foreword
One of the concepts that we can't avoid when we engage in databases is 连接( join). I believe that many friends are a little confused when they first learn to connect. After understanding the semantics of the connection, they may not understand how the records in each table are connected, so that they often fall into the following two misunderstandings when using the database later :
误区一: Business comes first, no matter how complicated the query is, it can be done in one connection statement误区二: Stay away, the slow query may be caused by the use of connections
So in this article, we will systematically study the principle of connection. Considering that some friends are newbies, let's first introduce some connection syntaxes supported in MySQL.
Interested friends can also take a look at 【数据库原理 • 二】关系数据库理论[ through train ]
Table of contents
1. Connection Introduction
1.1 The nature of connection
In order for us to study normally, two simple tables are created here and some data is inserted into them:
mysql> create table demo9 (m1 int, n1 char(1));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into demo9 values(1, 'a'), (2, 'b'), (3, 'c');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table demo10 (m2 int, n2 char(1));
Query OK, 0 rows affected (0.03 sec)
mysql> insert into demo10 values(2, 'b'), (3, 'c'), (4, 'd');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
We have successfully created demo9two demo10tables, both of which have 两个列one inttype and one char(1)type. The data of these two tables are as follows:
mysql> select * from demo9;
+------+------+
| m1 | n1 |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
3 rows in set (0.00 sec)
mysql> select * from demo10;
+------+------+
| m2 | n2 |
+------+------+
| 2 | b |
| 3 | c |
| 4 | d |
+------+------+
3 rows in set (0.00 sec)
连接的本质Just put 各个连接表中的记录都取出来依次匹配的组合加⼊结果集并返回给用户. So the process of connecting demo9the demo10two tables is shown in the following figure:
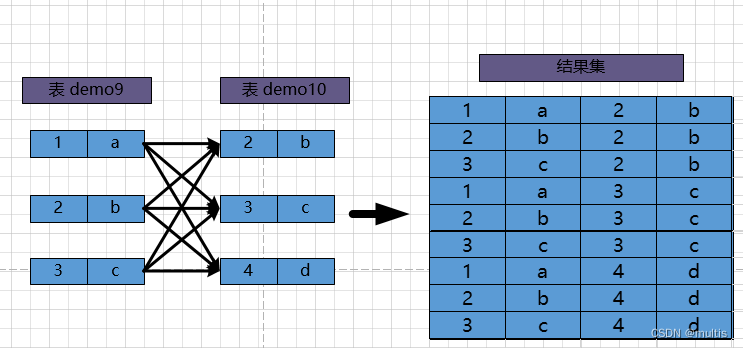
This process is to connect demo9the records of the table and demo10the records of the table to form a new and larger record, so this query process is called 连接查询. The result set of a join query contains a matching combination of every record in one table and every record in the other table. A result set like this can be called 笛卡尔积. Because demo9there are 3records in the table and records demo10in the table, there are records 3after the two tables are connected . In , the syntax of the connection query is also very random, as long as the statement is followed by multiple table names, for example, the query statement that we connect the table and the table can be written as follows:笛卡尔积3×3=9MySQLfromdemo9demo10
mysql> select * from demo9,demo10;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 1 | a | 2 | b |
| 2 | b | 2 | b |
| 3 | c | 2 | b |
| 1 | a | 3 | c |
| 2 | b | 3 | c |
| 3 | c | 3 | c |
| 1 | a | 4 | d |
| 2 | b | 4 | d |
| 3 | c | 4 | d |
+------+------+------+------+
9 rows in set (0.00 sec)
1.2 Introduction to the connection process
If we like, we 可以连接任意数量张表,但是如果没有任何限制条件的话,这些表连接起来产生的笛卡尔积可能是非常巨大. For example, the Cartesian product generated by connecting three 100-record tables has 100×100×100=1,000,000 pieces of data! 过滤掉特定记录组合Therefore, it is necessary when connecting , and the connection query 过滤条件can be divided into two types:
-
Conditions involving a single table
We have mentioned the filter condition of only designing a single table thousands of times before, and we have always called it before,搜索条件for example,demo9.m1 > 1it is a filter condition only fordemo9tables, anddemo10.n2 < 'd'it is a filter condition only fordemo10tables. -
Conditions involving two tables
We have not mentioned this filter condition before, such asdemo9.m1 = demo10.m2,demo9.n1 > demo10.n2etc., these conditions are involved两个表, and we will carefully analyze how this filter condition is used later.
