references:
Speaker Verificationbilibilibilibili
(2) Meta Learning – Metric-based (1/3) - YouTube
All cited papers are omitted this time
Table of contents
A brief introduction to the model
Evaluation index Equal Error Rate (EER)
2. Speaker Embedding explanation
Speaker Embedding production method
3. End-to-End end-to-end learning
4. Some additional questions and answers
一、Introduction
A brief introduction to the model
-
There is such a large category of sound models. The main task that the model needs to complete is to input a piece of speech and output a certain category.
-
Related models or tasks are:
-
Emotion Recognition: Emotion recognition, input speech, and determine the speaker’s emotion.
-
Sound Event Detection: Sound event detection, input voice, determine what happened, can be used in security and other industries.
-
Autism Recognition: Autism recognition, input speech, and determine whether you have autism.
-
Keyword Spotting: Keyword recognition, input speech, and determine whether the specified keyword appears in the speech.

-
-
So what are the tasks related to the speaker using this type of model?
-
Speaker Recognition/Identification: Speaker recognition, determining who speaks a piece of speech. Its essence is to use a corpus of multilingual speakers for training, then input a piece of speech, and output the Confidence (credibility) of all speakers through the model. Whoever has a higher credibility will be judged as who said the signal. We won’t introduce it too much here.
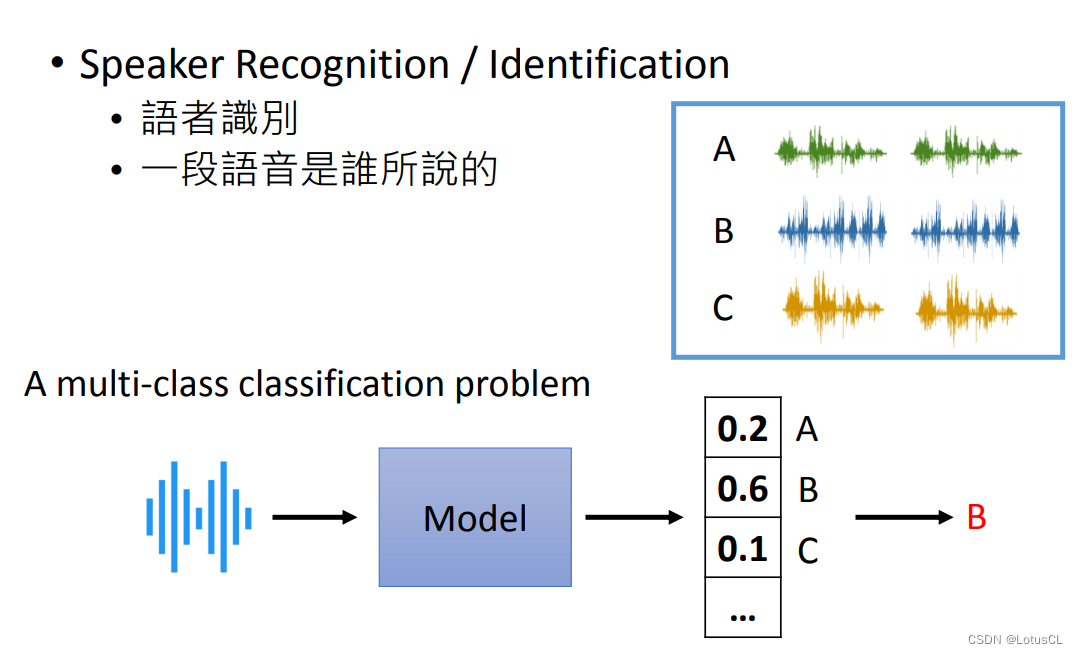
-
Speaker Verification: Speaker verification, input two pieces of speech to determine whether the two pieces of speech are spoken by the same person. Given a previously recorded sound and a newly input sound, the model will determine the similarity between the two, and output a probability indicating the similarity (scalar in the figure means scalar), and use a threshold to determine whether the two are the same. Said the same person. Typical applications include bank customer service determining whether the person withdrawing money is a depositor.
