure below to understand that the deployment generally requires 2 near and 1 far away. For two cities with similar distances, two zones must be deployed in the computer room of each city, and one zone should be deployed in the farther city.
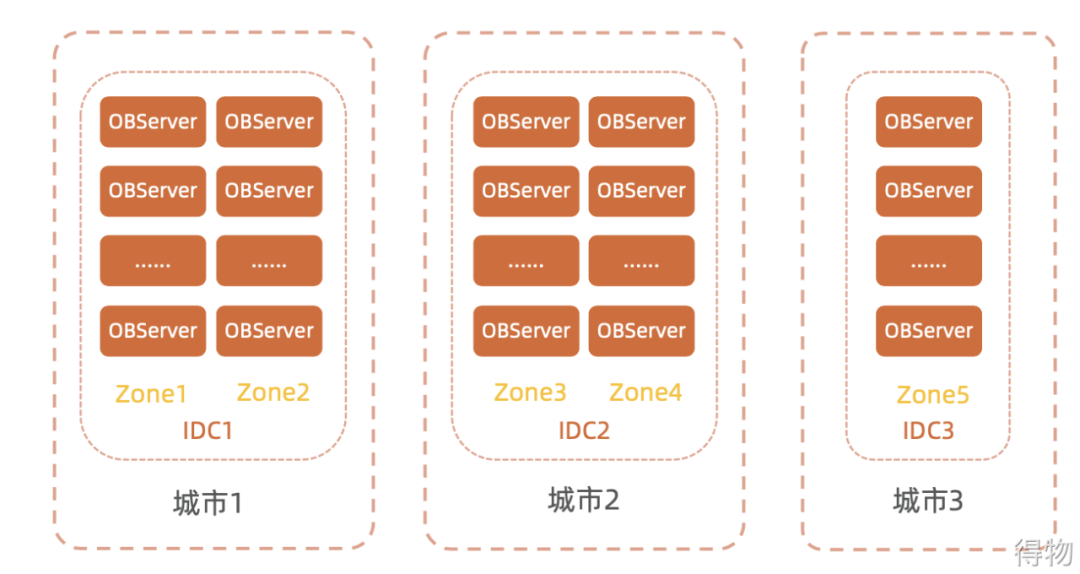 " Case " Ant's LDC architecture combined with Taobao's unitized architecture + OceanBase
" Case " Ant's LDC architecture combined with Taobao's unitized architecture + OceanBase
Schematic diagram as shown 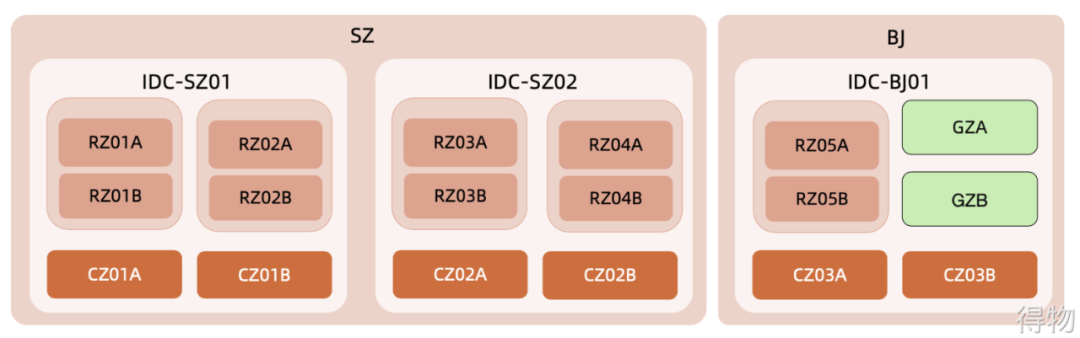
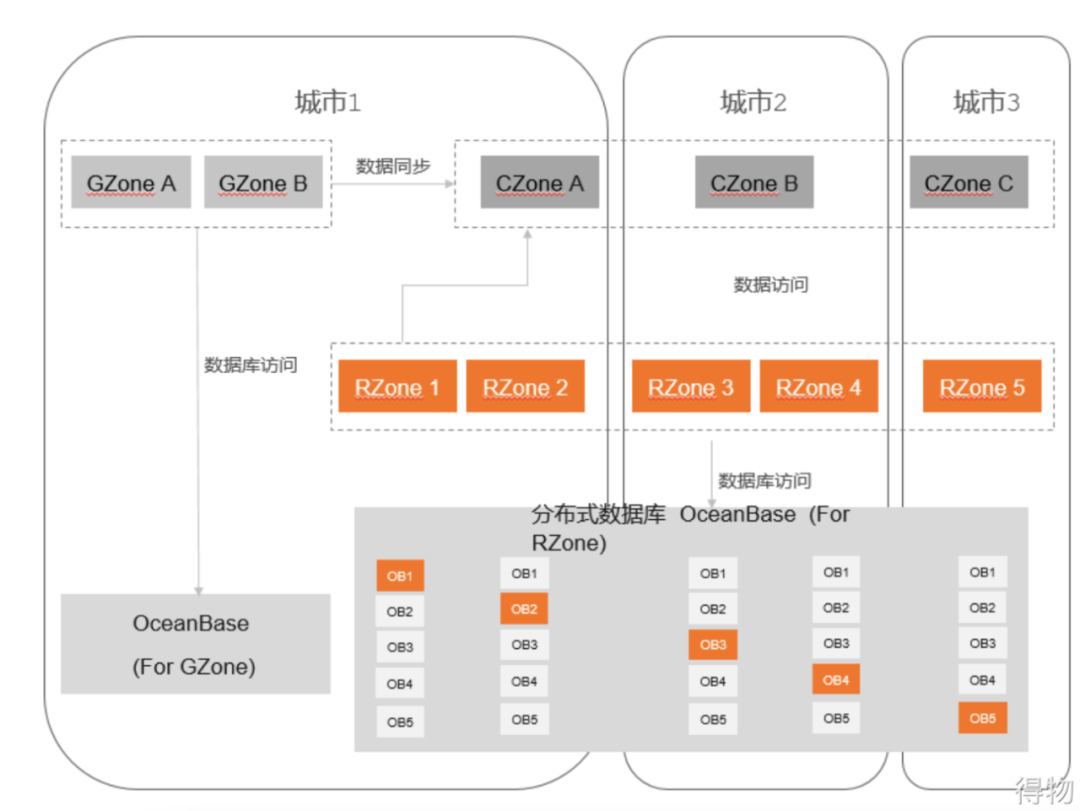 above, easy to understand:
above, easy to understand:
RZone (Region Zone): Deploy key business systems split by user dimension. The core business and data are divided into units, and each unit uses a closed loop as much as possible, has its own data, and can complete all businesses. An availability zone can have multiple RZones.