Next, we will take a look at 过滤条件的连接查询the general execution process carried, such as the following query statement:
mysql> select * from demo9, demo10 where demo9.m1 > 1 and demo9.m1 = demo10.m2 and demo10.n2 < 'd';
In this query, we specify this 三个过滤条件:
demo9.m1 > 1demo9.m1 = demo10.m2demo10.n2 < 'd'
Then the general execution process of this query is as follows:
step one:
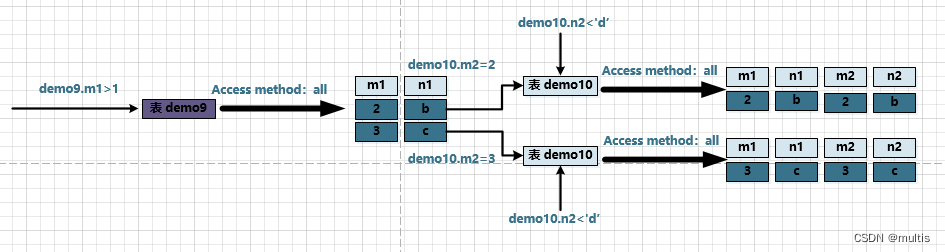
First 确定第一个需要查询的表, the table is called 驱动表. We have already talked about how to execute query statements in a single table, you MySQLonly need to select 代价最小the 访问方法one to execute 单表查询语句(that is to say, select the least costly execution method from const, ref, ref_or_null, range, to execute the query) index. Assuming that it is allused here , it is necessary to find satisfactory records in the table , because the data in the table is too small, and we have not established a secondary index on the table, so the access method of the query table here is set to , That is the way it is executed . We will talk about how to improve the performance of connection queries later, but let's clarify the basic concepts first. So the query process is as shown in the following figure:demo9驱动表demo9demo9.m1>1demo9all全表扫描单表查询
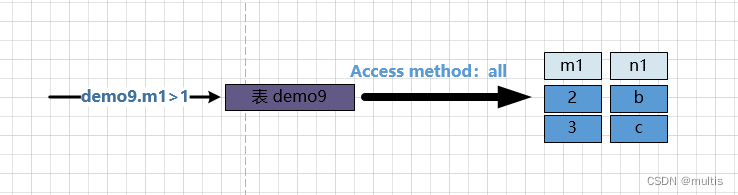
We can see that there are matching records demo9in the table .demo9.m1 > 1两条
Step two:
For the records from the previous step 驱动表产生的结果集中的每一条记录,分别需要到demo10表中查找匹配的记录, the so-called matching records refer to 符合过滤条件的记录. Because demo9the records in the table are found based on demo10the records in the table, demo10the table can also be called 被驱动表. 2In the previous step , a record was obtained from the driver table , so it needs to be queried 2次demo10表. At this point, the filter condition involving the columns of the two tables demo9.m1=demo10.m2comes in handy:
-
At that time
demo9.m1 = 2, filter conditionsdemo9.m1 = demo10.m2就相当于demo10.m2 = 2, so at this timedemo10the table is equivalent to havedemo10.m2 = 2,demo10.n2 < 'd'this两个过滤条件, and thendemo10execute in the table单表查询 -
At that time
demo9.m1 = 3, filter conditionsdemo9.m1 = demo10.m2就相当于demo10.m2 = 3, so at this timedemo10the table is equivalent to havingdemo10.m2 = 3、demo10.n2<'d'this两个过滤条件, and then go todemo10the table to execute单表查询
So the whole 连接查询execution process is shown in the following figure:
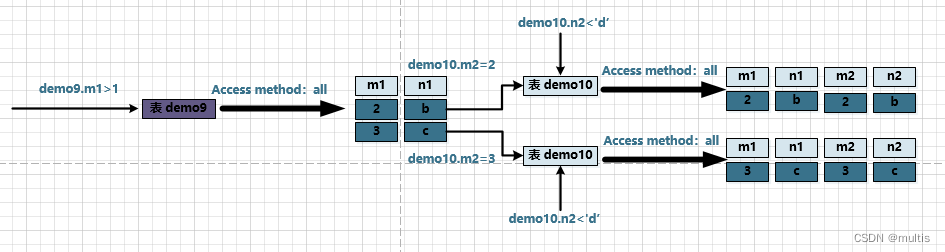
That is to say 整个连接查询最后的结果只有两条符合过滤条件的记录:
mysql> select * from demo9, demo10 where demo9.m1 > 1 and demo9.m1 = demo10.m2 and demo10.n2 < 'd';
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows in set (0.00 sec)
As can be seen from the above two steps, our two-table join query above requires a total of 查询1次demo9表. 2次demo10表Of course, this is the result of a specific filter condition. If we remove demo9.m1 > 1this condition, demo9there will be one record from the table 3, and we need to query 3次demo10the table. That is to say, in the join query between two tables, 驱动表只需要访问⼀次,被驱动表可能被访问多次.
