Original | Wen BFT robot

01 Introduction
definition
Artificial Intelligence (A): A broad discipline whose goal is to create intelligent machines other than the natural intelligence exhibited by humans and animals.
Artificial General Intelligence (AlamosGold): A term used to describe a future in which machines can match or even surpass the full range of cognitive abilities of humans in all economically valuable tasks.
Artificial Intelligence Safety: A field of research and attempts to mitigate the catastrophic risks that future artificial intelligence may pose to humanity.
Machine Learning (ML): A subset of artificial intelligence that often uses statistical techniques to enable a machine to "learn" from data without being given explicit instructions on how to do so. The process is called "training" a "model" , using a learning algorithm that incrementally improves the performance of the model on a given task.
Reinforcement Learning (RL): A field of machine learning in which software agents learn goal-directed behavior through trial and error in an environment that provides rewards or punishments in response to the actions they take to achieve a goal actions (called "policies").
Deep Learning (DL): A field of machine learning that attempts to mimic the activity of layers of neurons in the brain to learn how to recognize complex patterns in data. "Deep" refers to the large number of neurons in contemporary models, which facilitates learning rich data representations for better performance gains.
Model: Once a ML algorithm has been trained on data, the output of the process is called a model. This can then be used to make predictions.
Computer Vision (CV): Enabling machines to analyze, understand and process images and videos
Transformer Model Architecture: At the heart of most state-of-the-art (SOTA) ML research. It consists of multiple "attention" layers that learn which part of the input data is most important for a given task. Transformers started with language modeling and then expanded to computer vision, audio, and other modalities.
Research
Diffuse models have taken the computer vision world by storm with their impressive text-to-image generation capabilities
AI studies more scientific problems, including plastic recycling, nuclear fusion reactor control, and natural product discovery.
The Law of Scaling Refocusing on the Data: Maybe model scaling isn't all you need. Community-driven open-sourcing of large models is happening at breakneck speed, enabling collectives to compete with large labs Inspired by neuroscience, AI research is starting to look like cognitive science in approach .
industry
Are upstart Al semiconductor startups making headway against NVIDIA? Aluminum usage statistics show that NVIDIA is 20-100x ahead. Large tech companies expand their AI clouds and form massive partnerships with A(G)L startups The hiring freeze and dissolution of AI labs hastened the formation of many giant startups, including DeepMind and OpenAl.
MaiorAl drug research and development company has 18 clinical assets, and the first CE mark was awarded The latest code research results in the field of artificial intelligence for autonomous medical imaging diagnosis were quickly transformed into commercial development tools by large technology companies and start-up companies.
policy
The gap between academia and industry in large-scale AI work may not be bridged: Academia is getting almost nothing done Academia is passing the baton to a fragmented research collective funded by non-traditional sources.
The great renaissance of American semiconductor capabilities is beginning in earnest.
- AI continues to be infused into more defense product categories, defense AI startups get more funding security
- Awareness, talent, and funding for AI safety research have increased, but still lag far behind capability research.
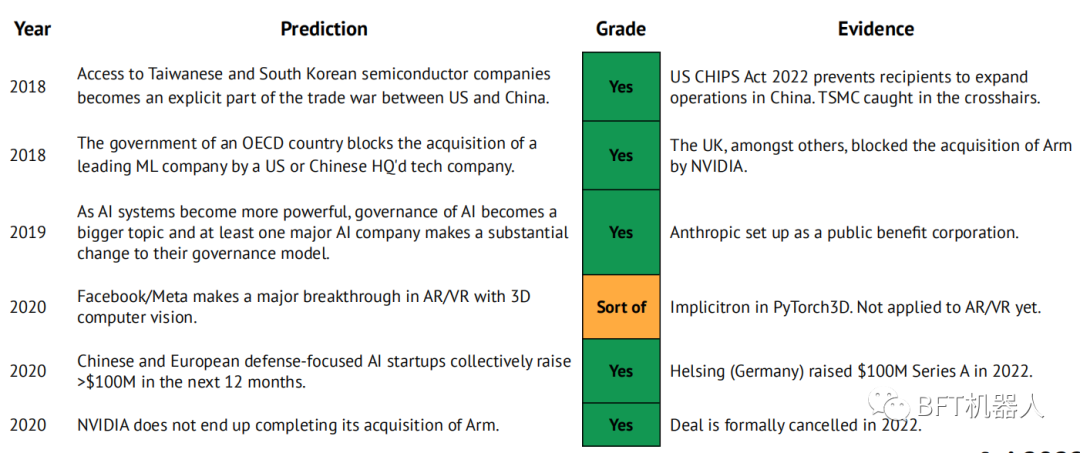
Our 2021 predictions
-
Transformers replace RNNs to learn world models, and RL agents exceed human performance in large and rich games.
-
ASML has a market capitalization of $50 billion.
-
Anthropic publishes articles at the level of GPT and DotaAlphaGo, making itself the third pole of AlamosGold research.
-
There has been a wave of consolidation in the aluminum semiconductor industry as at least one of Graphcore, Cerebras, SambaNova, Groq or Mythic has been acquired by a large technology or major semiconductor company.
-
Small Transformer+CNN hybrid model matches current SOTA on imageNet (CoAtNet-7, 90.88%, 244B parameters) with 10 times fewer parameters
-
DeepMind shows major breakthrough in physical science
-
As measured by PapersWithCode, the repo volume created by JAX frameworks has grown from 1% to 5% per month.
-
A new AlamosGold-focused research company is launched with significant backing and a roadmap that focuses on a vertical sector (eg developer tools, life sciences).