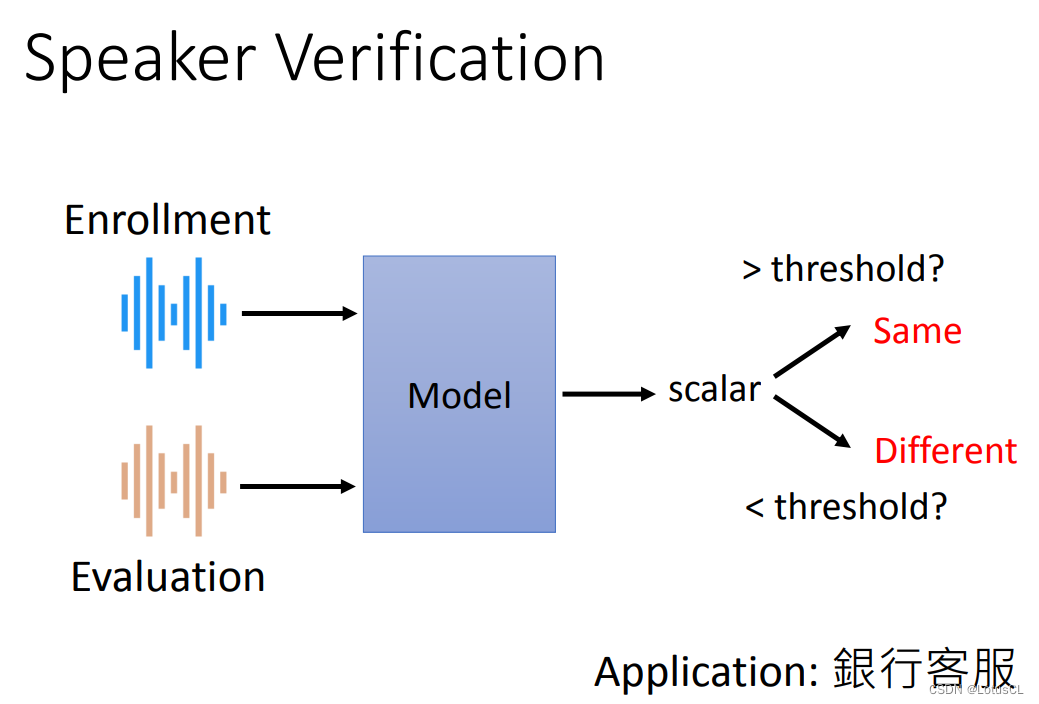
-
Speaker Diarization: Speaker segmentation marking, input a piece of speech, and identify who spoke when in this speech. The SD system first needs to segment the sound signal (Segmentation). Usually each paragraph is a sentence or a paragraph. Next we will do clustering to mark which segment is the same vocal. If the number of different speakers is known, then you only need to know who is speaking this sentence. For example, in a phone call scene, it is usually two people. If we don’t know how many people are talking, such as in a meeting scene, we need to group the voices belonging to the same person into one category and give it a number. Here we need to use some of the first two technologies, namely speaker recognition and voiceprint recognition technology.

-
Evaluation index Equal Error Rate (EER)
-
Equal Error Rate (EER), the Chinese name is Equal Error Rate. In the Speaker Verification model, we usually need to manually set a threshold to determine whether the two are spoken by the same person. It is natural for us to know that by setting different thresholds, the performance of the model will naturally be different. Threshold selection is usually left to the user. So how do we judge which of the two models is better?
-
We will enumerate all thresholds, draw them into a graph, and calculate the EER. Let's give some simple examples first.
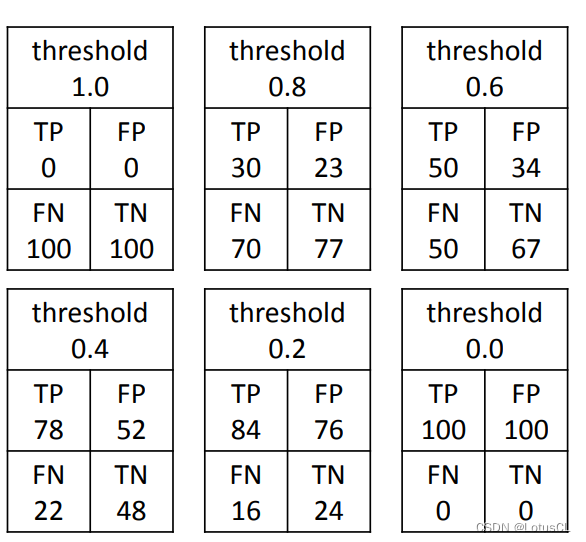
-
If I directly set the threshold to 1.0, then for this model, no matter which two pieces of speech are input, the model will judge that they are not spoken by the same person.