GZone (Global Zone): Deploy a system that is not split according to the user dimension. There is only one copy globally, which is relied on by RZone to provide indivisible data and services, such as configuration-type services. The database can be shared with RZone, multi-tenant isolation, there is only one group globally, and traffic weight can be configured.
CZone (City Zone): Deploy a system that is not split according to the user dimension, and is frequently accessed by RZone to solve the problem of cross-domain communication delay. It is specially designed to solve the problem of off-site delay, and is suitable for businesses that read more and write less and cannot be split. Units deployed in units of cities, generally one set of applications and data per city, are read-only copies of GZone.
You can take a look at the case introduction of Alipay by yourself. (Alipay case link: https://www.sohu.com/a/406634738_99940985)
::: hljs-center
4. Comparison of three modes
:::
From the perspective of application scenarios and implementation costs, the following three modes have their own advantages and disadvantages 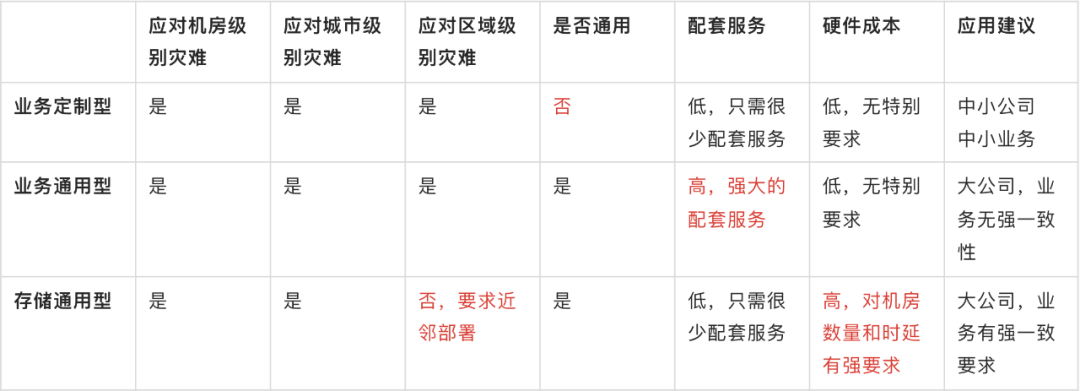 ::: hljs-center
::: hljs-center
Key technology of remote multi-active architecture (general purpose)
:::
The solutions commonly used by large manufacturers are general-purpose technical solutions. Let's focus on some key realizations in the architecture of business versatility.
::: hljs-center
1. Traffic Scheduling
:::
It is mainly responsible for distributing the user's request traffic to the corresponding unit, such as the ant's Spanner. Spanner is the seven-layer network agent of Ant Financial, which carries all the business traffic of Ant Financial, including terminal access of Alipay App, Web, merchants, etc.
As shown in the figure below, the user enters through the network entrance of Ant Financial, and accesses through multi-protocol to LVS and Spanner. Spanner acts as a unified seven-layer gateway to distribute requests to subsequent applications. There are a lot of business logic and protocol support on Spanner, such as TLS 1.3, QUIC, HTTP, and protocols developed by Ant. All Ant's businesses, including Alipay wallet and other pages, come in through this entrance. 