thanks for reading
reading instructions
(1) [xxx] appears in the article to indicate the serial number of the document cited in the original text
(2) Most of them are machine translated using the Transform model. I feel that after reading my own experience, I have made some revisions. If you have any questions, you can discuss them together
Summary
original
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech without transcripts from thousands of speakers, to generate a fixed-dimensional embedding vector from only seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2 that generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder network that converts the mel spectrogram into time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the multispeaker TTS task, and is able to synthesize natural speech from speakers unseen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
translate
We describe a neural network-based text-to-speech (TTS) synthesis system capable of generating speech audio in the voices of different speakers, including those not seen during training. Our system consists of three independently trained components: (1) a speaker encoder network trained on a speaker verification task using an independent dataset of noisy speech (not many human speech datasets), from only a few Second reference speech to generate fixed-dimensional embedding vectors; (2) Tacotron 2-based sequence-to-sequence synthesis network, conditioned on speaker embeddings, to generate mel-spectrograms from text; (3) Wavenet-based autoregressive vocoding A network of detectors that converts mel spectrograms into time-domain waveform samples. We demonstrate that the proposed model is able to transfer knowledge of speaker variability learned by discriminatively trained speaker encoders to the multi-speaker TTS task and to synthesize natural speech from speakers not seen during training. To achieve the best generalization performance, we quantify the importance of training speaker encoders on large and diverse speaker sets. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech different from the new speaker's voice used in training, showing that the model learns high-quality speaker representations.
may not know the meaning in English
synthesis synthesis, fusion
code thinking
1. As mentioned in the original text, there are very few data sets. We can use data enhancement and sampling to solve this problem. But if the model works well and the data is not enough, should we use this model to generate it in other tasks? I have seen many bloggers and UP masters have achieved an effect that is extremely similar to real people.
2. Tacotron2 mentioned in the original text is an End-to-End speech synthesis framework proposed by Google Brain in 2017. The model can be seen as consisting of two parts from bottom to top:
Spectrum prediction network: an Encoder-Attention-Decoder network, which is used to predict the input character sequence as a frame sequence
vocoder (vocoder) of Mel spectrum: a WaveNet A revised version of , used to generate a time-domain waveform from a sequence of predicted mel-spectrum frames
introduce
original
The goal of this work is to build a TTS system which can generate natural speech for a variety of speakers in a data efficient manner. We specifically address a zero-shot learning setting, where a few seconds of untranscribed reference audio from a target speaker is used to synthesize new speech in that speaker’s voice, without updating any model parameters. Such systems have accessibility applications, such as restoring the ability to communicate naturally to users who have lost their voice and are therefore unable to provide many new training examples. They could also enable new applications, such as transferring a voice across languages for more natural speech-to-speech translation, or generating realistic speech from text in low resource settings. However, it is also important to note the potential for misuse of this technology, for example impersonating someone’s voice without their consent. In order to address safety concerns consistent with principles such as [1], we verify that voices generated by the proposed model can easily be distinguished from real voices. Synthesizing natural speech requires training on a large number of high quality speech-transcript pairs, and supporting many speakers usually uses tens of minutes of training data per speaker [8]. Recording a large amount of high quality data for many speakers is impractical. Our approach is to decouple speaker modeling from speech synthesis by independently training a speaker-discriminative embedding network that captures the space of speaker characteristics and training a high quality TTS
model on a smaller dataset conditioned on the representation learned by the first network. Decoupling the networks enables them to be trained on independent data, which reduces the need to obtain high quality multispeaker training data. We train the speaker embedding network on a speaker verification task to determine if two different utterances were spoken by the same speaker. In contrast to the subsequent TTS model, this network is trained on untranscribed speech containing reverberation and background noise from a large number of speakers. We demonstrate that the speaker encoder and synthesis networks can be trained on unbalanced and disjoint sets of speakers and still generalize well. We train the synthesis network on 1.2K speakers and show that training the encoder on a much larger set of 18K speakers improves adaptation quality, and further enables synthesis of completely novel speakers by sampling from the embedding prior. There has been significant interest in end-to-end training of TTS models, which are trained directly from text-audio pairs, without