-
If I set the threshold very high, such as 0.8, then for this model, two audio clips using the same speaker may be misjudged as being spoken by different people, and the false negative rate [False Negative Rate] will be relatively high. , because your standards are relatively harsh; however, if two audio clips using different speakers are misjudged as being spoken by the same person, the false positive rate [False Positive Rate] is relatively low.
-
If I directly set the threshold to 0 later, then for this model, no matter which two pieces of speech are input, the model will judge that they are spoken by the same person. Using the concept just now, we can say, FNR = 0, FPR = 1.
-
-
Finally, with the FPR value as the x-axis and the FNR value as the y-axis, we draw the image, and EER is the magnitude of the two when FPR = FNR.
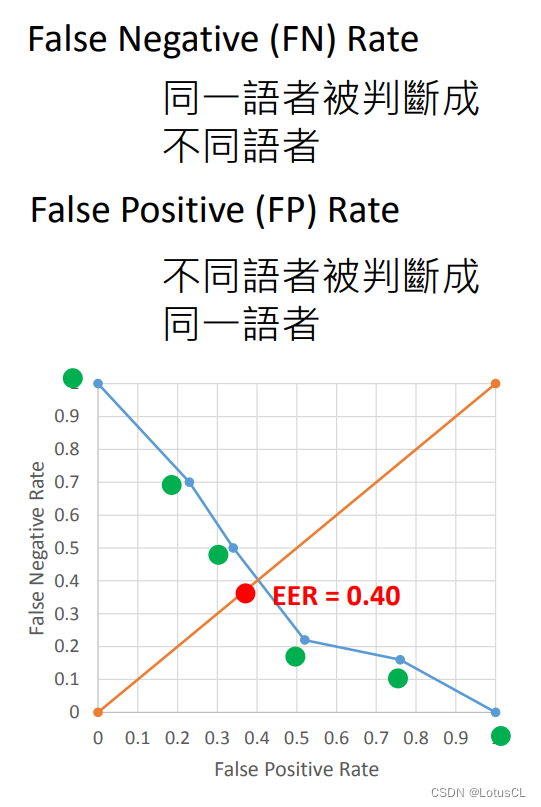
2. Speaker Embedding explanation
model framework
-
So what exactly does the SV model look like? Traditional SV models usually use certain methods to input a sound signal and output a vector to represent the speaker characteristics. This speaker characteristic is what we call Speaker Embedding. With this method, we can convert the two sound signals into Speaker Embedding, and then compare the similarity between the two.

-
Specific steps for using the model:

-
Stage 1: Development, that is, model training, uses the corpus to train the model, so that the model can learn the encoding method of Speaker Embedding.
-
Stage 2: Enrollment, that is, voiceprint entry, requires the speaker to enter his or her voice into the system. The system will input these sounds into the model one by one, obtain speaker embeddings, average them, and store them in the database.
-
Stage 3: Evaluation, that is, voiceprint evaluation, that is, the verification stage. The system will obtain another speaker embedding from the detected human voice input model, compare it with the previously stored embedding, and draw a conclusion whether it is the same person.
It is worth mentioning that in the steps just mentioned, the speakers of the corpus used to train the model will not appear in subsequent use of the model.
-
-
The set of ideas of the SV model is actually almost the same as the idea of Metric-based meta learning. For details, please refer to(2) Meta Learning – Metric-based (1/3) - YouTube.
data set
-
How big a data set is needed to train the SV extraction Speaker Embedding model? Google used 18,000 speakers and a total of 36M sentences to train the model. The experiment cannot run on this kind of data. Generally, we will use a relatively small Benchmark Corpus (baseline corpus), such as the VoxCeleb data set for training.

Speaker Embedding production method
-
The early method used was i-vector. No matter how long the input speech is, a 400-dimensional i-vector will eventually be generated to represent the voiceprint information. i means identity. i-Vector is a very powerful method. Wasn't beaten by the DL until '16.