1.3 Inner join and outer join
In order to better learn the following content, we first create two realistic tables:
mysql> create table student (
number int not null auto_increment comment '学号',
name varchar(5) comment '姓名',
major varchar(30) comment '专业',
primary key (number)
) comment '学生信息表';
Query OK, 0 rows affected (0.02 sec)
mysql> create table score (
number int comment '学号',
subject varchar(30) comment '科目',
score tinyint comment '成绩',
primary key (number, score)
) comment '学生成绩表';
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values(1,'张三','软件学院'),(2,'李四','计算机科学与工程'),(3,'王五','计算机科学与工程');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into score values(1,'MySQL是怎样运行的',78),(1,'MySQL实战45讲',88),(2,'MySQL是怎样运行的',78),(2,'MySQL实战45讲',100);
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
We created a new one 学⽣信息表, 一个学生成绩表and then we inserted some data into the above two tables, the data in the latter two tables are as follows:
mysql> select * from student;
+--------+--------+--------------------------+
| number | name | major |
+--------+--------+--------------------------+
| 1 | 张三 | 软件学院 |
| 2 | 李四 | 计算机科学与工程 |
| 3 | 王五 | 计算机科学与工程 |
+--------+--------+--------------------------+
3 rows in set (0.00 sec)
mysql> select * from score;
+--------+-------------------------+-------+
| number | subject | score |
+--------+-------------------------+-------+
| 1 | MySQL是怎样运行的 | 78 |
| 1 | MySQL实战45讲 | 88 |
| 2 | MySQL是怎样运行的 | 98 |
| 2 | MySQL实战45讲 | 100 |
+--------+-------------------------+-------+
4 rows in set (0.00 sec)
Now if we want to query the test scores of each student, we need to join the two tables (because scorethere is no name information in it, we can't just query scorethe table). The connection process is studentto take records from the table and scorefind numberthe same grade records in the table, so the filter condition is student.number =socre.number, the entire query statement is like this:
mysql> select * from student,score where student.number=score.number;
+--------+--------+--------------------------+--------+-------------------------+-------+
| number | name | major | number | subject | score |
+--------+--------+--------------------------+--------+-------------------------+-------+
| 1 | 张三 | 软件学院 | 1 | MySQL是怎样运行的 | 78 |
| 1 | 张三 | 软件学院 | 1 | MySQL实战45讲 | 88 |
| 2 | 李四 | 计算机科学与工程 | 2 | MySQL是怎样运行的 | 98 |
| 2 | 李四 | 计算机科学与工程 | 2 | MySQL实战45讲 | 100 |
+--------+--------+--------------------------+--------+-------------------------+-------+
4 rows in set (0.00 sec)
There are a lot of fields, we can query a few less fields:
mysql> select s1.number,s1.name,s2.subject,s2.score from student s1 ,score s2 where s1.number=s2.number;
+--------+--------+-------------------------+-------+
| number | name | subject | score |
+--------+--------+-------------------------+-------+
| 1 | 张三 | MySQL是怎样运行的 | 78 |
| 1 | 张三 | MySQL实战45讲 | 88 |
| 2 | 李四 | MySQL是怎样运行的 | 98 |
| 2 | 李四 | MySQL实战45讲 | 100 |
+--------+--------+-------------------------+-------+
