foreword
The full name of the verification code (CAPTCHA) is the Fully Automated Public Turing test to tell Computers and Humans Apart. From its full name, it can be seen that the verification code is used to test whether the user is a real human being. A typical captcha consists of distorted text that is difficult for a computer program to parse, but
Humans can still (hopefully) read. Many websites use captchas to defend against bots interacting with their site. For example, many banking websites force you to enter a verification code every time you log in, which is very painful. This chapter describes how to automate captcha processing, first using Optical Character Recognition (OCR), and then using a captcha processing API.
7.1 Account registration
When processing the form in the previous chapter, we used a manually created account to log in to the website, and ignored the part of automatically creating an account, because the
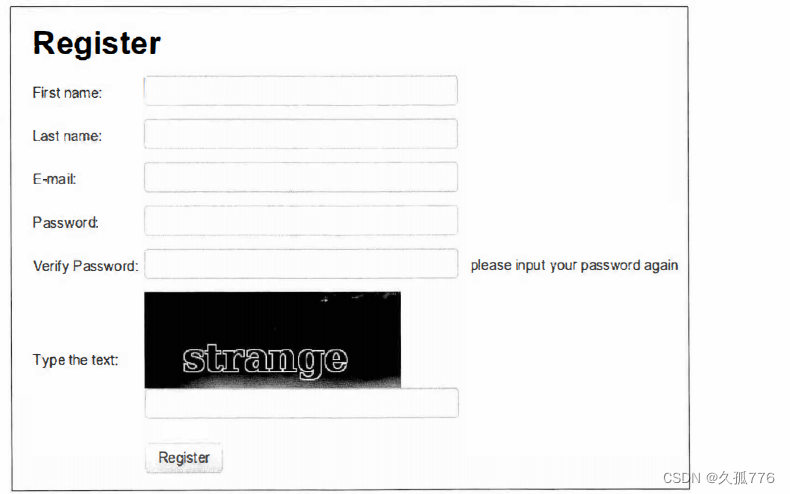
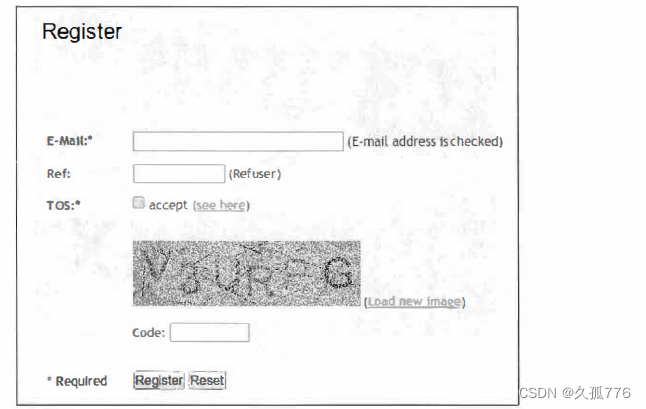
registration form requires a verification code to be entered. The registration page is http://example.webscraping.com/user/register, as shown in the figure below
Note that a different captcha image is displayed each time the form loads. In order to know which parameters the form needs, we can reuse the parse_form() function written in the previous chapter.
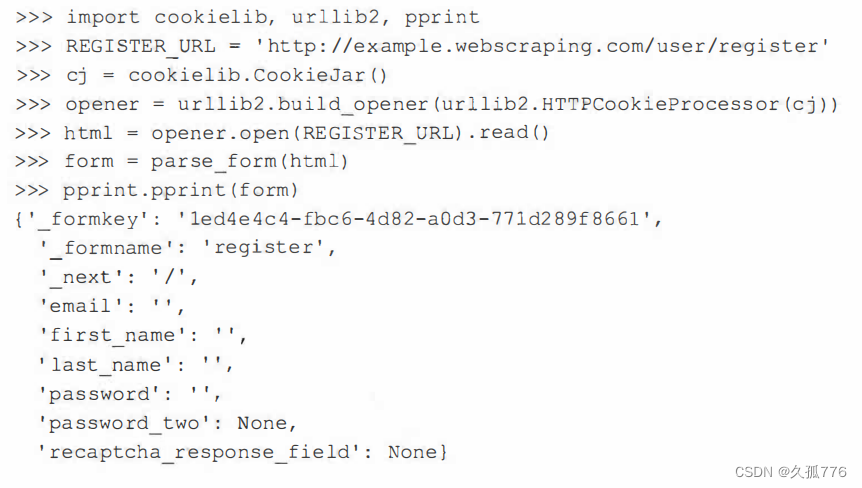
In the previous code, other fields are easy to handle except recaptcha_response_field, which in this case requires us to extract the strange string from the image.