-
The earliest model that uses deep learning to extract Speaker Embedding is d-vector. It intercepts a small segment of the sound signal (because the input length of the DNN used later is fixed), sends it to the DNN, and finally outputs it after passing through a multi-layer network. During the training process, we have been training this model as a Speaker Recognition model, that is, which speaker speaks the final output. After the model is trained, we take out the output of the last hidden layer. This is what we want d-vector.
We don't use the output of the last output layer because it will determine which speaker the sound comes from at this time, so its dimension is related to the number of speakers during training, and we don't want such a vector, so we use is the output of the last hidden layer.
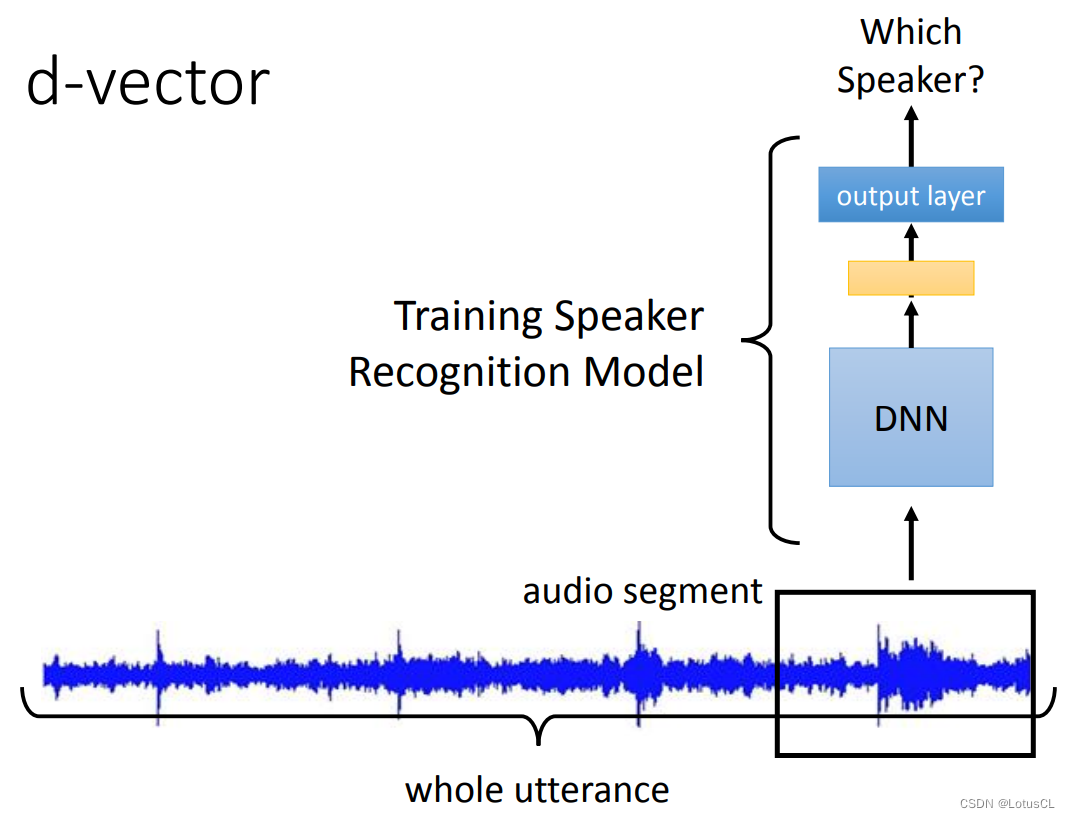
-
Of course, the method just now is just to read a short piece of voice. It is also very simple to read a whole paragraph of speech. Perform the above operations for each small paragraph, and finally average it to get the final d-vector. In 2014, d-vector can do the same thing as i-vector. But this is just to let everyone know that deep learning can do this stuff.

-
By 2018, x-vector was released. It aggregates the output of each speech segment after passing through the model in a way, rather than simply averaging like a d-vector. This method is to take the mean and variance vectors of each dimension, concatenate them, and then input them to a model to do the Speaker Recognition task. At that time, the hidden layer output by this model is taken as the x-vector representing the voiceprint information. It is different from d-vector in that it considers an entire segment of speech information. You can also consider using LSTM for aggregation here.

-
Of course, you can also use Attention to calculate the attention weight of each speech segment, and then do a weighted sum. There is also a method borrowed from images, NetVLAD. The main idea is that not all segments in a speech are human voices, and some of them are environmental noise. We can figure out how to take just the vocal part out of it. The specific details will not be repeated here.