4 rows in set (0.00 sec)
From the above query results, we can see that the scores of each subject corresponding to each student have been found out, but there is a problem, Wang Wu, that is, the student with the student number 3 did not take the exam for some reason, so scoreThere is no corresponding grade record in the table . Then if the teacher wants to check the test scores of all students, even the students who are absent from the test should be displayed, but the connection query we have introduced so far cannot fulfill such a requirement. Let's think about this requirement a little bit. The essence is that even if the records in the driving table have no matching records in the driven table, they still need to be added to the result set. To solve this problem, there is the concept of 内连接sum 外连接:
- For
内连接的两个表the record in the driving table, no matching record can be found in the driven table, and the record will not be added to the final result set. The connections we mentioned above are all so-called inner connections - For
外连接的两个表records in the driving table, even if there is no matching record in the driven table, it still needs to be added to the result set
In MySQL, according to the selection of the driving table, the outer connection can still be subdivided into two types:
左外连接: Select the table on the left as the driver table右外连接: Select the table on the right as the driver table
But there are still problems, even for 外连接us, sometimes we don't 不想把驱动表的全部记录都加入到最后的结果集. This is difficult. Sometimes the matching fails to add to the result set, and sometimes not to add to the result set. What should I do? Dividing the filter conditions into two types will solve this problem, so the filter conditions placed in different places have different semantics:
-
where子句中的过滤条件:whereThe filter conditions in the clause are the ones we usually see. Whether it is an inner connection or an outer connection, allwhererecords that do not meet the filter conditions in the clause will not be added to the final result set. -
ON子句中的过滤条件: For the record of the driving table of the outer connection, if无法在被驱动表中找到匹配ON子句中的过滤条件的记录, then the record will still be added to the result set, and each field of the corresponding driven table record will be filled withNULLvalues.It should be noted that this
ONclause is specifically proposed for the record in the outer join driver table. When the driven table cannot find a matching record, the record should be added to the result set. Therefore, if the clause is placedONin In the inner connection,MySQLit will bewheretreated the same as the clause, that is to say: the clauses and clauses内连接in are equivalent.whereON
Under normal circumstances, we refer to only involving 单表的过滤条件放到where子句中, and refer to involving 两表的过滤条件都放到ON子句, and we also generally ONrefer to the filter conditions that are placed in the clause 连接条件.
小提示:
Left outer join and right outer join are referred to as left join and right join.