7.1 .1 Load verification code image
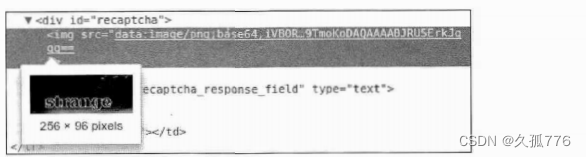
Before we can analyze the captcha image, we first need to get that image from the form. You can see through Firebug that the image data is embedded in the web page instead of being loaded from other URLs, as shown in the figure below
To process this image in Python, we will use the Pillow package, which can be installed via pip using the following command.
pip install pillow
For other methods of installing Pillow , please refer to http://pillow.readthedocs.org/installation.html
Pillow provides a convenient Image class, which contains many advanced methods for processing captcha images. The function below takes the HTML of the registration page as an input parameter and returns a tooltip object containing the captcha image.
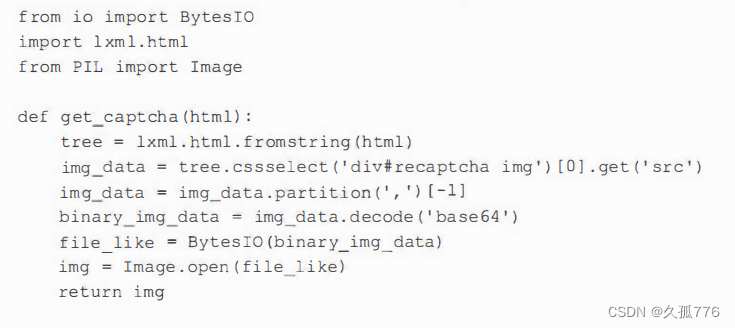
The first few lines use lxml to get the image data from the form. The prefix of the image data defines the data type. In this case, it's a Base64-encoded PNG image, which uses ASCII encoding to represent binary data. We can remove this prefix by splitting on the first comma. Then, decode the image data using Base64, back to the original binary format. To load an image, PIL needs a file-like interface, so before passing it to the Image class, we used Bytes IO to encapsulate this binary data.
After getting a verification code image with a more suitable format, we can try to extract text from it