02Investigation research
2021 predictions: DeepMind's breakthroughs in physical science (1/3)
In 2021, we predict: "DeepMind released a major research breakthrough in the physical sciences. Since then, the company has made major advances in mathematics and materials science."
One of the defining moments in mathematics is formulating a conjecture or hypothesis about the relationship between variables of interest. This is usually achieved by observing a large number of instances of the values of these variables, and possibly using a data-driven approach to guess generation. But they are limited to low-dimensional, linear and generally simple mathematical objects.
In an article in Nature, researchers at DeepMind propose an alternative workflow involving mathematicians and a supervised ML model (typically a NN). Mathematicians assume a function involves two variables (input X() and output Y()). A computer generates a large number of variable instances and data for a neural network fit. Gradient saliency methods are used to determine the most relevant inputs in X >. Mathematicians can then refine their hypotheses and/or generate more data until the conjecture holds on a large amount of data.

2021 predictions: DeepMind's breakthroughs in physical science (2/3)
In 2021, it was predicted: "DeepMind released a major research breakthrough in the physical sciences." Since then, the company has made major advances in mathematics and materials science.
Researchers at DeepMind, working with mathematics professors at the Universities of Sydney and Oxford, used their framework (i) to come up with an algorithm that could solve a 40-year-old conjecture in representation theory.
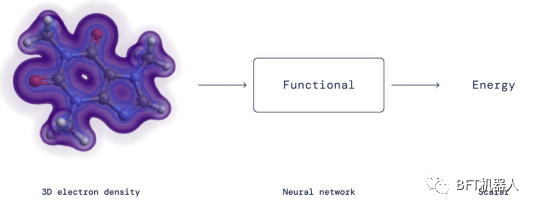
DeepMind has also made important contributions in materials science. The results show that the exact functional in density functional theory is an important tool to calculate electron energy, and it can be approximated efficiently by neural network. It is worth noting that the researchers did not constrain the neural network to verify the mathematical constraints of the DFT function, but only incorporated them into the training data suitable for the neural network.

