Regularization
regularized meaning
Regularization is used to reduce network overfitting and reduce fitting error. The regularization operation is to add an additional item after the original loss function 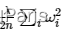 , which can constrain the weight of the model. A larger value will constrain the weight of the model to a greater extent, and vice versa. Usually, we only penalize the weight w, but not b, because w has many parameters, and b has only one, and penalizing b has little effect on the result, so it is usually ignored.
, which can constrain the weight of the model. A larger value will constrain the weight of the model to a greater extent, and vice versa. Usually, we only penalize the weight w, but not b, because w has many parameters, and b has only one, and penalizing b has little effect on the result, so it is usually ignored.
regularization formula
The regularization formula is as follows, the first item is the cross-entropy loss, and the latter item is the penalty item, which is an additional item added to the regularization operation. This formula is also called L2 regularization, because the penalty term uses the L2 norm, which is the sum of the squares of all weights. There is also L1 regularization, that is, the penalty item adopts the L1 norm, and the L1 norm is the sum of all weights. At present, L2 regularization is usually used.
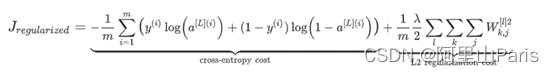
Regularization can reduce the cause of overfitting
Assuming that λ becomes infinite, then the weight w tends to 0, and most of the neurons are equivalent to no effect, then the neural network tends to become logistic regression, then the deep learning network changes from overfitting to underfitting , therefore, after adding an appropriate penalty term, the purpose of weight decay can be achieved when the parameters are updated. Weight attenuation means that the attenuated neurons have less influence on the neural network, making the original complex neural network simpler and finally reaching an optimal fitting state.
Dropout regularization
Dropout regularization can also reduce overfitting
Dropout regularization is also called random deactivation regularization, usually we use Inverted (reverse) Dropout. It means that during the training process of the deep learning network, for the neural network unit, it is temporarily discarded from the network according to a certain probability.
An important parameter in Dropout regularization is keep_drop. If keep_drop=0.8, you need to discard 20% of the nodes and only keep 80% of the nodes. If keep_drop=1, you will keep all of them, which is equivalent to not using Dropout regularization.
Since Dropout regularization is added, it will not show a monotonous downward trend like L2 regularization. Therefore, in the actual application process, we usually set keep_drop to 1 first to see if the loss is monotonous. Adjust the L2 regularization before Change keep_drop.
Why Dropout can reduce overfitting
The following content is quoted from:
Author: zzkdev
Link: https://www.jianshu.com/p/257d3da535ab
Source: Jianshu
"Because each time the weight value is updated with the samples input into the network, the hidden nodes are based on a certain probability Appears randomly, so it cannot be guaranteed that every 2 hidden nodes appear at the same time every time, so that the update of the weight no longer depends on the joint action of hidden nodes with a fixed relationship, preventing certain features from being only available under other specific features In the case of the effect, reduce the complex co-adaptability between neurons.
Since nodes are randomly deleted each time, the output of the next node is no longer so dependent on the previous node, that is to say, it will not give the previous node when assigning weights. A certain node on the first layer is not assigned too much weight, which plays a role similar to L2 regularization compression weight.
Dropout can be regarded as a kind of model averaging, averaging a large number of different networks. Different networks are in different In the case of over-fitting, although different networks may have different degrees of over-fitting, sharing a loss function is equivalent to optimizing it at the same time and taking the average, so it can effectively prevent over-fitting The occurrence of combination. For each sample input into the network (maybe a sample or a batch sample), the corresponding network structure is different, but all these different network structures share the hidden Including node weights, this average architecture is often found to be very useful to reduce overfitting methods."
data augmentation
Including flipping, mirroring, partial enlargement, partial reduction, distortion, etc.
Early stopping (early stopping mechanism)
After each epoch (or after every N epochs): Obtain the test results on the verification set. As the epoch increases, if the test error is found to increase on the verification set, stop the training; use the weight after the stop as the network final parameter. The general practice is to record the best accuracy of the verification set so far during the training process. When the best accuracy is not reached for 10 consecutive Epochs (or more), it can be considered that the accuracy will no longer improve.
Its shortcoming is that it does not take different ways to solve the two problems of optimizing the loss function and reducing the variance, but uses one method to solve the two problems at the same time, and the result is that the things to be considered become more complicated. The reason why it can't be handled independently is because if you stop optimizing the cost function, you may find that the value of the cost function is not small enough, and at the same time you don't want to overfit.