7.2 Optical Character Recognition
Optical Character Recognition (OCR) is used to extract text from images. In this section, we will use the open source Tesseract OCR engine. The engine was originally developed by Hewlett-Packard and is currently dominated by Google. Tesseract installation instructions can be obtained from https://code.google.com/p/tesseract-ocr/wiki/ReadMe. Then, its Python packaged version, pytesseract, can be installed using p ip.
pip install pytes seract
If the original image of the verification code is directly passed to pyte sseract, the parsing result will generally be very bad.

After the above code is executed, an empty character will be returned, which means that Tesseract failed to extract the characters in the input image. This is because Tesseract was originally designed to extract more typical text, such as pages with a uniform background. If we want to use Tesseract more effectively, we need to modify the verification code image first, remove the background noise, and only keep the text part. In order to better understand the captcha system we will be dealing with, a few more example captchas are given in the figure below.

As can be seen from the example above, the verification code text is generally black, and the background will be brighter, so we can separate the text by checking whether the pixel is black. This process is also called value-based. This process is easily implemented with Pillow.

At this time, only the pixels whose OR value is less than 1 will be kept, that is to say, only the pixels that are completely black will be kept. This code snippet saves 3 images, which are the original verification code image, the converted grayscale image, and the thresholded image. The image below shows the images saved for each stage.

Finally, the text is clearer in the thresholded image, at which point we can pass it to Tesseract for processing.

It worked! The text in the verification code has been successfully extracted. Of the 100 images I tested, the method correctly parsed 84 captcha images. Since the sample text is always lowercase ASCII characters, we can further improve performance by limiting the results to these characters.
In a test of the same 100 images, the recognition rate improved to 88%. Below is the complete code for the current registration script.

The register() function downloads the registration page, grabs the form, and sets the name, email address, and password of the new account in the form. Then extract the verification code image, pass it to the OCR function, and add the result generated by the OCR function to the form. Next submit the form data and check the response URL to confirm that the registration was successful. If the registration fails, the response URL will still be the registration page, which may be because the verification code image is not parsed correctly, or the email address of the registered account already exists. Now, just call the register() function with the new account information to register the account.

7.2.1 Further improvement
In order to further improve the performance of verification code OCR, the following methods may be used:
Experiment with different thresholds:
Corrode threshold text, highlighting character shapes:
Resize the image (sometimes just increasing the size helps):
Train the OCR tool according to the captcha font:
Limit results to dictionary words.
If you are interested in experimenting with improving performance, you can use the sample data from this link: https://bitbucket.org/wswp/code/src/tip/chapter07/samples/. However, for our purpose of registering an account, the current accuracy rate of 88% is enough, because even real users will make mistakes when entering the verification code text. In fact, even 1% accuracy is enough, because the script can be run many times until it succeeds, but doing so
is not friendly, and may even result in an IP ban.
7.3 Handling complex verification codes
The verification code system used for testing is relatively easy to handle, because the black font used in the text is easily distinguished from the background, and the text is horizontal, which can be accurately parsed by Tesseract without rotation. Under normal circumstances, the website uses a relatively simple universal verification code system like this, and the OCR method can be used at this time. But if the website is using a more complex system, such as Google's reCAPTCHA, the OCR method will take more effort and may not even work.
The image below shows some of the more complex captcha images found on the web.