2021 predictions: DeepMind's breakthroughs in physical science (3/3)
In 2021, we predict: "DeepMind publishes a major research breakthrough in the physical sciences." Since then, the company has made major advances in mathematics and materials science
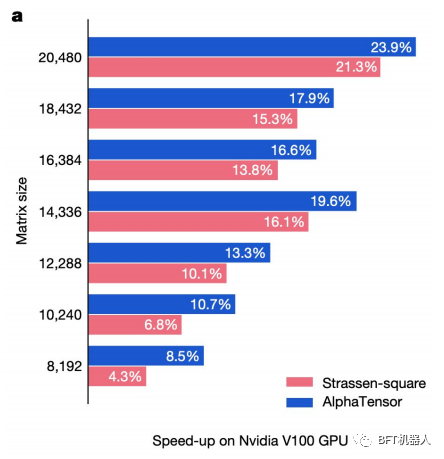
DeepMind repurposed AlphaZero (their RL model trained to beat the best human players in chess, go, and shogi) to do matrix multiplication. This AlphaTensor model is able to find new deterministic algorithms to multiply two matrices. To use AlphaZero, the researchers reformulated the matrix multiplication problem as a single-player game, where each step corresponds to an algorithmic instruction, and the goal is to zero a tensor to measure the correctness of the predictive algorithm.
Finding faster algorithms for matrix multiplication, a deceptively simple and well-studied problem, has been trite for decades. DeepMind's approach has not only helped to accelerate research in this field, it has also advanced techniques based on matrix multiplication, namely artificial intelligence, imaging, and everything that happens on mobile phones.
Reinforcement learning could be a core component of the next nuclear fusion breakthrough
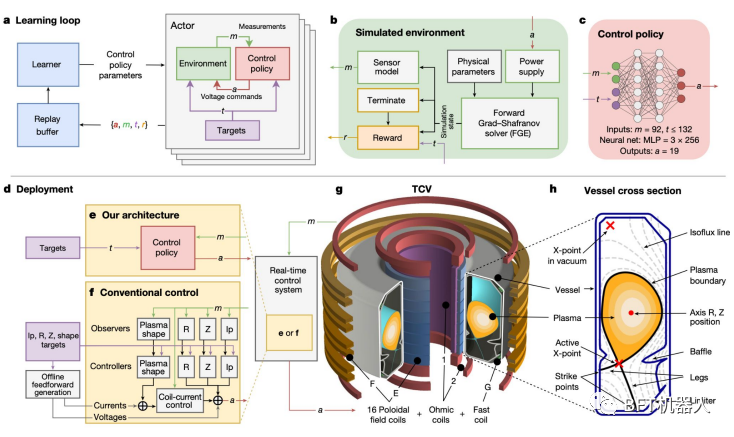
DeepMind trained a reinforcement learning system to tune the magnetic coils of the Lausanne TCV (variable configuration tokamak). The system's flexibility means it could also be used in ITER, the next-generation tokamak being built in France.
A popular route to nuclear fusion is to use a tokamak to confine an extremely hot plasma for a long enough time.
A major hurdle is that the plasma is unstable, losing heat and degrading materials when it hits the walls of the tokamak. Stabilizing it requires adjusting the magnetic coils thousands of times per second.
DeepMind's deep RL system did just that: first in a simulated environment and then deployed at the TCV in Lausanne. The system is also capable of shaping the plasma in new ways, including making it compatible with ITER's design.
Predicting the structure of the entire known proteome: what unlocks next?
Since being open-sourced, DeepMind's AlphaFold2 has been used in hundreds of research papers. The company has now deployed the system to predict the three-dimensional structures of 200 million known proteins from plants, bacteria, animals and other organisms. Downstream breakthroughs enabled by this technology -- from drug discovery to basic science -- will take years to materialize.
Today, there are 190,000 empirically determined 3D structures in the protein database. These were obtained by X-ray crystallography and cryo-electron microscopy.
· AlphaFoldDB released 1M predicted protein structures for the first time in July 2022.
The database size of this new version is 200x. More than 500,000 researchers from 190 countries have used the database.
The number of mentions of AlphaFold in the AI research literature is growing significantly and is expected to triple every year (right chart).
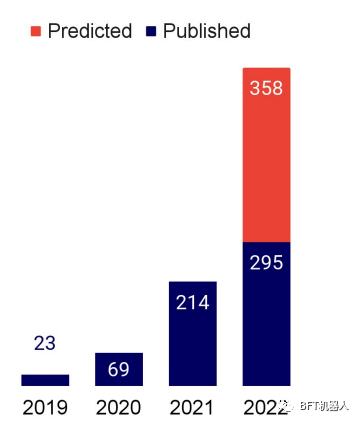