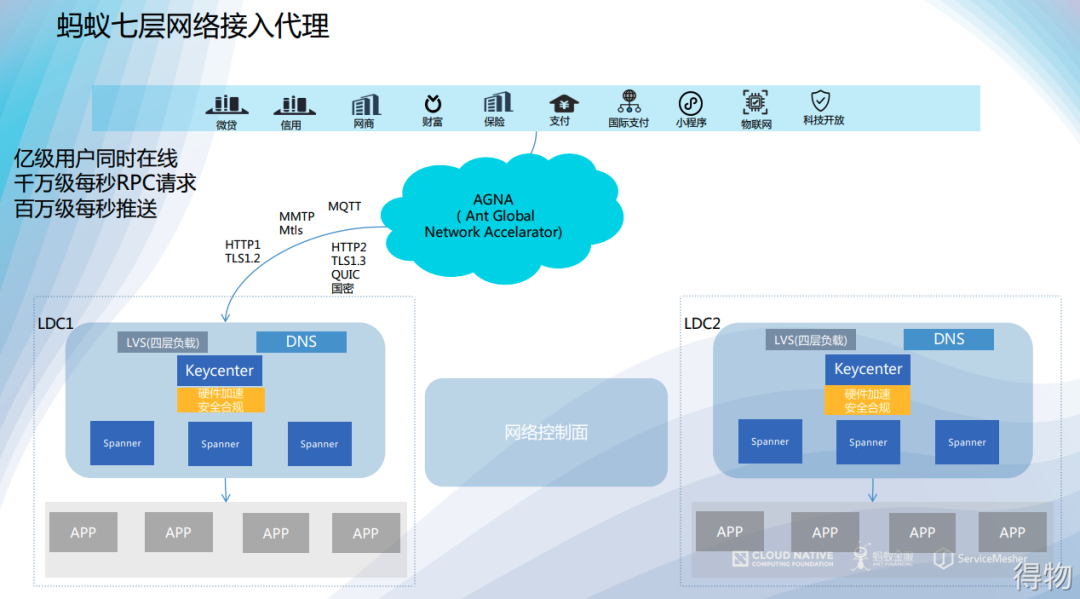 The following figure shows the traffic scheduling scenario of spanner in the three-site five-center architecture. It can also be found that it can be realized through traffic scheduling:
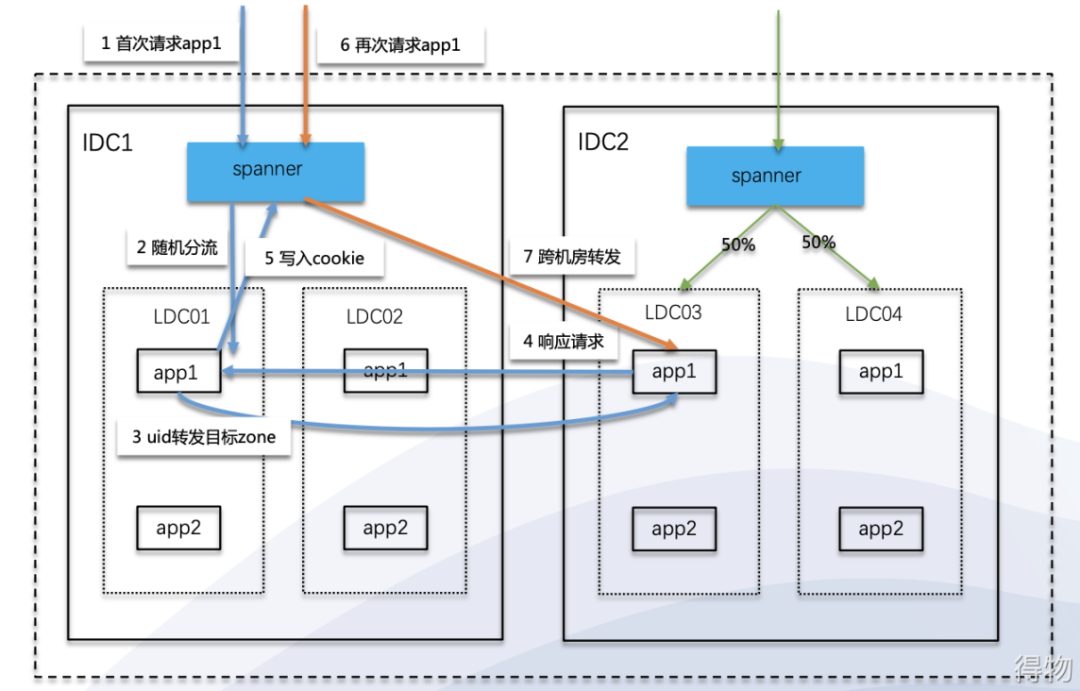
The following figure shows the traffic scheduling scenario of spanner in the three-site five-center architecture. It can also be found that it can be realized through traffic scheduling:
-
Zone random routing in the computer room
-
Cookie zone forwarding
-
disaster recovery
-
flexible scheduling
-
pressure test
-
Grayscale, blue-green release
 :::hljs-center
:::hljs-center
2. LDC routing
::: The routing center under the remote multi-active architecture is generally divided into three layers. The first layer is to judge which computer room or unit to visit. The second layer is to determine which unit the request should go to when calling between services. The third layer is to access the data layer, and the bottom layer of the last layer decides which DB to access.
Combined with the architecture of ants, look at the routing situation
[Ingress Traffic Routing]
箭头1:对于应该在本 IDC 处理的请求,就直接映射到对应的 RZ 即可;
箭头2:不在本 IDC 处理的请求,Spanner 可以转发至其他 IDC 的 Spanner。
【Service Routing】
RPC调用、MQ的一些场景,有些场景来说,A 用户的一个请求可能关联了对 B 用户数据的访问,比如 A 转账给 B,A 扣 完钱后要调用账务系统去增加 B 的余额。这时候就涉及到:
箭头3:跳转到其他 IDC 的 RZone;
箭头4:跳转到本 IDC 的其他 RZone。
【Data Routing】
Which database RZ accesses is configurable, corresponding to arrow 5 in the figure.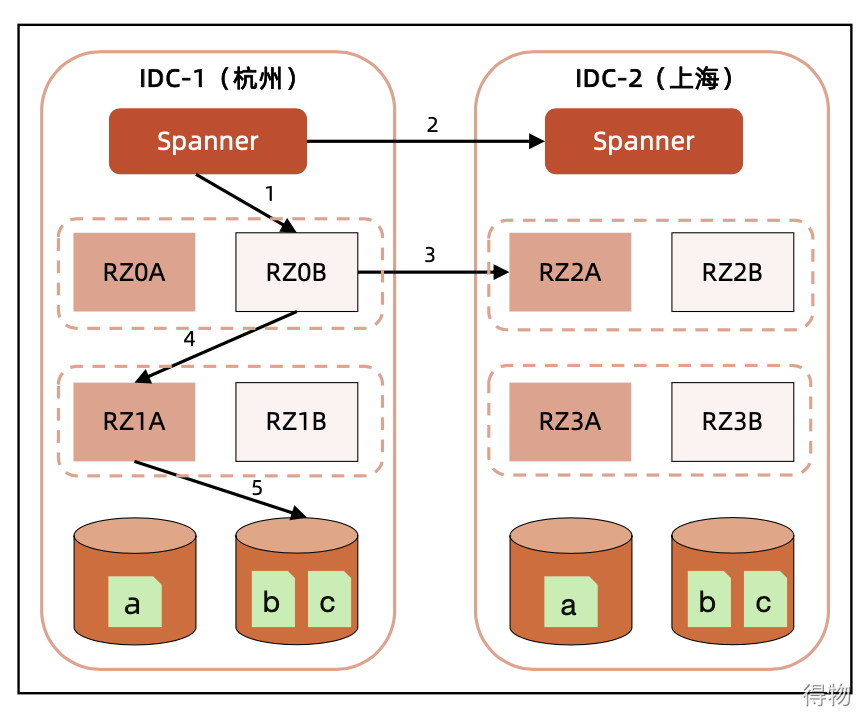
3. DRC
(Data Replication Center): The data replication center mainly supports real-time synchronization of heterogeneous databases and subscription services for data record changes. Provide support for scenarios such as cross-domain real-time synchronization of services, real-time incremental distribution, remote active-active, two-way data synchronization, data inspection, and redis invaded. You can refer to otter's architecture design.