In these examples, because the text is placed at different angles, and has different fonts and colors, more work is required to clean up the noise using the OCR method. Interpreting these images, even for real humans, can be difficult, especially for those who are visually impaired.
7.3.1 Using verification code processing service
To handle these more complex images, we will use a captcha processing service. There are many captcha processing services, such as capt cha.com and deathbycaptcha.com, the general service price is around $1 for 1000 captcha images. When the captcha image is passed to their API, a human will review it and give the parsed text in the HTTP response. Generally speaking, the process takes less than 30 seconds. In the examples in this section we will use the service of 9kw.eu. While the service doesn't offer the cheapest captcha processing prices, or the best API design, it probably won't cost you to use the API. This is because 9kw.eu allows users to manually process captchas to earn credits and then spend those points to process our captchas.
7.3.2 Getting started with 9kw
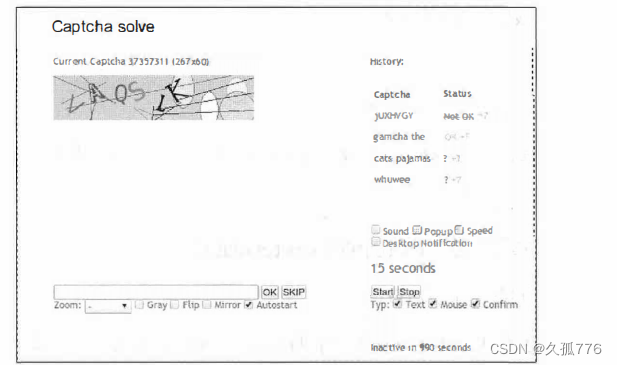
To start using 9kw, you first need to create an account, the registration URL is https://www.9kw.eu/register.html
, the registration interface is shown in the figure below
Then, follow the account confirmation instructions. After logging in, we are located at https://www.9kw.eu/usercaptcha.html
, and its page is displayed as shown in the figure below
On this page, it is necessary to process other users' verification codes and not obtain
the credits . After processing several captchas, it will be directed to https://www.91α1.eu/index.cgi
?
action=userapinew&source=api to create an API key.
9kw test horse API
9kw's API document address is https://www.9kw.eu/api.html#apisubmit-tab. The main sections we
use to submit captchas and check results are summarized below.
submit verification code
URL: https://www.9kw.eu/index.cgi( POST)
apikey : your API key
action : must be set to "usercaptchaup
I
oad"
file-upload-01 : The image to process (file, url or string)
base64 : Set to "1" if the input is Base64 encoded
maxtimeout : The maximum time to wait for processing (must be 60~3999 seconds)
selfsolve : set to "1" if the captcha is processed by itself
Return value: the ID of the verification code
Request the result of the submitted verification code
URL:
https://
www.9kw.eu/index.cgi
( GET )
apikey : your API
key
action : must be set to "usercaptchacorrectdata"
id : the captcha ID to check
info : If set to 1, return "NODATA" when no result is obtained (return empty by default)
Return value : Captcha text or error code to be processed
error code
0001 API
key does not exist
0002
API key y not found
0003 No active API
key found
0031 account is disabled by the system for 24 hours
0032 account does not have sufficient permissions
0033 Need to upgrade the plug-in
Below is the initial implementation code for sending captcha images to the API.
import urllib
import urllib2API_URL = ’https://www.9kw.eu/index.cgi’
def send_captcha (api_key, img_data) :
data = {
’ action ’:’ usercaptchaupload ’ ,
’ apikey ’:api_key,
’ file-upload-01’:img_data.encode(’base64’),
’ base64’:’1’,
’ selfsolve’:’1’,
’ maxtimeout’ :’60’
}
encoded_data = urllib.urlencode(data)
request = urllib2.Request(API_URL, encoded_data)
response = urllib2.urlopen(request)
return response.read ()
The structure should look familiar, first we create a dictionary of the required parameters, encode them, and submit them as the request body. It should be noted that here the selfsolve option is set to '1'. Under this setting, if we are using 9kw's web interface to process the verification code, then the verification code image will be sent to us for processing, which can save our points . If we are not logged in at this time, the verification code will be passed to other users as usual.
Below is the code to get the captcha image processing result
def get_captcha(api_key, captcha_id):
data = {
’action’:’usercaptchacorrectdata’ ,
’id’:captcha_id,
’apikey’ : api_key
}
encoded data = urllib . url encode ( data )
# note this is a GET request
# so the data is appended to the URL
re sponse = urllib2.urlopen(API_URL + ’ ? ’ + encoded_data )
return response.read()
One disadvantage of 9kw's API is that its response is an ordinary string, rather than a structured format like JSON, which will make the distinction of error messages more complicated. For example, if no user is processing
the captcha , the string ERRORNOUSER will be returned. Fortunately, the captcha images we submit will never contain this type of text.
Another difficulty is that the getcaptcha() function returns an error message only when other users have time to manually process the captcha image, which, as mentioned before, is usually after 30 seconds. In order to make the implementation more friendly, we will add a wrapper function for submitting the captcha image and waiting for the result to be returned. The extended version code below encapsulates these functions into a reusable
Among the classes, the function of checking error messages has also been added.
import time
import urllib
import urllib2
import re
from io import BytesIO
class CaptchaAP I:
def__init__( self,api_key,timeout=60):
self.api_key = api_key
self.timeout = timeout
self.url = ’https://www.9kw.eu/index.cgi’
def solve(self,img):
””” Submit CAPTCHA and return result when ready
”””
img_buffer = BytesIO()
img.save(img_buffer,format=”PNG”)
img_data = img_buffer.getvalue()
captcha_id = self.send(img_data)
start_time = time.time()
while time.time() < start_time + self.timeout:
try:
text = self.get (captcha_id)
except CaptchaError:
pass # CAPTCHA still not ready
else:
if text != ’NO DATA ’ :
if text == ’ERROR NO USER ’ :
raise CaptchaError(’ Error: no user
available to solve CAPTCHA’)
else :
print ’CAPTCHA solved!’