depending on hand crafted intermediate representations [ 17, 23 ]. Tacotron 2 [15 ] used WaveNet [ 19] as a vocoder to invert spectrograms generated by an encoderdecoder architecture with attention [ 3], obtaining naturalness approaching that of human speech by combining Tacotron’s [ 23] prosody with WaveNet’s audio quality. It only supported a single speaker. Gibiansky et al. [ 8] introduced a multispeaker variation of Tacotron which learned low-dimensional speaker embedding for each training speaker. Deep Voice 3 [13 ] proposed a fully convolutional encoder-decoder architecture which scaled up to support over 2,400 speakers from LibriSpeech [ 12 ]. These systems learn a fixed set of speaker embeddings and therefore only support synthesis of voices seen during training. In contrast, VoiceLoop [ 18 ] proposed a novel architecture based on a fixed size memory buffer which can generate speech from voices unseen during training. Obtaining good results required tens of minutes of enrollment speech and transcripts for a new speaker. Recent extensions have enabled few-shot speaker adaptation where only a few seconds of speech per speaker (without transcripts) can be used to generate new speech in that speaker’s voice. [ 2] extends Deep Voice 3, comparing a speaker adaptation method similar to [18] where the model parameters (including speaker embedding) are fine-tuned on a small amount of adaptation data to aspeaker encoding method which uses a neural network to predict speaker embedding directly from a spectrogram. The latter approach is significantly more data efficient, obtaining higher naturalness using small amounts of adaptation data, in as few as one or two utterances. It is also significantly more computationally efficient since it does not require hundreds of backpropagation iterations. Nachmani et al. [ 10 ] similarly extended VoiceLoop to utilize a target speaker encoding network to predict a speaker embedding. This network is trained jointly with the synthesis network using a contrastive triplet loss to ensure that embeddings predicted from utterances by the same speaker are closer than embeddings computed from different speakers. In addition, a cycle-consistency loss is used to ensure that the synthesized speech encodes to a similar embedding as the adaptation utterance. A similar spectrogram encoder network, trained without a triplet loss, was shown to work for transferring target prosody to synthesized speech [ 16]. In this paper we demonstrate that training a similar encoder to discriminate between speakers leads to reliable transfer of speaker characteristics. Our work is most similar to the speaker encoding models in [ 2, 10 ], except that we utilize a network independently-trained for a speaker verification task on a large dataset of untranscribed audio from tens of thousands of speakers, using a state-of-the-art generalized end-to-end loss [ 22]. [ 10 ] incorporated a similar speaker-discriminative representation into their model, however all components were trained jointly. In contrast, we explore transfer learning from a pre-trained speaker verification model. Doddipatla et al. [ 7] used a similar transfer learning configuration where a speaker embedding computed from a pre-trained speaker classifier was used to condition a TTS system. In this paper we utilize an end-to-end synthesis network which does not rely on intermediate linguistic features, and a substantially different speaker embedding network which is not limited to a closed set of speakers. Furthermore, we analyze how quality varies with the number of speakers in the training set, and find that zero-shot transfer requires training on thousands of speakers, many more than were used in [7].
translate
The goal of this work is to build a TTS system that can generate natural speech for a variety of speakers in a data-efficient manner. We specifically discuss the zero-shot learning setting. where a few seconds of untranscribed reference audio from a target speaker is used to synthesize a new speech in that speaker's voice without updating any model parameters. Such systems have accessibility applications, such as the ability to restore natural communication with a voice-affected user, and thus cannot provide many new training examples. They can also support new applications, such as transferring speech across languages for more natural speech-to-speech conversion, or generating realistic speech from text in low-resource settings. However, it's also important to be aware of the potential for misuse of this technology, such as impersonating someone's voice without their consent. To address security issues consistent with principles such as [1], we verify that the voices produced by the proposed model can be easily distinguished from real voices. Synthesizing natural speech requires training on a large number of high-quality speech-text pairs, and supporting many speakers typically requires tens of minutes of training data per speaker [8]. For many speakers, recording large amounts of high-quality data is impractical. Our approach decouples speaker modeling from speech synthesis by independently training a speaker discriminative embedding network that captures the speaker feature space and training high-quality TTS conditioned on what the first network has learned, in
comparison Model training on small datasets. Decoupling the networks enables them to be trained on independent data, reducing the need for high-quality multi-speaker training data. We train a speaker embedding network on a speaker verification task to determine whether two different utterances are spoken by the same speaker. In contrast to the subsequent TTS model, the network was trained on untranscribed speech containing reverberation and background noise from a large number of speakers.