Synchronization of a single computer room 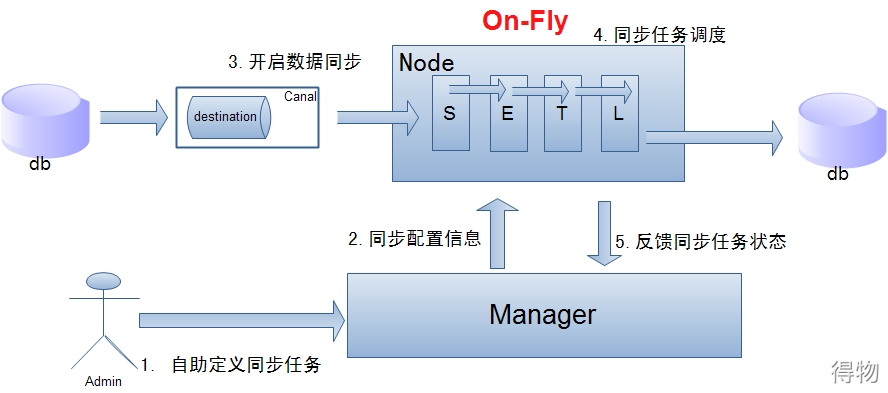 is shown in the figure above:
is shown in the figure above:
Data on-Fly, as far as possible without landing, faster data synchronization. (Enable the node loadBalancer algorithm, if the Node node S+ETL falls on different Nodes, the data will have a network transmission process). Node nodes can have failover / loadBalancer.
Remote multi-active synchronization 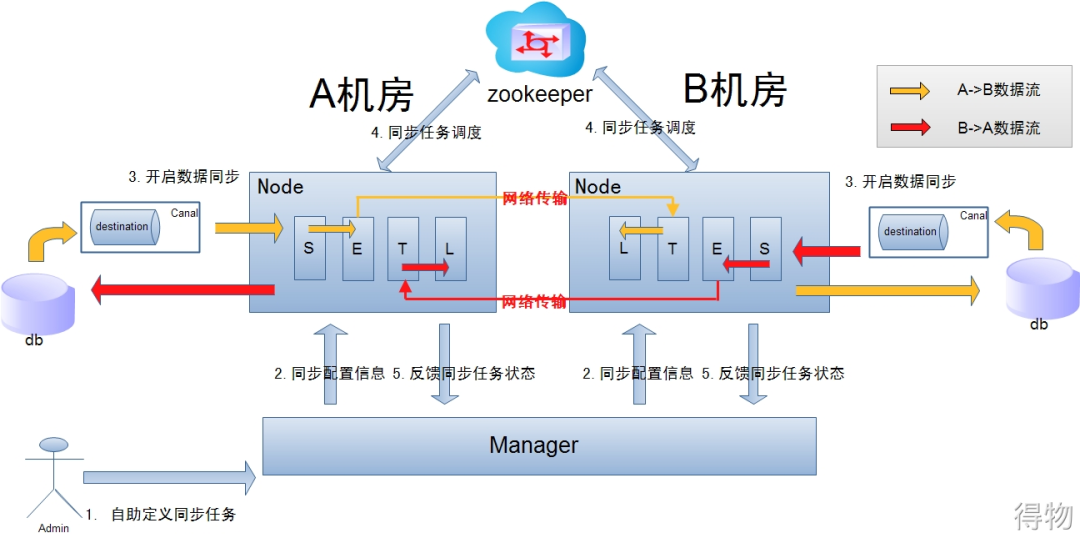 is shown in the figure above:
is shown in the figure above:
The data involves network transmission, and the S/E/T/L stages will be scattered on 2 or more Node nodes, and multiple Nodes will work together through zookeeper (usually Select and Extract are in a node in the computer room, Transform /Load falls on Node in another computer room).
Node nodes can have failover / loadBalancer. (Node nodes in each computer room can be clusters, one or more machines).
::: hljs-center
4. DAL
::: DAL is a proxy-type database middleware that supports the mysql protocol. In the multi-active project, DAL is obliged to play the role of the last line of defense to protect the correctness of data.
For some applications that require high consistency, a strong consistent solution is generally provided, such as the Global Zone in the architecture of Ele.me. The Global Zone is a read-write separation mechanism across computer rooms, and all write operations are directed Go to a Master computer room to ensure consistency. Read operations can be performed in the Slave library of each computer room, or can be bound to the Master computer room. All of this is done based on the database access layer (DAL), and the business is basically unaware.
::: hljs-center
5. Configuration Center
::: Responsible for Zone configuration and disaster recovery switching, such as the business scope of RZone, which databases the Zone accesses, etc.
::: hljs-center
6. Publishing platform
::: The release of the service multi-computer room. Based on traffic scheduling, the blue-green release and grayscale release of the Zone are completed.
::: hljs-center
7. Website building platform
::: Quickly create a complete unit, including machine construction, infrastructure construction, service deployment, etc., which are basically implemented based on container technology.
::: hljs-center
The method of remote multi-active architecture design
:::
In the actual landing process, there are still some general architecture design methods for reference.
::: hljs-center
1. Live more in different places - 3 principles
::: Perfection is the enemy of excellence, don't pursue perfection too much. When landing in a different place and living more, generally there are 3 principles to be followed
(1) Only the core business is guaranteed. The data characteristics of different businesses are different, and it is impossible to achieve multi-active in different places
(2) In principle, only final consistency can be achieved. There must be a time window for replication, abandoning the idea of real-time consistency. You can understand [PACELC theory]
(3) Only the vast majority of users can be guaranteed. It cannot affect 99.99% of users for the sake of 0.01% of users.
::: hljs-center
2. Live more in different places - 4 steps
::: (1) Business rating
将业务按照某个维度进行优先级排序,有限保证Top3业务异地多活。一般定级的方向,可以从访问量、核心场景、收入来源看。
Visits: Login>Register>Change Password Core Scenario: Transaction>Community Income Source: Order>Search>Edit
(2) Data classification
分析TOP3中的每个业务的关键数据特点,将数据分类。
-
Data Modification
Quantity and frequency of data modification, including addition, deletion, and modification. -
Consistency
Data consistency requirements, such as: strong consistency (balance, inventory), eventual consistency (dynamic, interest). -
Uniqueness Requirements for uniqueness
of data, for example: globally unique (user ID), repeatable (nickname) -
Lossability
Whether the data can be lost, such as non-losable (account balance, order), can be lost (tocken, session)
- Recoverability
Is the data recoverable, e.g. user recovery, system-provided recovery (password retrieval), internal recovery (e.g. editing and operational retransmission)
(3) Data synchronization
针对不同的数据分类设计不同的数据同步方式。
(4) Exception handling
针对极端异常的情况,考虑如何处理,可以是技术手段,也可以是非技术手段。
- business compatible
Having a bad experience is better than having no experience at all. For example, the data is inconsistent for a short time, and the data cannot be obtained temporarily.
- Compensation afterwards
A small number of user losses can be resolved with money. Appropriate compensation coupons.
