The Evolution of Microservice Architecture
Monolithic application stage
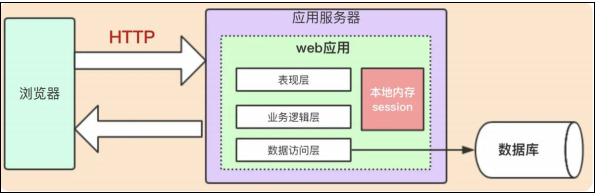
Features of a monolithic application
The number of requests that can be accommodated is limited (the server's memory and CPU configuration are limited)
The presentation layer, control layer, and persistence layer are all in one application, which is convenient and fast to call. Fast response to a single request
Easy to develop, quick to use, recommended for teams of three or five
Vertical application stage
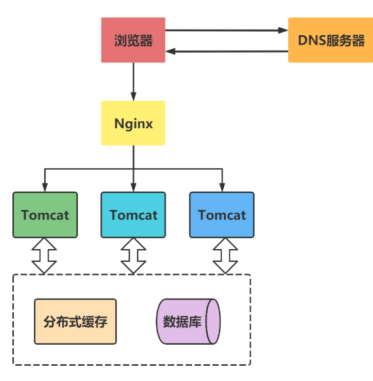
The ability and capacity to handle concurrent requests is enhanced, but the processing speed of a single request is reduced.
distributed system stage
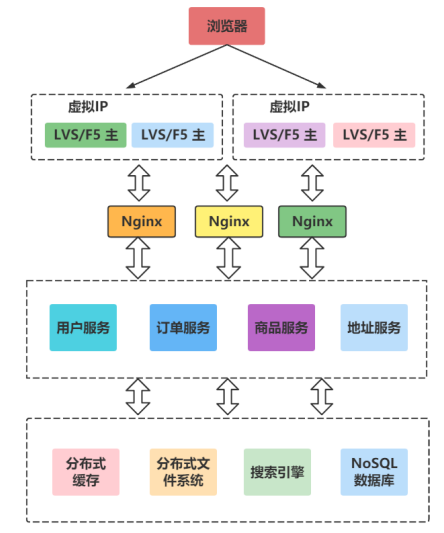
Phases of Service Governance (SOA)
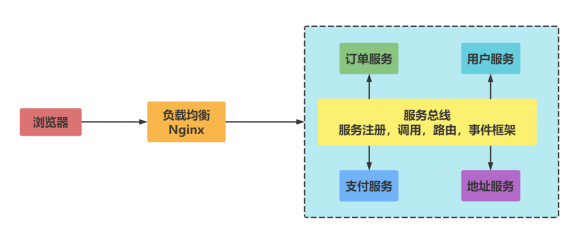
The problems existing in the distributed system can be solved through the basic service of service governance. With the continuous increase of the number of services, resource waste and scheduling problems in the service are aggravated, and a scheduling center needs to be added to manage the service. The call center can manage the capacity of the cluster in real time based on the access pressure, thereby improving the utilization of the cluster. "In the service governance architecture, an enterprise service bus (ESB) is needed to connect service nodes based on different protocols, and its job is to convert, interpret messages and route."
Microservice stage
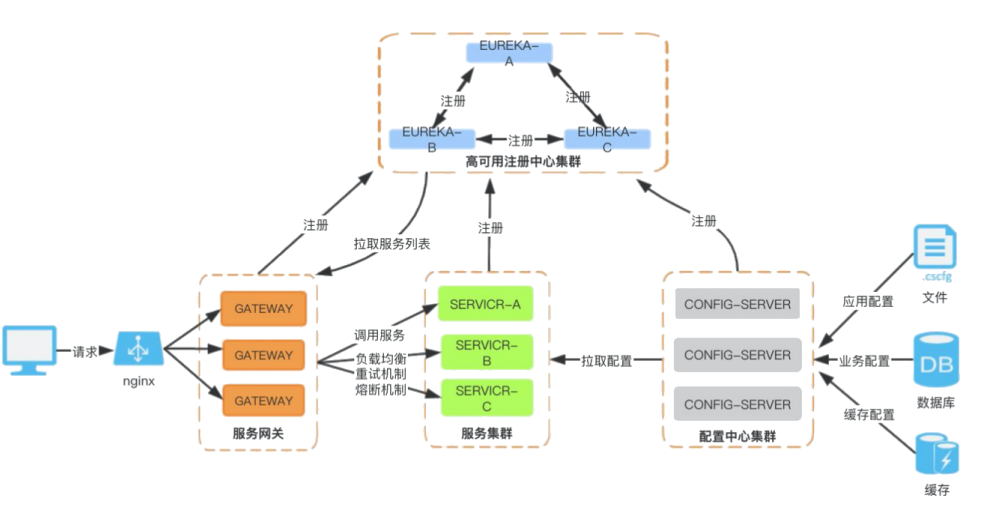
Divide the business functions of the system into extremely small independent microservices, and each microservice only focuses on completing a small task. A single microservice in the system can be independently deployed and expanded, and each microservice is highly cohesive and low-coupling. The lightweight communication mechanism is exposed between microservices to achieve communication.
component explanation
- Service Gateway: Reception, Spring Cloud Gateway.
