In machine learning problems, overfitting is a very common problem. Overfitting refers to the state of being able to fit only the training data, but not well fitting other data not included in the training data. The goal of machine learning is to improve the generalization ability, and it is hoped that the model can correctly identify even unobserved data that is not included in the training data .
There are two main reasons for overfitting:
- The model has a large number of parameters and is highly expressive.
- Less training data.
So how to suppress overfitting? Regularization
is one of the effective methods. It can not only effectively reduce high variance, but also help reduce bias. What is regularization? In machine learning, many strategies that are explicitly used to reduce test error are collectively referred to as regularization . Regularization aims to reduce generalization error rather than training error.
Here are a few pictures related to regularization
Weight decay
Weight decay is a method that has been often used to suppress overfitting. This method suppresses overfitting by penalizing large weights during learning . A lot of overfitting originally happened because the value of the weight parameter was too large.
As a refresher, the learning goal of a neural network is to reduce the value of the loss function. At this time, for example, the square norm (L2 norm) of the weight is added to the loss function. In this way, the weight can be suppressed from becoming large.
When implementing L2 regularization, the expression of Ω(w) is:
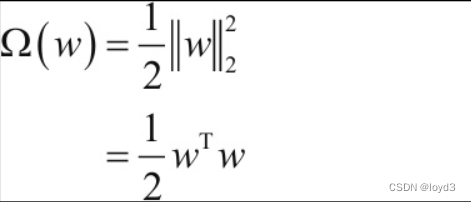
In terms of symbols, if the weight is recorded as, the weight decay of the L2 norm is 1 2 \frac{1}{2}21 λ \lambdaλ W 2 W^{2} W2 , and then this1 2 \frac{1}{2}21 λ \lambdaλ W 2 W^{2} W2 is added to the loss function. Here,λ \lambdaλ is a hyperparameter that controls the strength of regularization. The larger the setting, the heavier the penalty imposed on large weights. Also, the first half is used to convert1 2 \frac{1}{2}21 λ \lambdaλ W 2 W^{2} WThe result of derivation of 2
becomes λ \lambdaλ W 2 W^{2} W2 For all weights, the weight decay method will add1 2 \frac{1}{2}21 λ \lambdaλ W 2 W^{2} W2 . Therefore, in the calculation of the weight gradient, it is necessary to add the derivative of the regularization termλ \lambdaλ W 2 W^{2} W2
The L2 norm is equivalent to the sum of squares of each element
The implementation code of weight decay is as follows:
def loss(self, x, t):
y = self.predict(x)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decay
The core part of the experimental code is the weight_decay_lambda parameter added to the MultiLayerNet class, the code is as follows:
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10,
weight_decay_lambda=weight_decay_lambda)
The other parts are not much different from other experimental codes.
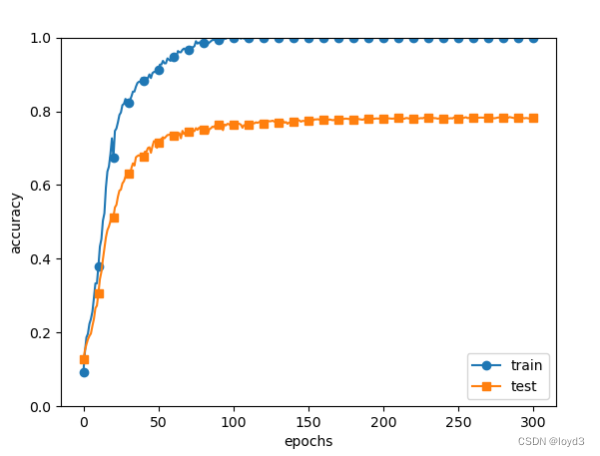
The results obtained are as follows:
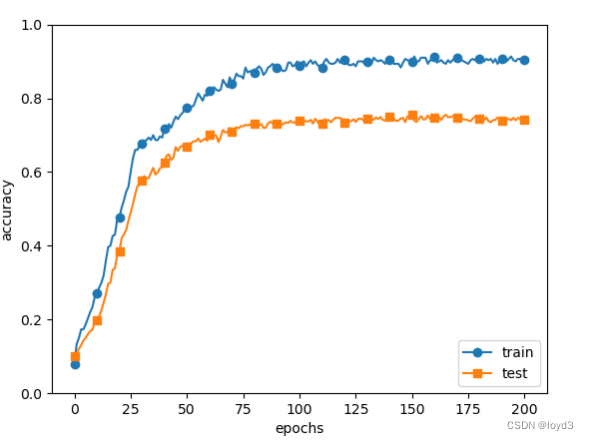
Although there is a gap between the recognition accuracy of the training data and the recognition accuracy of the test data, compared with the result without weight decay, the gap becomes smaller. This shows that overfitting is suppressed. In addition, it should also be noted that the recognition accuracy of the training data did not reach 100%.