- Manual repair Manual revision of data to achieve final consistency.
::: hljs-center
Remote active-active practice
::: ::: hljs-center
1 Overview
::: The following figure is a business diagram of the current active-active architecture of Dewu, including routing center, DRC, DAL, configuration center and other infrastructure. 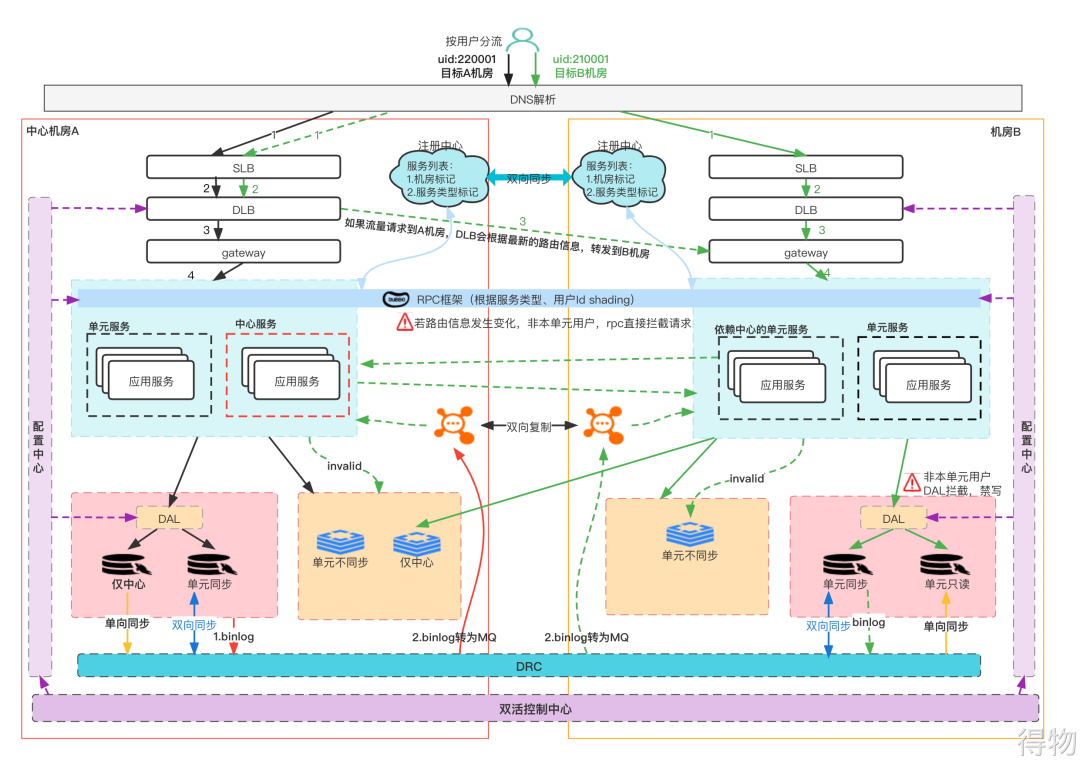 As shown in the figure, after the user initiates a request in the app, the client will first judge which SLB the user should access based on the cached information, and then the SLB will forward the request to the DLB, and the DLB will judge the user based on the latest routing rules Whether it belongs to this unit, if it continues to flow in this unit, if not, forward the request to the corresponding unit. As shown in the green request in the figure, the user's actual rules should be routed to computer room B. After the actual request reaches computer room A, the request will also be forwarded to computer room B at the DLB layer. When the application service is registered, it will mark its own address and service type. In order to perform routing when calling through RPC services.
As shown in the figure, after the user initiates a request in the app, the client will first judge which SLB the user should access based on the cached information, and then the SLB will forward the request to the DLB, and the DLB will judge the user based on the latest routing rules Whether it belongs to this unit, if it continues to flow in this unit, if not, forward the request to the corresponding unit. As shown in the green request in the figure, the user's actual rules should be routed to computer room B. After the actual request reaches computer room A, the request will also be forwarded to computer room B at the DLB layer. When the application service is registered, it will mark its own address and service type. In order to perform routing when calling through RPC services.
In the process of the implementation of dual-active in different places, I will focus on a few points that need to be paid attention to.
::: hljs-center
2. Key modules
:::
data splitting
From a business perspective, the most important thing is data splitting. Each unit has some user data, and the user completes all behavior operations in this unit as much as possible. For data in the non-user dimension, it is deployed in the central unit (computer room), and one-way synchronization is performed to the unit computer room. For disaster recovery, data in the user dimension will be synchronized bidirectionally between the unit computer room and the central computer room.
Data Architecture Diagram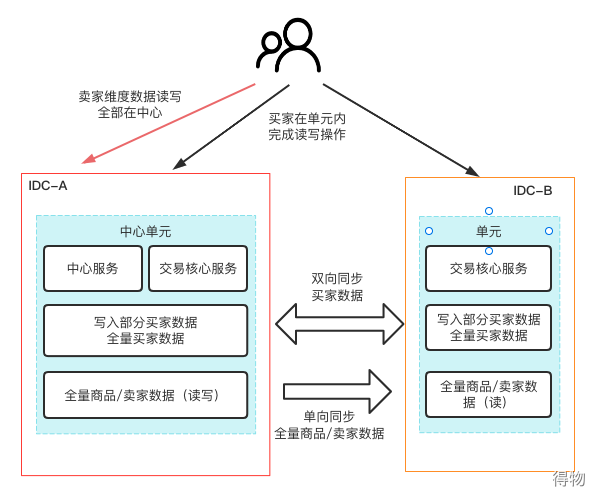
data synchronization
According to the splitting rules of the business, different users will write the data in the unit mode in different units. There is bi-directional synchronization between the unit and the hub. The other is the data in the central mode. This part of the data is written in the center and fully synchronized to the unit. May be accessed in unit. If the current library has physical tables in unit mode and physical tables in central mode, it is not recommended to mix them together, and it is better to split them.