We demonstrate that speaker encoders and synthesis networks can be trained on imbalanced and disjoint speaker ensembles and still generalize well. We train the synthesis network on 1.2K speakers and show that training the encoder on a larger ensemble of 18K speakers improves the quality of adaptation and further synthesizes completely new speakers by sampling from the embedding prior.
There has been great interest in end-to-end training of TTS models trained directly from text-to-audio pairs without relying on handcrafted intermediate representations [17, 23]. Tacotron 2 [15] uses WaveNet [19] as a vocoder, and uses attention [3] to invert the spectrogram generated by the encoder architecture, and combines the prosody of Tacotron [23] with the audio quality of WaveNet to obtain close to human speech of naturalness. It only supports one speaker. Gibiansky et al. [8] introduced a multi-sensor variant of Tacotron that learns low-dimensional speaker embeddings for each training speaker. Deep Voice 3 [13] proposes a fully convolutional encoder-decoder architecture that scales to support more than 2400 speakers from LibriSpeech [12]. These systems learn a fixed set of speaker embeddings and thus only support speech synthesis seen during training. In contrast, VoiceLoop [18] proposes a new architecture based on a fixed-size memory buffer that can generate speech from unseen speech during training. To get good grades, new speakers need tens of minutes of speeches and content drafts.
Recent extensions enable few-shot speaker adaptation, where each speaker only needs a few seconds of speech (without transcription) to speak in Generate new sounds from human speech. [2] extends Deep Voice 3, comparing a speaker adaptation method similar to [18] with speaker encoding methods, where model parameters (including speaker embeddings) are fine-tuned on a small amount of adaptive data, the method Predicting speaker embeddings directly from spectrograms using neural networks. The latter approach is significantly more data efficient, using a small amount of adaptive data and achieving higher naturalness within one or two utterances. It also significantly improves computational efficiency, since it does not require hundreds of backpropagation iterations. Nachmani et al. [10] similarly extended VoiceLoop to utilize the target speaker encoding network to predict speaker embeddings. The network is trained jointly with the synthesis network using a contrastive triplet loss to ensure that the embeddings predicted from the same speaker's utterances are closer than those computed from different speakers. Furthermore, a cycle consistency loss is used to ensure that the synthesized speech is encoded to an embedding similar to the adaptive utterance
A similar spectrogram encoding net, trained without triple loss, was shown to work in converting target prosody into synthetic speech [16]. In this paper, we demonstrate that training a similar encoder to distinguish between speakers leads to reliable transfer of speaker features. Our work is most similar to speaker encoding models in [2, 10], except that we leverage an independently trained network to perform speaker verification on large datasets of untranscribed audio from tens of thousands of speakers task, using the state-of-the-art generalized end-to-end loss [22]. [10] incorporated similar speaker discrimination representations in their model, but all components were trained jointly. In contrast, we explore transfer learning from pre-trained speaker verification models. Doddipatla et al. [7] used a similar transfer learning configuration, where a TTS system was conditioned using speaker embeddings computed from a pre-trained speaker classifier. In this paper, we leverage an end-to-end synthesis network that does not rely on intermediate language features, and a intrinsically different speaker embedding network that is not limited to a closed set of speakers. In addition, we analyze how sound quality varies with the number of speakers in the training set and find that zero-shot transitions require thousands of seconds of training
new words that may not be understood
spectrogram
et alien
Multispeaker speech synthesis model
Multi-person Speech Synthesis Model
original
Our system is composed of three independently trained neural networks, illustrated in Figure 1: (1) a recurrent speaker encoder, based on [22 ], which computes a fixed dimensional vector from a speech signal, (2) a sequence-to-sequence synthesizer, based on [ 15], which predicts a mel spectrogram from a sequence of grapheme or phoneme inputs, conditioned on the speaker embedding vector, and (3) an autoregressive WaveNet [19 ] vocoder, which converts the spectrogram into time domain waveforms
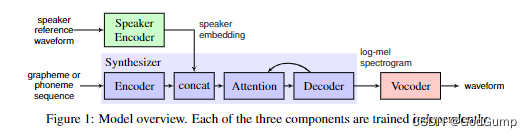
2.1 Speaker encoder
The speaker encoder is used to condition the synthesis network on a reference speech signal from the desired target speaker. Critical to good generalization is the use of a representation which captures the characteristics of different speakers, and the ability to identify these characteristics using only a short adaptation signal, independent of its phonetic content and background noise. These requirements are satisfied using a speaker-discriminative model trained on a text-independent speaker verification task. We follow [22 ], which proposed a highly scalable and accurate neural network framework for speaker verification. The network maps a sequence of log-mel spectrogram frames computed from a speech utterance of arbitrary length, to a fixed-dimensional embedding vector, known as d-vector [20 , 9 ]. The network is trained to optimize a generalized end-to-end speaker verification loss, so that embeddings of utterances from the same speaker have high cosine similarity, while those of utterances from different speakers are far apart in the embedding space. The training dataset consists of speech audio examples segmented into 1.6 seconds and associated speaker identity labels; no transcripts are used.