1.4 Left Outer Join
The syntax of the left outer join is quite simple. For example, if we want to join demo9with demo10two tables 左外连接, we can write it like this:
select * from demo9 left [outer] join demo10 on 连接条件 [where 普通过滤条件]
The words in brackets outercan be omitted. For left joina connection of type, we put in 左边的表what we call 外表或者驱动表, 右边的表call it 内表或者被驱动表. So in the above example demo9it is 外表或者驱动表, demo10it is 内表或者被驱动表. It should be noted that for left outer join and right outer join, 必须使用on子句来指出连接条件. After understanding the basic grammar of the left outer join, let’s go back to the real problem above and see how to write query statements to query all the students’ grade information. Even the candidates who missed the exam should be placed in the result set:
mysql> select s1.number,s1.name,s2.subject,s2.score from student s1 left join score s2 on s1.number=s2.number;
+--------+--------+-------------------------+-------+
| number | name | subject | score |
+--------+--------+-------------------------+-------+
| 1 | 张三 | MySQL是怎样运行的 | 78 |
| 1 | 张三 | MySQL实战45讲 | 88 |
| 2 | 李四 | MySQL是怎样运行的 | 98 |
| 2 | 李四 | MySQL实战45讲 | 100 |
| 3 | 王五 | NULL | NULL |
+--------+--------+-------------------------+-------+
5 rows in set (0.01 sec)
It can be seen from the result set that although Wang Wu does not have a corresponding score record, she is still placed in the result set because of the use of 连接类型为左外连接, but the columns of the corresponding score record NULLare filled with values.
1.5 Right outer join
The principles of right outer join and left outer join are the same, and the syntax is just replaced leftby right:
select * from demo9 right [outer] join demo10 on 连接条件 [where 普通过滤条件]
It's just that the driving table is the table on the right, and the driven table is the table on the left, so I won't explain it in detail.
1.6 Inner joins
内连接和外连接的根本区别就是在驱动表中的记录不符合on子句中的连接条件时不会把该记录加入到最后的结果集, the types of join queries we learned at the beginning are all 内连接. However, I only mentioned the simplest inner join syntax before, which is to directly put multiple tables that need to be joined behind the from clause. In fact 针对内连接,mysql提供了好多不同的语法, let’s take the watch demo9as demo10an example:
select * from demo9 [inner|cross] join demo10 [on 连接条件] [where 普通过滤条件];
That is to say, in MySQL, the following inner connection writing methods are equivalent:
select * from demo9 join demo10;
select * from demo9 inner join demo10;
select * from demo9 cross join demo10;
The above writing methods are equivalent to directly putting the name of the table to be connected fromafter the statement :逗号,分隔开
select * from demo9,demo10;
Although we have introduced many ways of writing internal links, it is good to be familiar with one. Here we recommend inner joinwriting internal links mainly because inner jointhe semantics are very clear and can be easily distinguished from left joinand . right joinIt should be noted here that since the clauses and clauses are equivalent in 内连接the middle , it is not required in the inner connection .onwhere强制写明on子句
As we said earlier, 连接的本质就是把各个连接表中的记录都取出来依次匹配的组合加入结果集并返回给用户. No matter which table is used as the driving table, the connection between the two tables 笛卡尔积must be the same. As for 内连接来说,由于凡是不符合on子句或where子句中的条件的记录都会被过滤掉, it is actually equivalent to kicking out the records that do not meet the filter conditions from the Cartesian product of the connection between the two tables, so 对于内连接来说,驱动表和被驱动表是可以互换的,并不会影响最后的查询结果. But for 外连接, 由于驱动表中的记录即使在被驱动表中找不到符合ON子句条件的记录时也要将其加入到结果集, so the relationship between the driving table and the driven table is very important at this time, that is to say 左外连接和右外连接的驱动表和被驱动表不能轻易互换.
summary
A lot has been said above, but it is not very intuitive to everyone. We directly write the three connection methods of tables demo9and demo10sums together, so that everyone can understand it easily:
mysql> select * from demo9 inner join demo10 on demo9.m1 = demo10.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
+------+------+------+------+
2 rows inset (0.00 sec)
mysql> select * from demo9 left join demo10 on demo9.m1 = demo10.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| 1 | a | null | null |
+------+------+------+------+
3 rows inset (0.00 sec)
mysql> select * from demo9 right join demo10 on demo9.m1 = demo10.m2;
+------+------+------+------+
| m1 | n1 | m2 | n2 |
+------+------+------+------+
| 2 | b | 2 | b |
| 3 | c | 3 | c |
| null | null | 4 | d |
+------+------+------+------+
3 rows inset (0.00 sec)
2. The principle of connection
The above introductions are just to awaken everyone's memory of the concepts of 连接, , 内连接, and these basic concepts are to pave the way for the real entry into the topic of this chapter. 外连接The real point is MySQLwhat kind of algorithm is used to join the tables. After understanding this, you can understand why some join queries run as fast as lightning, while others are as slow as snails.