Unitized mode: Both sides will write, and two-way synchronization will ensure that both sides have full amount of data. It is guaranteed that after traffic switching, user access data will not be affected. 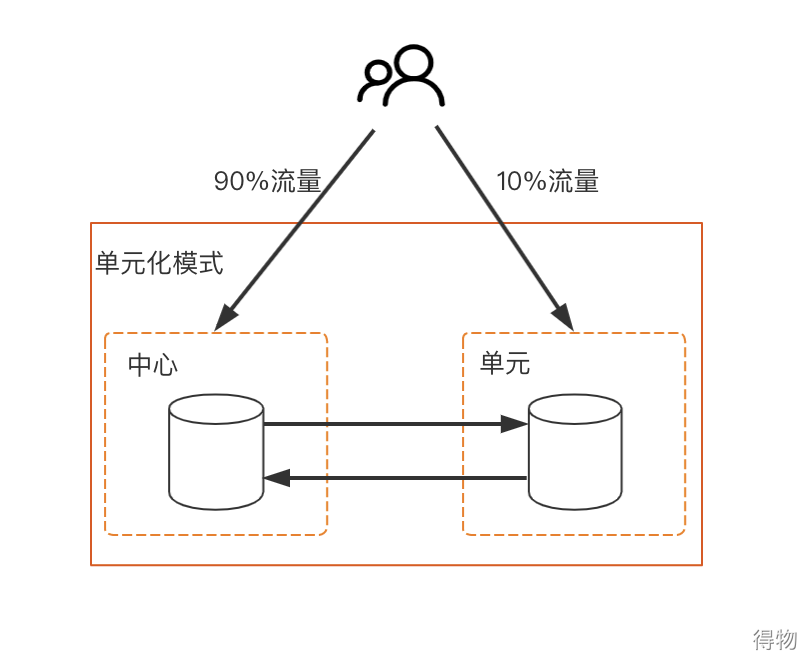 ::: hljs-center
::: hljs-center
One-way replication mode: only write in the center, fully synchronize to the unit, and belong to the unit read-only.
::: 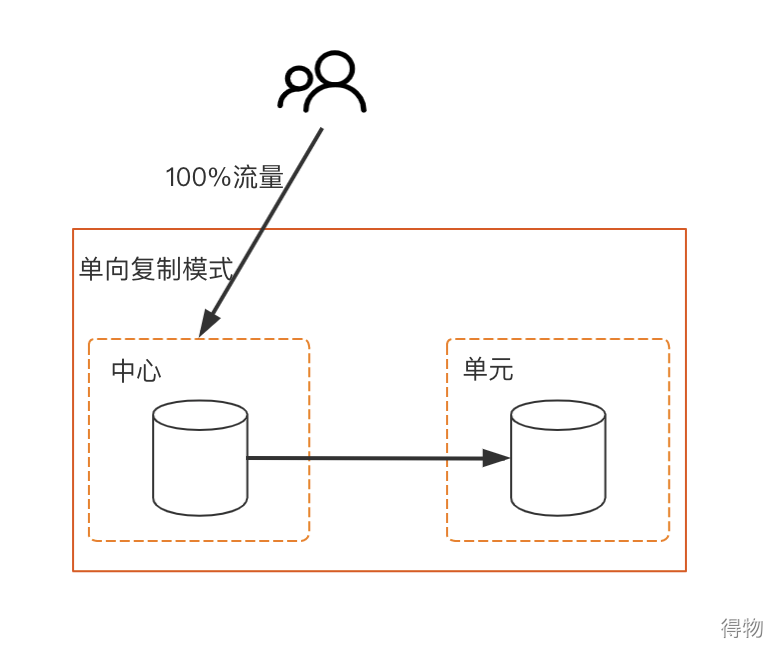 There is also one that is only deployed in the center, such as inventory data, which has strong consistency requirements and is only deployed in the center. Data synchronization is done through DRC.
There is also one that is only deployed in the center, such as inventory data, which has strong consistency requirements and is only deployed in the center. Data synchronization is done through DRC.
RPC service framework
Mainly through the rpc framework, developers do not need to care about the details of calling services. The provider registers its own service to the registration center, and the consumer pulls the service from the registration center and makes a consumption call. Inside the rpc framework, routing policies are cached. You can directly filter according to the rules when the consumer obtains the service. Make calls between services easier. Moreover, the flexibility of routing scheduling is also improved. For example, the nearest call in the computer room, unitized routing call, etc. This is also a Layer 2 route in the above LDC route.
General unitization rules:
(1)哪些用户属于哪个单元
(2)哪些应用属于单元
However, in actual applications, there are still more complex scenarios. From the perspective of application scenarios, there are currently three main types: ordinary services, unit services, and central services.
The service in [Normal Mode] is the service without unit transformation, and there is no concept of unit. The call between services is the nearest call, that is, the unit is called first. If the unit does not have it, it will be called from the center. The call of the center to the common service is also a direct call to the common service of the center.
The service of [unit mode] is a unitized routing service, which will route requests to the correct unit according to the routing key (user ID).
[Center Mode] service, although it will be registered in the registration center of both the center and the unit, the request will only be routed to the center in the end.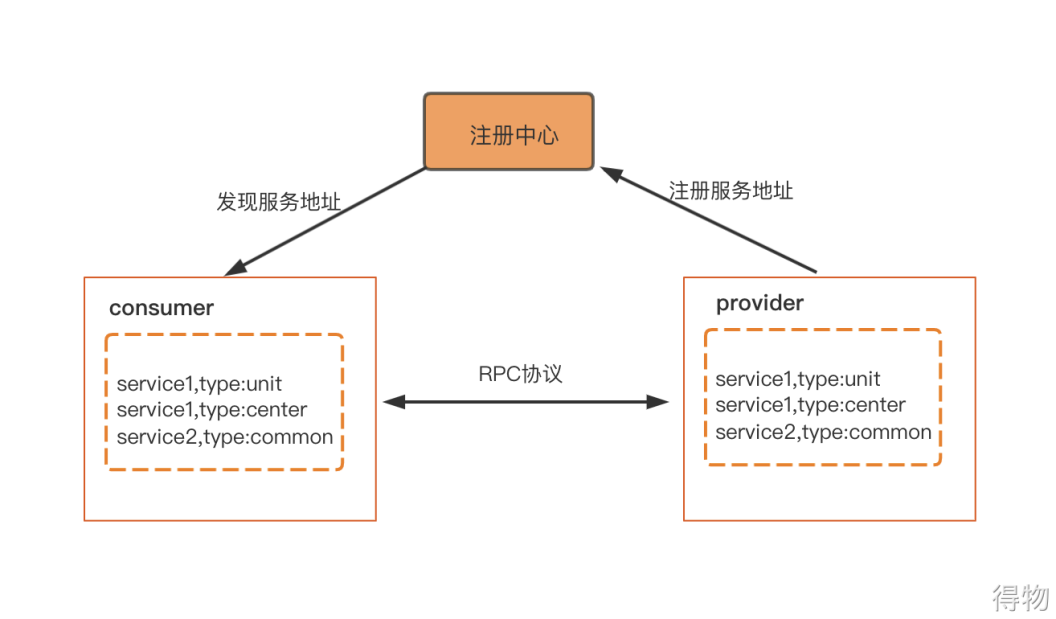
cache failure
After active-active is implemented, the logic of cache invalidation will also change to some extent. For most applications, the original cache invalidation logic is: the application initiates a data update operation, first updates the data in the DB, and then performs cache invalidation processing. The next time there is a request, the data is loaded from the DB to the cache.