Input 40-channel log-mel spectrograms are passed to a network consisting of a stack of 3 LSTM layers of 768 cells, each followed by a projection to 256 dimensions. The final embedding is created by L2-normalizing the output of the top layer at the final frame. During inference, an arbitrary length utterance is broken into 800ms windows, overlapped by 50%. The network is run independently on each window, and the outputs are averaged and normalized to create the final utterance embedding. Although the network is not optimized directly to learn a representation which captures speaker characteristics relevant to synthesis, we find that training on a speaker discrimination task leads to an embedding which is directly suitable for conditioning the synthesis network on speaker identity.
2.2 Synthesizer
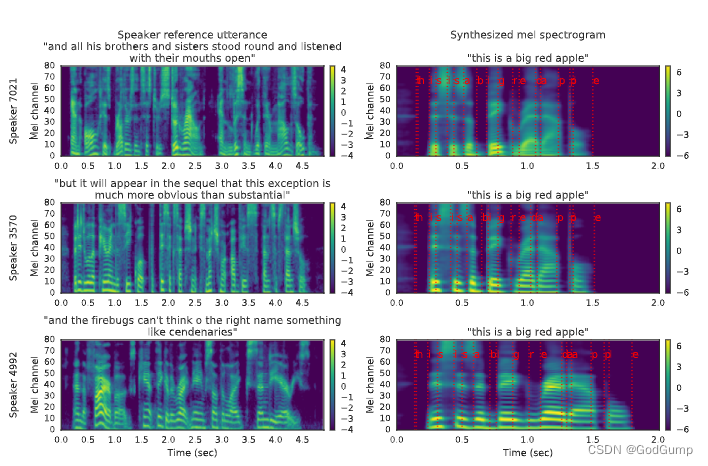
We extend the recurrent sequence-to-sequence with attention Tacotron 2 architecture [ 15] to support multiple speakers following a scheme similar to [ 8]. An embedding vector for the target speaker is concatenated with the synthesizer encoder output at each time step. In contrast to [8], we find that simply passing embeddings to the attention layer, as in Figure 1, converges across different speakers. We compare two variants of this model, one which computes the embedding using the speaker encoder, and a baseline which optimizes a fixed embedding for each speaker in the training set, essentially learning a lookup table of speaker embeddings similar to [8, 13]. The synthesizer is trained on pairs of text transcript and target audio. At the input, we map the text to a sequence of phonemes, which leads to faster convergence and improved pronunciation of rare words and proper nouns. The network is trained in a transfer learning configuration, using a pretrained speaker encoder (whose parameters are frozen) to extract a speaker embedding from the target audio, i.e. the speaker reference signal is the same as the target speech during training. No explicit speaker identifier labels are used during training. Target spectrogram features are computed from 50ms windows computed with a 12.5ms step, passed through an 80-channel mel-scale filterbank followed by log dynamic range compression. We extend [15 ] by augmenting the L2 loss on the predicted spectrogram with an additional L1 loss. In practice,Figure 2: Example synthesis of a sentence in different voices using the proposed system. Mel spectrograms are visualized for reference utterances used to generate speaker embeddings (left), and the corresponding synthesizer outputs (right). The text-to-spectrogram alignment is shown in red. Three speakers held out of the train sets are used: one male (top) and two female (center and bottom). we found this combined loss to be more robust on noisy training data. In contrast to [ 10 ], we don’t introduce additional loss terms based on the speaker embedding.