2.1 Nested-Loop Join
As we said before, for the connection between two tables, 驱动表只会被访问一遍,但被驱动表却要被访问到好多遍the specific number of visits depends on the pair 驱动表执行单表查询后的结果集中的记录条数. 对于内连接来说,选取哪个表为驱动表都没关系, 而外连接的驱动表是固定的,也就是说左外连接的驱动表就是左边的那个表,右外连接的驱动表就是右边的那个表. We have already briefly introduced the general process of performing inner join queries demo9on tables and demo10tables. Let’s review:
选取驱动表, using the filter criteria associated with the driver table, select代价最低的单表访问方法来执行对驱动表的单表查询.- For each record in the result set obtained by querying the drive table in the above steps
分别到被驱动表中查找匹配的记录,
The process of joining the two tables through is shown in the figure below:
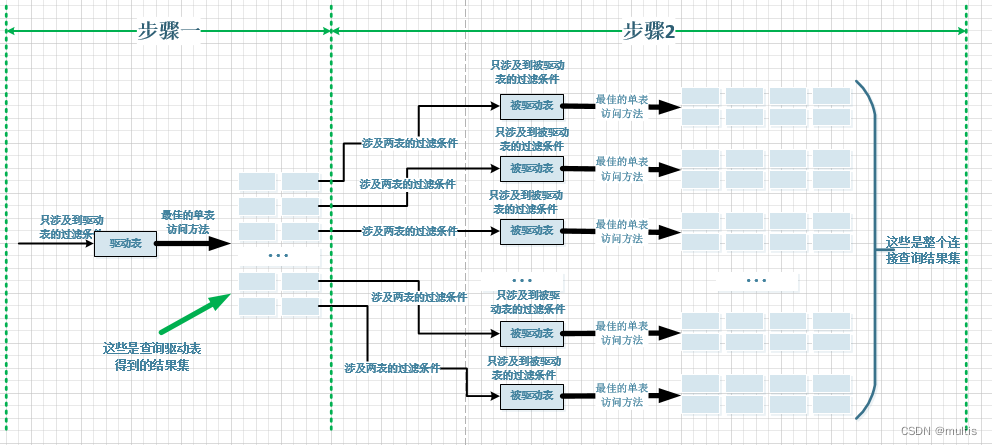
If so 3个表进行连接的话,那么步骤2中得到的结果集就像是新的驱动表,然后第三个表就成为了被驱动表, repeat the above process, that is, for each record in the result set obtained in step 2, you need to demo11find whether there is a matching record in the table. Use pseudo code to express this process as follows:
for each row in demo9 { #此处表示遍历满足对demo9单表查询结果集中的每一条记录
for each row in demo10 { #此处表示对于某条demo9表的记录来说,遍历满足对demo10单表查询结果集中的每一条记
for each row in demo11 { #此处表示对于某条demo9和demo10表的记录组合来说,对demo11表进行单表查询
if row satisfies join conditions, send to client
}
}
}
This process is like one 嵌套的循环, so this kind of driving table is only accessed once, but the driven table may be accessed multiple times. The number of visits depends on the number of records in the result of executing a single table query on the driving table. Call it 嵌套循环连接( Nested-Loop Join), this is the simplest and most clumsy join query algorithm.