However, after active-active is implemented, the data in the center changes, and the cache of the unit also needs to be invalidated. However, the cache invalidation of the unit cannot directly depend on the change message of the central DB. If you directly rely on the change message of the central DB, the cache failure of the unit may fail before the change of the unit DB. At this time, when the user visits, the old data may be written into the cache, resulting in data inconsistency.
Therefore, the current solution is to synchronize the central DB data to the unit through DRC. After the unit DB is changed, the binlog will be sent to MQ through DRC, and then the application will operate the cache invalidation or update.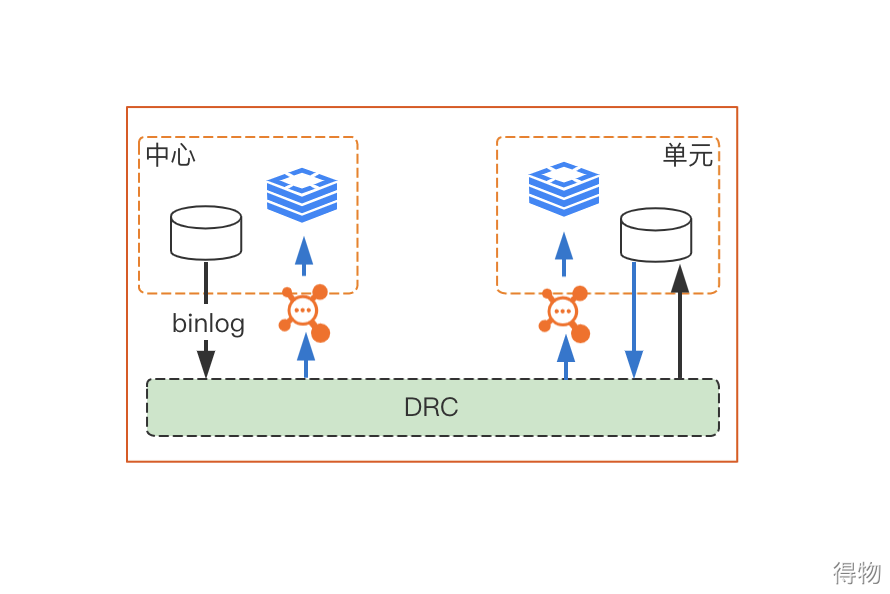
MQ message
MQ middleware also needs to be modified to ensure that messages can fall to the correct unit and be consumed in the correct unit.
Most of the original logic before HyperMetro is to insert or update data after receiving messages. If the library has undergone unit transformation, some data has been allocated to the corresponding unit for writing according to the corresponding strategy, but the message is consumed in the center at this time, which will cause double writing on both sides and dirty data. This requires that MQ also has the ability to route, allowing messages to be routed to the correct unit, not just relying on the routing restrictions of the RPC framework or DAL layer.
In the current solution, messages are replicated in both directions. Subscription consumption is performed according to the subscription method configured by the consumer.
-
Subscribe to the center, only consume in the center
-
Ordinary subscription, consume the news of this unit nearby.
-
Unit subscription, each unit consumes the messages of each unit. DMQ will be routed to the unit consumption according to the routing rules
-
Subscribe to all units, send to all units, and all units will be consumed once
::: hljs-center
3. Disaster recovery capability & strategy
:::
(1) Flow cut step
-
Forbid the request of some users to write and switch streams. Interception will be performed at the traffic entrance, RPC framework, and DAL layer, the request will be discarded, and an exception will be thrown.
-
DRC confirms whether the synchronization is completed according to the time node.
-
After the data synchronization is completed, the routing starts according to the latest routing rules.
(2) Disaster recovery scenario
If there is a failure in the unit computer room, the traffic can be switched to the new center room
The central computer room is faulty, and the current solution cannot solve it. In the follow-up, the center failover can be switched to the central backup environment, or the central computer room can be used as a logical computer room to enhance the disaster resistance of the central computer room. The schematic diagram is as follows 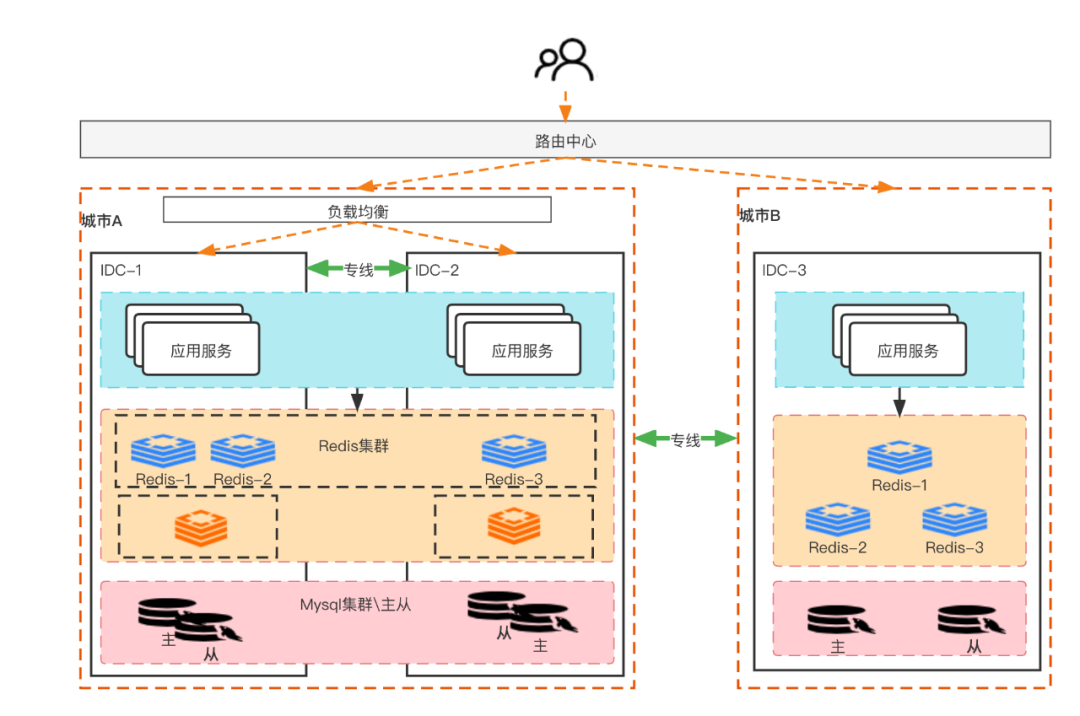 ::: hljs-center
::: hljs-center
【appendix】
::: ::: hljs-center
The meaning of several common core indicators
::: [RTO] (Recovery Time Objective), that is, recovery time objective. It mainly refers to the longest time that can be tolerated for the business to stop the service, that is, the shortest time period required from the occurrence of the disaster to the recovery of the service function of the business system. RTO describes how long the recovery process takes. For example: Assuming that the recovery process is started at time point t1 and the recovery process is completed at time point t2, then RTO is equal to t2-t1. The smaller the RTO value, the stronger the data recovery capability of the disaster recovery system. RTO=0 means that the target business is not allowed to have any operation stoppage under any circumstances.