2.3 Neural vocoder
We use the sample-by-sample autoregressive WaveNet [ 19 ] as a vocoder to invert synthesized mel spectrograms emitted by the synthesis network into time-domain waveforms. The architecture is the same as that described in [15], composed of 30 dilated convolution layers. The network is not directly conditioned on the output of the speaker encoder. The mel spectrogram predicted by the synthesizer network captures all of the relevant detail needed for high quality synthesis of a variety of voices, allowing a multispeaker vocoder to be constructed by simply training on data from many speakers
2.4 Inference and zero-shot speaker adaptation
During inference the model is conditioned using arbitrary untranscribed speech audio, which does not need to match the text to be synthesized. Since the speaker characteristics to use for synthesis are inferred from audio, it can be conditioned on audio from speakers that are outside the training set. In practice we find that using a single audio clip of a few seconds duration is sufficient to synthesize new speech with the corresponding speaker characteristics, representing zero-shot adaptation to novel speakers. In Section 3 we evaluate how well this process generalizes to previously unseen speakers. An example of the inference process is visualized in Figure 2, which shows spectrograms synthesized using several different 5 second speaker reference utterances. Compared to those of the female (center and bottom) speakers, the synthesized male (top) speaker spectrogram has noticeably lower fundamental frequency, visible in the denser harmonic spacing (horizontal stripes) in low frequencies, as well as formants, visible in the mid-frequency peaks present during vowel sounds such as the ‘i’ at 0.3 seconds – the top male F2 is in mel channel 35, whereas the F2 of the middle speaker appears closer to channel 40. Similar differences are also visible in sibilant sounds, e.g. the ‘s’ at 0.4 seconds contains more energy in lower frequencies in the male voice than in the female voices. Finally, the characteristic speaking rate is also captured to some extent by the speaker embedding, as can be seen by the longer signal duration in the bottom row compared to the top two. Similar observations can be made about the corresponding reference utterance spectrograms in the right column.
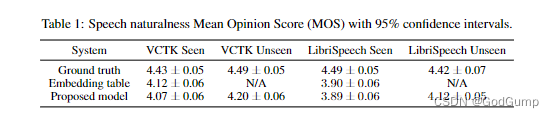
translate
Our system consists of three independently trained neural networks, as shown in Figure 1: (1) a recursive speaker encoder based on [22] that computes a fixed dimension vector from speech (2) a recursive speaker encoder based on [15] A sequence-to-sequence synthesizer that predicts mel-spectrograms from a sequence of grapheme or phoneme inputs based on speaker embedding vectors, and (3) an autoregressive WaveNet [19] vocoder that converts the spectrograms into time-domain waveforms .
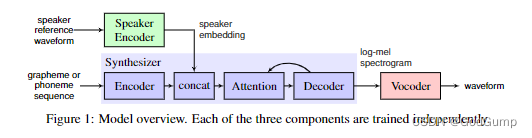
2.1 Speaker Encoder
The speaker encoder is used to adjust the synthesis network based on the reference speech signal from the desired target speaker. The key to good generalization is the use of representations that capture the characteristics of different speakers, and the ability to recognize these characteristics using only short adaptation signals, independent of their speech content and background noise. These requirements are met using a speaker discrimination model trained on a text-independent speaker verification task. We follow [22], which proposes a highly scalable and accurate neural network framework for speaker verification. The network maps a sequence of log-mel-spectrogram frames computed from speech utterances of arbitrary length to fixed-dimensional embedding vectors, called d-vectors [20, 9]. The network is trained to optimize a generalized end-to-end speaker verification loss such that the embeddings of utterances from the same speaker have high cosine similarity, while utterances from different speakers are far apart in the embedding space. The training dataset consists of audio samples of speech split into 1.6 seconds and associated speaker identity labels; no transcripts are used.
The input 40-channel log-mel spectrogram is passed to a network consisting of a stack of 3 LSTM layers of 768 units, each followed by a 256-dimensional projection. The final embedding is created by L2 normalizing the output of the top layer at the final frame. During inference, utterances of arbitrary length are divided into 800ms windows with 50% overlap. The network is run independently on each window, and the outputs are averaged and normalized to create the final utterance embeddings.