- Circuit breaker mechanism: when to provide what, and the amount provided.
- Work efficiency supervision: workflow content, duration supervision, what link went wrong, Sleuth, log monitoring ELK, etc.
- Configuration center: menu (various cuisines)
- Service cluster: microservice cluster, each service
- High-availability registration center: lobby manager, the person in charge has gone to work, where does he work and what does he do
Specifications and principles of microservice splitting
Stress model split
Simply speaking, the pressure model is the number of user visits. We need to identify certain businesses with a very high concurrency and split them as much as possible.
The pressure model splits into three dimensions
High Concurrency Scenario
For example, the product details page is not only a high-frequency scene but also a high-concurrency scene (QPS is extremely high)
Low frequency burst scene
For example, the seckill scenario (occasionally) will cause a burst of large traffic
Low-frequency traffic scenarios
The service interface of the background operation team, such as editing product graphics, adding new discount calculation rules, and launching new products. It occurs less frequently and does not cause high concurrency
Business model split
There are many dimensions of business model splitting. In practice, the application integrates various dimensions for consideration. There are mainly three dimensions (main link, domain model, and user groups).
main link split
The "main link" in the e-commerce field is a crucial business chain, which refers to the scene that users must go through to complete the order scene. Such as product search -> product details page -> shopping cart module -> order settlement -> payment business.
Purpose of core business split
Abnormal fault tolerance: establish a hierarchical degradation strategy (multi-level degradation) for the main link, and a reasonable fuse strategy.
Resource allocation: The main link is usually a high-frequency scenario, which is reflected in the cluster with the largest number of virtual machines allocated
Service isolation: isolate the main link from other auxiliary services to prevent abnormalities of edge services from affecting the main link
domain model split
Segmentation of user groups
The user group is equivalent to a second-level domain. We recommend first splitting the first-level domain based on the main link and domain model, and then combining specific business analysis to see if a finer-grained split is required in the direction of the user domain.
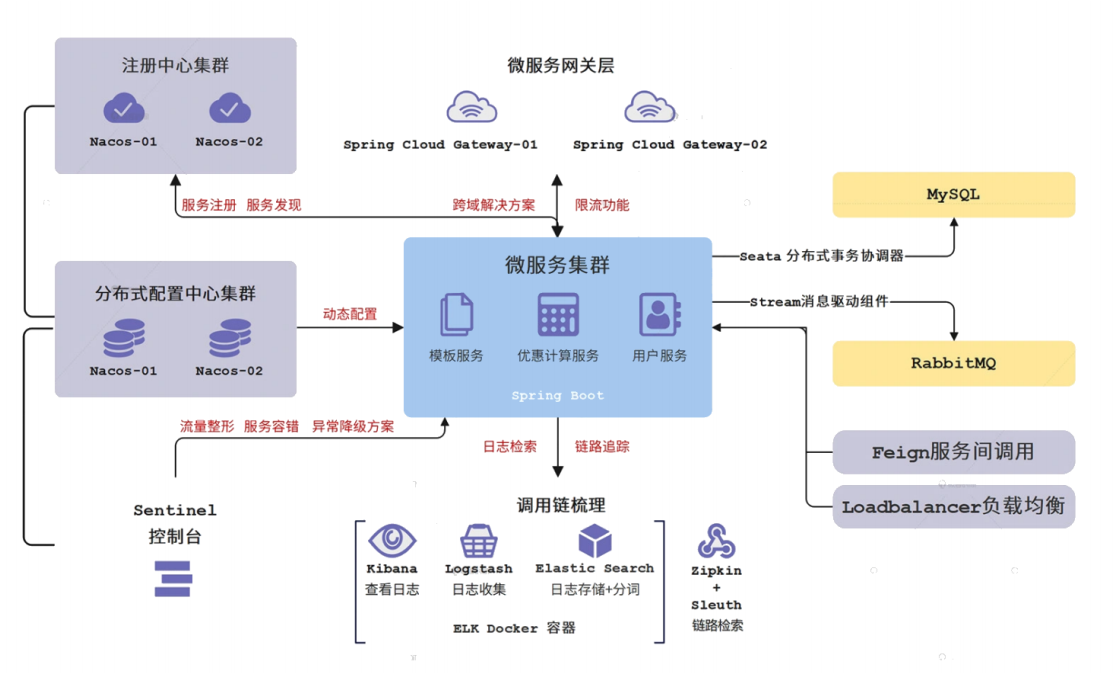
SpringCloud
SpringCloud is a microservice architecture development tool based on SpringBoot. It provides a simple development method for operations such as configuration management, service governance, circuit breaker, intelligent routing, control bus, distributed session and cluster state management involved in the microservice architecture.