2.2 Using indexes to speed up connections
We know that in the nested loop connection 步骤2中可能需要访问多次被驱动表, if 被驱动表的方式都是全表扫描it is accessed, it will have to scan many times~ But don't forget, the query demo10table is actually equivalent to one time 单表扫描, and we can use it 索引来加快查询速度. Let's review the example of inner join between demo9tables introduced at the beginning :demo10
mysql> select * from demo9, demo10 where demo9.m1 > 1 and demo9.m1 = demo10.m2 and demo10.n2 < 'd';
We are actually using 嵌套循坏连接the connection query executed by the algorithm, and then pull down the query execution process table above to show you:
demo9There are two records in the result set after querying the driving table , 嵌套循坏连接the algorithm needs 对被驱动表查询两次:
first:
At that timedemo9.m1 = 2 , to query demo10the table again, demo10the query statement is equivalent to:
select * from demo10 where demo10.m2 = 2 and demo10.m2 < 'd';
the second time:
At that timedemo9.m1 =3 , to query demo10the table again, demo10the query statement is equivalent to:
select * from demo10 where demo10.m2 = 3 and demo10.m2 < 'd';
It can be seen that the original demo9.m1 = demo10.m2filtering condition involving two tables has already determined the conditions about the table demo10when querying the table , so we only need to optimize the query on the table. In the above two query statements on the table The columns used are and columns, we can:demo9demo10demo10m2n2
-
在m2列上建立索引, because yesm2列的条件是等值查找, such asdemo10.m2 = 2,demo10.m2 = 3etc., so the access method that may be usedref, assuming thatrefthe access method is used to executedemo10the query on the table, you need to return to the table before judgingdemo10.n2 < dwhether this condition is true.There is a special case here, that is, assuming that
m2the column isdemo10the primary key of the table or the only secondary index column, then the cost of usingdemo10.m2 = 常数值such conditionsdemo10to find records from the table is常数级别. We know在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称之为constthat MySQL refers to the way of executing the driven table in the connection query使用主键值或者唯一二级索引列的值进行等值查找的查询as:eq_ref. -
To create an index on
n2a column, the conditions involved are the access method thatdemo10.n2 < 'd'may be used . Assuming that the access method used is used to query the demo10 table, it is necessary to return to the table before judging whether the condition on the column is true.rangerangem2
Assuming that there are indexes on both the m2and columns, then you need to choose one of these two . Of course, the index does not necessarily use the index, only the index .n2代价更低的去执行对demo10表的查询在二级索引 +回表的代价比全表扫描的代价更低时才会使用索引
In addition, sometimes 连接查询的查询列表和过滤条件中可能只涉及被驱动表的部分列,而这些列都是某个索引的一部分,这种情况下即使不能使用eq_ref、ref、ref_or_null或者range这些访问方法执行对被驱动表的查询的话,也可以使用索引扫描, that is, indexthe access method to query 被驱动表. Therefore, we suggest that in real work 最好不要使用*作为查询列表, it is best to use 真实用到的列作为查询列表.
2.3 Block Nested-Loop Join
The process of scanning a table is actually to put this first 表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足. Tables in real life are not like tables demo9with demo10only 3 records, tens of thousands of records are rare, and tables with millions, tens of millions, or even hundreds of millions of records are everywhere. The memory may not be able to fully store all the records in the table below, so when scanning the front records of the table, the latter records may still be on the disk, and when the latter records are scanned, there may be insufficient memory, so the former records need to be moved from released in memory. As we said earlier, in the process of joining two tables using the nested loop join algorithm, the driven table has to be accessed many times. If the data in the driven table is too large and cannot be accessed using an index, it is equivalent to The cost of reading this table from the disk many times I/Ois very high, so we have to find a way: minimize the number of accesses to the driven table.