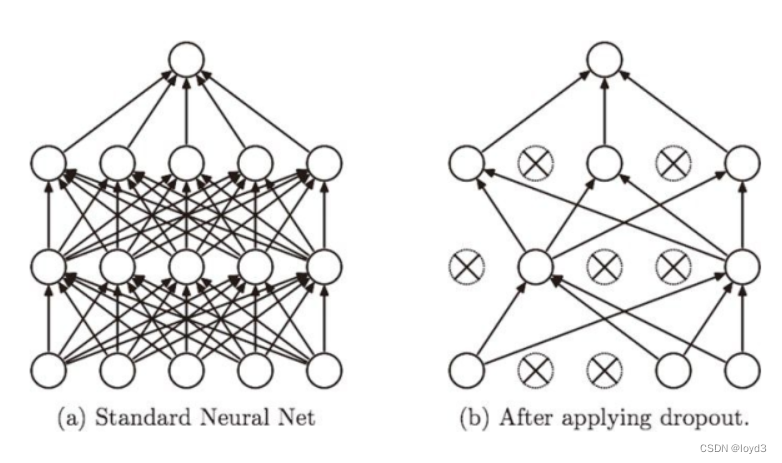
Dropout Dropout is a method of randomly deleting neurons
during the learning process . During training, neurons in the hidden layer are randomly selected and then deleted. Deleted neurons no longer transmit signals. During training, each time the data is passed, the neuron to be deleted will be randomly selected. Then, during the test, although all neuron signals will be transmitted, the output of each neuron must be multiplied by the deletion ratio during training before output .
For the implementation of Dropout, please refer to the implementation in Chainer
class Dropout:
def __init__(self,dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg = True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
The point here is that each time the forward pass is made, the deleted neurons are saved as False in self.mask. setf.mask will randomly generate an array with the same shape as x, and set elements with values larger than dropout_ratio to True . The behavior during backpropagation is the same as ReLU. That is to say, neurons that transmit signals during forward propagation will transmit signals as they are during backpropagation ; neurons that do not transmit signals during forward propagation will stop there during backpropagation.
Now, we use the MNIST dataset for verification, the code is as follows:
# 省略import代码
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了再现过拟合,减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]
# 设定是否使用Dropuout,以及比例 ========================
use_dropout = True # 不使用Dropout的情况下为False
dropout_ratio = 0.2
# ====================================================
# 在MultiLayerNetExtend中设置是否使用Dropuout
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],output_size=10,
use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={
'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
# 省略绘图代码
The Trainer class is used in the test code to simplify the implementation
The following are the test results:
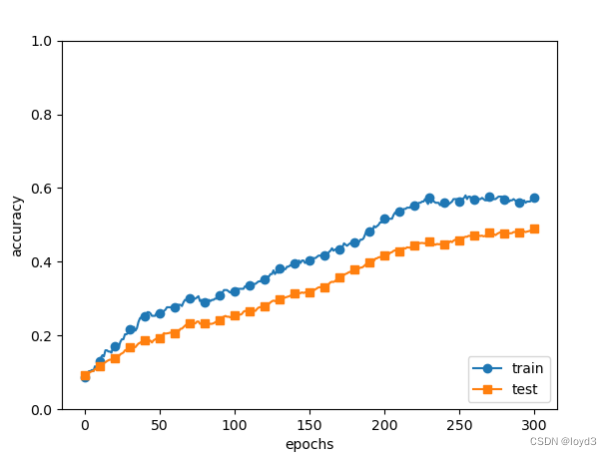
Compared with the one without Dropout
, the difference in recognition accuracy between training data and test data becomes smaller by using Dropout. Moreover, the training data did not reach 100% recognition accuracy. Like this, by making dropout possible, overfitting can be suppressed even for expressive networks.
Dropout can be understood as letting a different model learn each time by randomly deleting neurons during the learning process . In addition, during inference, the average value of the model can be obtained by multiplying the output of the neuron by the deletion ratio (for example, 0.5, etc.) . In other words, it can be understood that Dropout realizes the effect of integrated learning (simulated) through a network.
How or when to use Dropout? The following are general principles to use:
- Usually it is better to control the discard rate between 20% and 50%, and you can start trying from 20%. If the ratio is too low, it will not be effective, and if the ratio is too high, it will lead to under-learning of the model.
- Applied on large network models. When Dropout is used in a larger network model, it is more likely to be improved, and the model has more opportunities to learn multiple independent representations.
- Dropout is used in both input and hidden layers. For different layers, the set keep_prob is also different. Generally speaking, for layers with fewer neurons, keep_prob will be set to 1.0 or a number close to 1.0; for layers with more neurons, keep_prob will be set smaller, such as 0.5 or less.
- Increase learning rate and momentum. Increase the learning rate by 10 to 100 times, and increase the impulse value to 0.9 to 0.99 .
- Limit the weights of the network model . Large learning rates often lead to large weight values. Regularizing the weight value of the network with the maximum norm can improve the performance of the model.