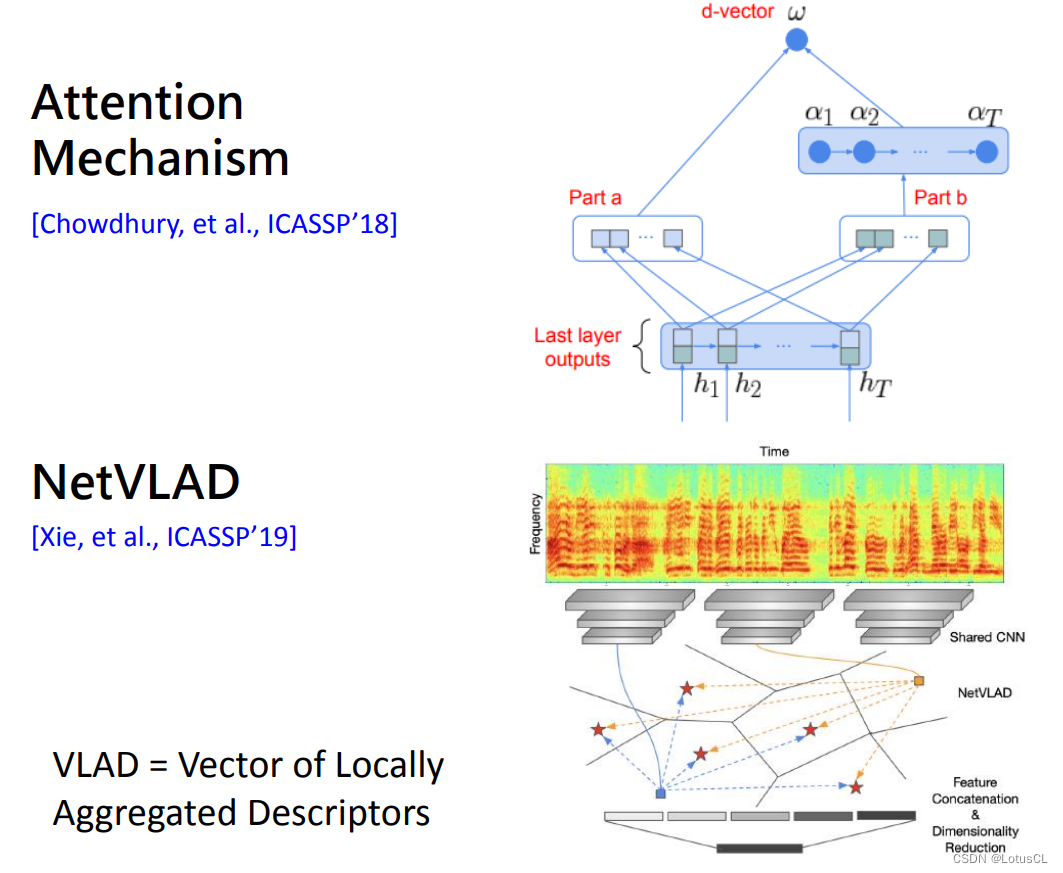
-
Combining these methods, we first train the model according to the Speaker Recognition task, and then extract the output and use it in the Speaker Verification task.
3. End-to-End end-to-end learning
Previously, we all tried to get the Speaker Embedding, and then calculated the similarity between the two to complete the task. This is a separation method, so is there any way for us to combine "calculating Speaker Embedding" and "calculating similarity" to do joint learning and learn and train together?
Training data preparation
-
First we need to prepare our training data. In previous tasks, the data we had were a bunch of speakers, and each speaker said a bunch of things. Assume that our Enrollment link requires the speaker to say k sentences, then we prepare the information like this:
-
Positive Examples: Select k sentences from what a certain speaker says as registered sentences and input them into the model. Take another sentence from the same speaker as a test sentence and then input it into the model. The final output value is The bigger the better.

-
Negative Examples: Select k sentences from what a certain speaker says as registered sentences and input them into the model. Take a sentence from another speaker as a test sentence and then input it into the model. The final output value is The smaller the better.

-
-
Of course, in addition to this method of preparing data sets, we also have various other methods, such as Generalized E2E (GE2E, [Wan, et al., ICASSP’18]), etc., which will not be described here.