When there被驱动表 is a lot of data in it, every time it is accessed 被驱动表, 被驱动表the records will be loaded into the memory 内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉. Then 驱动表take another record from the result set, 被驱动表record it again 加载到内存中, and repeat, 驱动表as many records as there are in the result set, you have to 被驱动表load it from disk to memory as many times. So can we match the records in the record at 被驱动表one time when loading the records in the memory , so that the cost of repeatedly loading the driven table from the disk can be greatly reduced. 多条驱动表Therefore , a concept MySQLis proposed , which is to apply for a fixed-size memory before executing the connection query, first install several records in the result set of the driving table, and then start scanning the driven table, and each record of the driven table Match multiple driver table records in one- time sum, because the matching process is all done in memory, so this is the case . The process used is shown in the diagram below:join bufferjoin bufferjoin bufferjoin buffer可以显著减少被驱动表的I/O代价join buffer
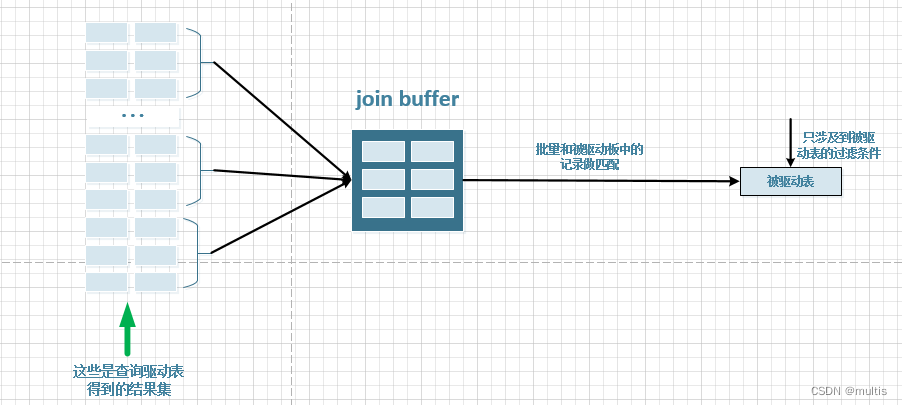
In the best case join buffer, it is large enough to accommodate all the records in the result set of the driving table, so that only one access to the driven table is required to complete the join operation. join buffer的嵌套循环连接算法MySQL calls this join 基于块的嵌套连接(Block Nested-Loop Join)算法.
The size of this join buffercan join_buffer_sizebe configured through startup parameters or system variables, the default size is 262144字节(that is 256KB), the minimum can be set to 128字节. Of course, 对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化.
mysql> show variables like 'join_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
mysql> set persist join_buffer_size=524288;
Query OK, 0 rows affected (0.01 sec)
Tip:
It is not recommended to set this value too large at the system level. Generally, it can be set within 512K, because the final solution still depends on the index to solve it. Of course, it does not rule out that sometimes two tables are associated, and indeed no index is available
Another thing to note is, 驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中, so remind us again, it's best 不要把*作为查询列表to just put the columns we care about in the query list, so that we can join bufferput more records in it.
Summarize
Today we learned about connections. Know the essence of connection, the process of connection, the method of using inner connection and outer connection, and the principle of connection. NLJOn the basis of the original algorithm, a better algorithm MySQLhas been designed . We can pass the driven table . If the index cannot be used, we can try to increase the value ( ). When using inner joins, you need to pay attention to:BNL添加关联字段索引的方式来提高查询效率Join Bufferjoin_buffer_size
-
ON子句和where子句是等价的, so the ON clause is not required to be mandatory in the inner connection -
For inner joins, because everything
不符合on子句或where子句中的条件的记录都会被过滤掉is actually equivalent to kicking out the records that do not meet the filtering conditions from the Cartesian product of the join between the two tables, so for inner joins,驱动表和被驱动表是可以互换,并不会影响最后的查询结果.
So far, today's study is over, I hope you will become an indestructible self
~~~
You can’t connect the dots looking forward; you can only connect them looking backwards. So you have to trust that the dots will somehow connect in your future.You have to trust in something - your gut, destiny, life, karma, whatever. This approach has never let me down, and it has made all the difference in my life
If my content is helpful to you, please 点赞, 评论, 收藏, creation is not easy, everyone's support is the motivation for me to persevere!
This article refers to: Children "How does MySQL work"