[RPO] (Recovery Point Object) Recovery point objective refers to a point in time in the past, when a disaster or emergency occurs, the time point to which data can be recovered, is the amount of data loss that the business system can tolerate. For example, if data backup is performed at 00:00 every day, if a downtime event occurs today, the time point (RPO) to which the data can be restored is 00:00 today. If a disaster or downtime event occurs at 3:00 in the morning, the lost data will be For three hours, if a disaster occurs at 23:59, the lost data is about 24 hours, so the user's RPO is 24 hours, that is, the user's maximum data loss is 24 hours. So RPO refers to the maximum amount of data that users are allowed to lose. This is related to the frequency of data backup. In order to improve RPO, the frequency of data backup must be increased. The RPO index mainly reflects the effectiveness of backup data under the business continuity management system, that is, the smaller the RPO value, the stronger the system's ability to guarantee data integrity.
You can compare RTO and RPO by the following figure. 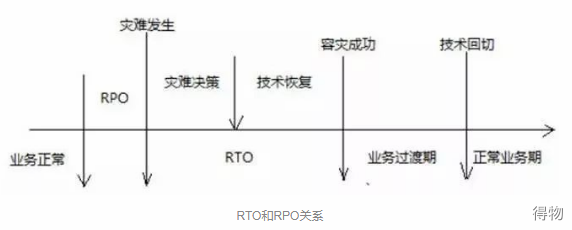 It is not difficult to see from the figure that the RPO index comes from before the fault occurs, and the RTO index comes from after the fault occurs. The smaller the value of the two, the time interval from normal business to business transition period can be effectively shortened, and the RTO or RPO can be improved only Indicators can also shorten the time from business failure to transition period. Specifically, which indicator to improve should be analyzed in combination with the actual situation. The cost of improving the indicator is the least, and the effect is more obvious.
It is not difficult to see from the figure that the RPO index comes from before the fault occurs, and the RTO index comes from after the fault occurs. The smaller the value of the two, the time interval from normal business to business transition period can be effectively shortened, and the RTO or RPO can be improved only Indicators can also shorten the time from business failure to transition period. Specifically, which indicator to improve should be analyzed in combination with the actual situation. The cost of improving the indicator is the least, and the effect is more obvious. 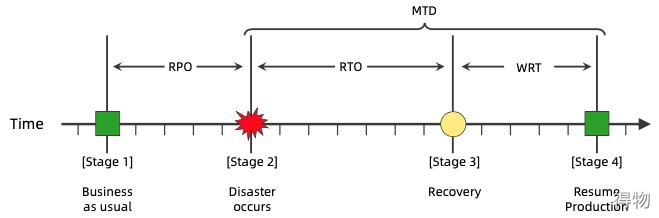 【WRT】(Work Recovery Time), work recovery time, refers to "the time required to resume business after the system returns to normal", because various business inspections, verifications, and repairs are required.
【WRT】(Work Recovery Time), work recovery time, refers to "the time required to resume business after the system returns to normal", because various business inspections, verifications, and repairs are required.
【MTD】(Maximum Tolerable Downtime), the maximum tolerable downtime, equal to RTO + WRT.
Reference materials: Li Yunhua "Learning Architecture from 0" "Architecture Practical Column"
Text/Hu Qiangzhong
Offline event recommendation : Dewu Technology Salon "Enterprise Collaboration Efficiency Evolution Road" (19th issue)
Time : 14:00, July 16, 2023 ~ 18:00, July 16, 2023
Venue : (Yangpu, Shanghai) 5th Floor, Building C, Internet Treasure Land, No. 221, Huangxing Road (Exit No. 1, Ningguo Road Subway Station)
Highlights of the event : In today's increasingly competitive business environment, the efficiency of enterprise collaboration has become the key to the success of enterprise teams. More and more enterprises realize that through the support of informatization construction and tools, the efficiency of collaboration can be greatly improved and breakthroughs can be made in the industry. This salon will cover a number of topics, which will provide participants with rich thinking and experience, and help improve the efficiency of enterprise collaboration.
Through the exchange platform of Dewu Technology Salon, you will have the opportunity to learn from representatives of other companies and learn from each other's experience and practices. Discuss the best practices of enterprise internal collaboration efficiency to drive long-term survival and development of enterprises. Join Dewu Technology Salon and start a new chapter of collaborative efficiency with industry pioneers! Let us work together for a breakthrough in collaboration efficiency!
Click to sign up : Dewu Technology Salon "Enterprise Collaborative Efficiency Evolution Road" (19th Issue)
This article is an original article of Dewu Technology, sourced from: Dewu Technology Official Website
Reprinting without the permission of Dewu Technology is strictly prohibited, otherwise legal responsibility will be pursued according to law!
Author: Dewu Technology
Link: https://tech.dewu.com/article?id=10