Model design
-
The internal structure of the end-to-end model completely imitates the traditional SV model. There are K registered sentences. Each sentence will enter a network and generate a vector to serve as Speaker Embedding. The sentences used for testing are also the same, and a vector will be generated through a network.
-
Next, we average the vector generated by the registered sentence to get a vector, and then calculate the similarity with the vector generated by the test sentence just now. Here, we can also use a network to calculate the similarity, and finally get a score. How to train end-to-end? We hope that the scores will be smaller for the voices spoken by different people, and we hope that the scores will be larger for the voices spoken by the same person.
-
The commonly used similarity calculation is to first calculate the cosine similarity between the two, and then do some small transformations, such as multiplying by a weight, and then adding a bias.
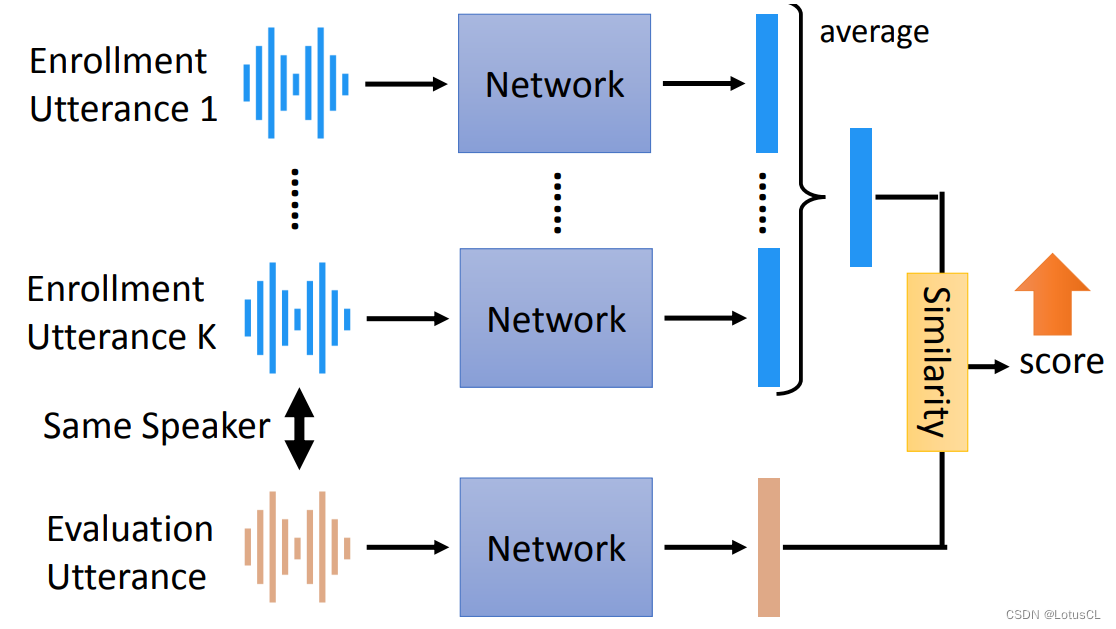
-
This end-to-end model can be divided into Text-dependent and Text-independent. If the registration and evaluation say the same text content, it is Text-dependent. For example, the same code word "open sesame" must be said. If it can be different text content, it is Text-independent.
-
If we want to be Text-independent, then when we extract Speaker Embedding analogues, we need to extract only speaker information as much as possible, without extracting content information. Here, we can introduce the idea of GAN to combat training. We can connect a Discriminator (discriminator) after the generated Speaker Embedding to identify the text content (a bit like ASR). And our training goal has one more goal. The network that outputs Speaker Embedding must find a way to fool the discriminator and make it impossible to recognize the text content from the voiceprint embedding.
4. Some additional questions and answers
-
What does EER mean:
Because there are two kinds of errors in this model, one is that it is clearly said by the same person, but you say it is a different person; the other is that the words are said by different people, but you judge that it is the same person. Then this involves a trade-off (trade-off) between two error rates. Then EER is to judge the quality of the model by looking at the size when the error rates of the two errors are the same.
You can also refer to the answer on Zhihu here:How to understand equal error rate (EER, Equal Error Rate)? Please don't just give a definition - Zhihu (zhihu.com), in fact it is quite different.