The source code of the Capt chaAPI class can be obtained from https://bitbucket.org/wswp/code/src/tip/chapter07/api.py, and the code in this link will be updated when 9kw.eu modifies its API. This class is instantiated with your APIkey and a timeout, where the timeout defaults to 60 seconds. Then, the solve() method submits the captcha image to the API, and continues to request until the captcha image is processed or the timeout is reached. Currently, when checking the error message in the API response, the check() method only checks the initial character to confirm whether it follows the format of the 4-digit error code before the error message. To make the API more robust to use, this method can be extended to include all 34 error types.
The following is an example of the execution process when using the CaptchaAPI class to process captcha images.
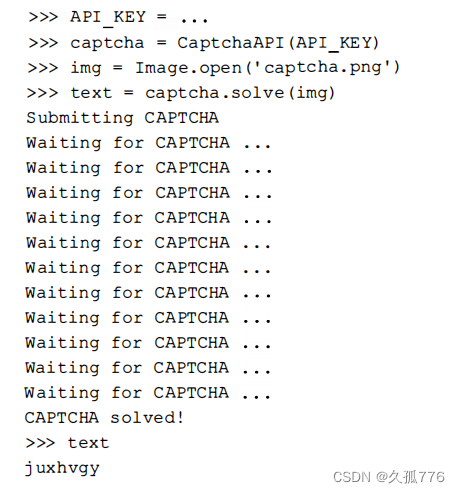
This is the correct recognition result for the first complex captcha image given earlier in this chapter. If the same captcha image is submitted again, the cached result will be returned immediately and the points will not be consumed again.

7.3.3 Integration with registration function
Now that we have a working captcha API solution, we can integrate it with the previous form. The following code modifies the register function so that it passes in the function of processing the verification code image as a parameter so that we can choose to use the OCR method or the API method.
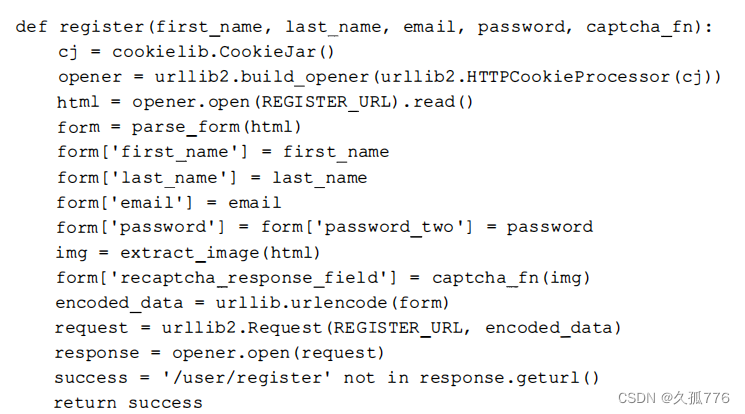
Below is an example of using this function.


It worked! We successfully obtained the verification code image from the form and submitted it to 9k's API. After that, other users processed the verification code manually, and the program submitted the returned result to the web server to register a new account.
7.4 Chapter Summary
This chapter gives methods for handling captchas: first by using OCR, then by using external APIs. For simple captchas, or when you need to process a large number of captchas, it is worth spending time on the OCR method. Otherwise, it's more cost-effective to handle the API with captchas.