Language Models for Proteins: A Familiar Story of Open Source and Scaled Models
The researchers independently applied language models to protein generation and structure prediction problems, while calibrating model parameters. They all reported substantial benefits from scaling their models.
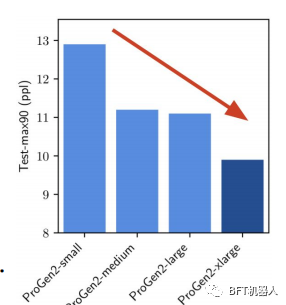
Salesforce researchers found that extending the LM allowed them to better capture the training distribution of protein sequences. Using the 6B parameter ProGen2, they generated proteins with similar folds to native proteins, but with sequences that displayed a different identity. However, to unlock the full potential of scale, the authors insist that more emphasis should be placed on data distribution.
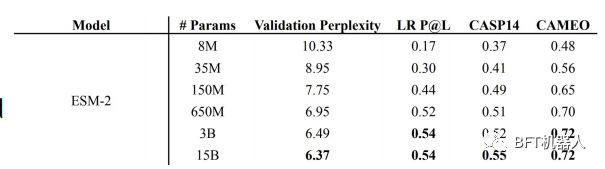
superpowers etc. The ESM family of protein LMs ranging in size from 8M to 15B (termed ESM-2) parameters are introduced. Using ESM-2, they constructed ESMFold to predict protein structures. They showed that ESMFold produced predictions similar to ALphaFold2 and RoseTTAFold, but an order of magnitude faster.
This is because ESMFold does not rely on the use of multiple sequence alignments (MSA) and templates, such as AlphaFold2 and RoseTTAFold, but only uses protein sequences.
OpenCell: Understanding protein localization with the help of machine learning
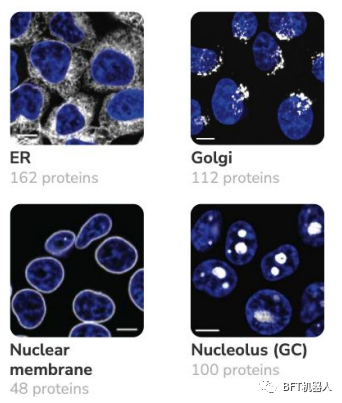
Researchers use CRISPR-based endogenous markers to modify genes to determine the localization of proteins in cells by elucidating specific aspects of protein function. They then used clustering algorithms to identify protein communities and formulate mechanistic hypotheses about uncharacterized proteins.
An important goal of genomic research is to understand where proteins are located and how they interact in cells to achieve specific functions. The OpenCell initiative has a dataset of 1,310 labeled proteins in approximately 5,900 3D images, enabling researchers to map important links between proteins' spatial distribution, function, and interactions.
Markov clustering of protein interactions on a graph successfully delineated functionally related proteins. This will help researchers better understand hitherto uncharacterized proteins.
We often expect ML to provide unambiguous predictions. But here as in mathematics, machine learning first gives a partial answer (here, clustering), then humans interpret, formulate and test hypotheses, and finally give a definitive answer.
Plastic recycling gets much-needed ML engineered enzyme
Researchers from UTAustin have designed an enzyme that can degrade PET, a plastic that accounts for 12 percent of the world's solid waste.
The PET hydrolase, called Fast PETase, is more active than existing enzymes to different temperatures and pH values.
FAST-PETase was able to almost completely degrade 51 different products within 1 week.
They also showed that they could resynthesize PET from monomers recovered from FAST-PET enzymatic degradation, which could open the way for closed-loop PET recycling on an industrial scale.