Although the network is not directly optimized to learn representations that capture synthesis-relevant speaker features, we find that training on the speaker discrimination task results in embeddings that are directly suitable for conditioning synthesis networks on speaker identity.
2.2 Synthesizer
We extend repeated sequences to the sequential Tacotron 2 architecture [15] with attention to support multiple speakers following a scheme similar to [8]. The embedding vector of the target speaker is concatenated with the synthesizer encoder output at each time step. Contrary to [8], we find that simply passing embeddings to the attention layer converges across different speakers, as shown in Figure 1. We compare two variants of this model, one that uses speaker encoders to compute embeddings, and another that optimizes a baseline with fixed embeddings for each speaker in the training set, essentially learning a Speaker embedding lookup table. The synthesizer is trained on pairs of text transcriptions and target audio. On the input side, we map the text to a sequence of phonemes, which leads to faster convergence and improved pronunciation of rare words and proper nouns. The network is trained in a transfer learning configuration to extract speaker embeddings from the target audio using a pretrained speaker encoder (whose parameters are frozen), i.e., the speaker reference signal is the same as the target speech during training. No explicit speaker identifier labels are used during training. Target spectrogram features were computed from 50ms windows in steps of 12.5ms, passed through an 80-channel mel-scale filter bank, followed by logarithmic dynamic range compression. We extend [15] by adding an L2 loss and an additional L1 loss on the predicted spectrogram. In practice, Figure 2: Examples of sentences synthesized in different voices using the proposed system. Mel spectrograms are visualized as reference utterances used to generate speaker embeddings (left) and corresponding synthesizer outputs (right). The alignment of the text to the spectrogram is shown in red. Three speakers outside the train set were used: one male (top) and two females (middle and bottom). We find that this combined loss is more robust on noisy training data. Contrary to [10], we do not introduce an additional loss term based on speaker embeddings.

2.3 Neural Vocoder
We use a sample-wise autoregressive WaveNet [19] as a vocoder to convert the synthetic mel spectrogram emitted by the synthesis network into a time-domain waveform. The architecture is the same as the one described in [15] and consists of 30 dilated convolutional layers. The network does not directly depend on the output of the speaker encoder. The mel-spectrogram predicted by the synthesizer network captures all relevant details required for high-quality synthesis of a variety of sounds, allowing the construction of multi-sensor vocoders by simply training on data from many speakers.
2.4 Inference and zero-shot speaker adaptation
During inference, the model is conditioned using arbitrary unrecorded speech audio without matching text to be synthesized. Since the speaker characteristics used for synthesis are inferred from the audio, they can be adjusted based on audio from speakers outside the training set. In practice, we found that using a single audio clip lasting several seconds is sufficient to synthesize new speech with the characteristics of the corresponding speaker, which represents zero-shot adaptation to the new speaker. In Section 3, we evaluate how well this process generalizes to previously unseen speakers. An example of the inference process is shown in Figure 2, which shows spectrograms synthesized using several different 5-second speaker reference utterances. Compared to the female (center and bottom) speakers, the synthesized male (top) speaker spectrogram has a significantly lower fundamental frequency, visible in denser harmonic spacing (horizontal stripes) in the low frequencies, and formants, at 0.3 Visible in the mid-frequency peaks that occur in vowels in the second (like the "i")—the top male F2 is in mel channel 35, while the middle speaker's F2 appears closer to channel 40. Similar differences can also be seen in hiss, for example, the "s" at 0.4 seconds contains more energy in the low frequencies of male voices than female voices. Finally, feature speaking rates are also captured to some extent by speaker embeddings. The signal duration of the next row is longer compared to the first two rows. Similar observations can be made for the corresponding reference utterance spectrograms in the right column
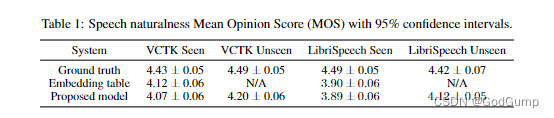
Thoughts on code
1. For the speaker encoder, we can limit the maximum amount of speech content. We set the matrix to 0 for the small part, and directly discard the large part to fix the dimension.