Beware of complex errors.
As ML is used more and more in quantitative science, methodological errors in ML may leak into these disciplines. Princeton researchers warn that the growing reproducibility crisis in machine learning-based science is due in part to one such methodological error: data leakage.
Data leakage is an umbrella term that covers all situations where data that should not be available to the model is actually available. The most common example is when the test data is included in the training set. However, leakage can be even more harmful when the features used by the model are proxies for the outcome variable, or when the test data come from a different distribution than the science claims.
The authors argue that the failure of reproducibility in the science of backbone machine learning is systemic: they looked at 20 reviews in 17 scientific fields, examined the science of base machine learning for errors, and found that in every one of the 329 reviews, data leakage errors have occurred. Inspired by the increasingly popular model cards in ML, the authors recommend that researchers use model information sheets designed to prevent data leakage problems.

OpenAl uses Minecraft as a testbed for computer use agents
OpenAl trained a model (Video PreTraining, VPT) to play Minecraft from video using a small number of labeled mouse and keyboard interactions. VPT is the first machine learning model to learn to make diamonds, "a task that typically takes a skilled human more than 20 minutes (24,000 operations).
OpenAl collected 2,000 hours of video labeled with mouse and keyboard actions and trained an inverse dynamics model (IDM) to predict past and future actions—this is the pre-training part.
They then used IDM to label 70 hours of video, on top of which they trained a model to predict actions based only on past videos.
The results show that the model can fine-tune the (a) model with simulation learning and reinforcement learning (RL) to achieve performance that is difficult to use RL from scratch.

Corporate AI labs scramble to get into AI for code research
OpenAl's Codex, which drives GitHub Copilot, has impressed the computer science community with its ability to complete code on multiple lines of code or directly from natural language instructions. This success has spurred more research in this area, including from Salesforce, Google, and DeepMind.
· With conversational CodeGen, Salesforce researchers can leverage the language understanding capabilities of LLM to specify coding requirements in multi-turn language interactions. It is the only open source model that competes with Codex.
An even more impressive achievement is Google's LLMPaLM, which achieves similar performance to Codex but with 50x less code in its training data (PaLM was trained on a larger non-code dataset). When fine-tuning Python code, PaLM outperforms its counterparts on SOTA (82% vs 717%) on Depfix, a code repair task.
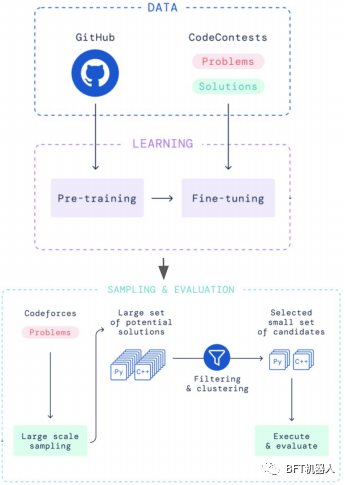
DeepMind's AlphaCode tackles a different problem: generating entire programs in a competitive programming task. It ranked in the top half of Codeforces, a coding competition platform. It is pre-trained on GitHub data and fine-tuned on Codeforces problems and solutions. Millions of possible solutions are then sampled, filtered and clustered to obtain 10 final candidates.
Five years after Transformer, there must be some efficient alternatives.
The attention layer at the heart of the Transformer model is known for its quadratic dependence of inputs. A plethora of papers promise to solve this problem, but do nothing.
SOTALLM comes in different flavors (autoencoder, autoregressive, encoder-decoder), but all rely on the same attention mechanism.
Over the past few years, a fleet of Googol transformers has been trained, costing millions and billions?) to labs and companies around the world. But the so-called "Efficient Transformers" (EfficientTransformers) are not found in large-scale LM studies (they make the biggest difference!) GPT-3PaLMLaMDA, Gopher, OPT, Bloom, GPT-Neo giant electron - Turing-NLG, GLM-130B, etc. all use primitive attention layers in their transformers.
There are several reasons for this lack of adoption: (i) the potential linear speedup only applies to large input sequences, (ii) the new method introduces additional constraints that make the architecture less general, (ii) the reported efficiency measures Does not translate into actual computational cost and time savings.

Mathematical capabilities of language models far exceed expectations
Based on Google's 540B parameter LM PaLM, Google's Minerva achieved a score of 503% on the math benchmark (43.4% higher than the previous SOTA), surpassing the forecasters' best score in 2022 (13%). Meanwhile, OpenAl trained a network to solve two Mathematical Olympiad problems (IMO).
Google uses LaTeX and MathJax to train its (pretrained) LLM PaLM using an additional 118GB dataset of scientific papers from arXiv and the web. By using other techniques such as thought-chain hints (including intermediate reasoning steps in hints rather than just the final answer) and majority voting, Minerva improves SOTA by at least double-digit percentages on most datasets.
Minerva only uses language models and does not explicitly encode formal mathematics. It's more flexible, but only automatically evaluates its final answer, not its entire reasoning, which may justify some score inflation. In contrast, OpenAl builds a (transformer-based) theorem prover in a lean formal environment. Different versions of their model are able to solve some problems in AMC12(26), AIME(6) and IMO(2) (in order of increasing difficulty).

For more exciting content, please pay attention to the official account: BFT Robot
This article is an original article, and the copyright belongs to BFT Robot. If you need to reprint, please contact us. If you have any questions about the content of this article, please contact us and we will respond promptly.