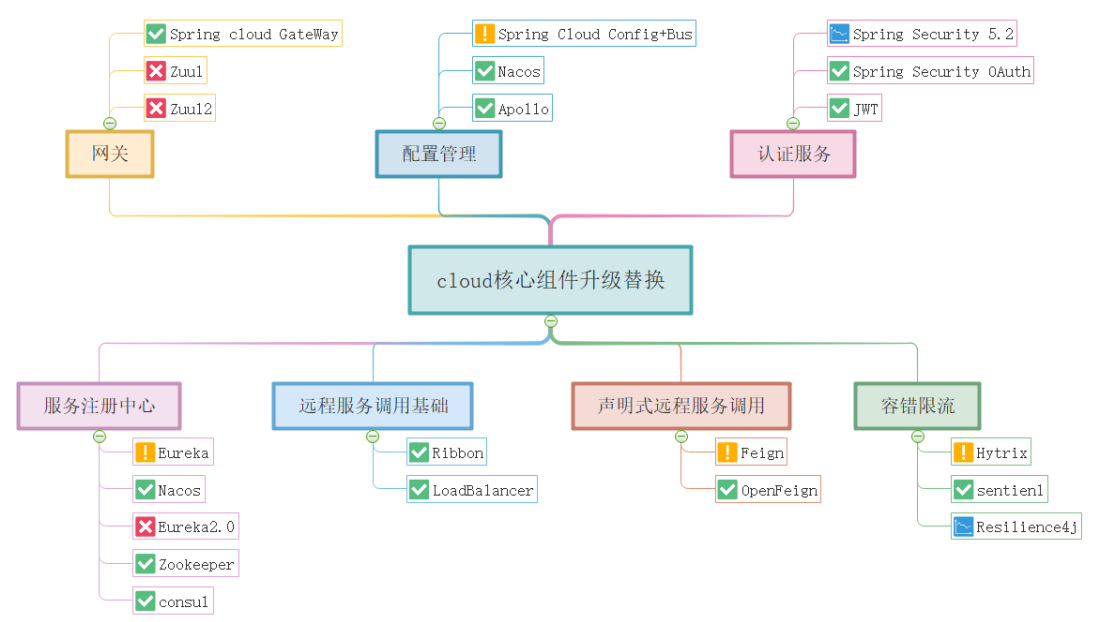
Service Registration Selection
- Eureka: The eldest son of SpringCloud and Netflix
- Nacos: A rising star, the children of other people’s families in the eyes of SpringCloud have been included in the scope of adoption (SpringCloud Alibaba Incubation Project)
- Apache Zookeeper: Relational, better relationship with Hadoop
- etcd: relational account, better relationship with kubernetes
- consul: relational account, used to have a good relationship with docker
If Hadoop, kubernetes, Docker, etc. have been used in the project, other components can be considered in the SpringCloud implementation process to avoid building two sets of registration centers and wasting resources
Distributed configuration management
At present, the optional distributed configuration management centers include Ali's Nacos, Ctrip's Apollo, and SpringCloud Config
service gateway
It is recommended to use SpringCloud GateWay, which is better than Zuul in all aspects
Fuse current limit
Hystrix
In December 2018, Spring officially announced that Netflix-related projects have entered maintenance mode and no new features will be developed, but Hystrix is relatively stable overall.
resilience4j
After Hystrix stopped updating, NetFlix officially recommended the use of resilience4j, which is a lightweight, easy-to-use, and assembleable high-availability framework that supports multiple high-availability mechanisms such as fusing, high-frequency control, isolation, current limiting, and retrying. .
Sentinel
Sentinel is open sourced by the Alibaba middleware team. It is a lightweight and highly available traffic control component for distributed service architecture. It mainly uses traffic as the entry point to help users protect services from multiple dimensions such as vagrant control, circuit breaker degradation, and system load protection. stability.
Feature Summary
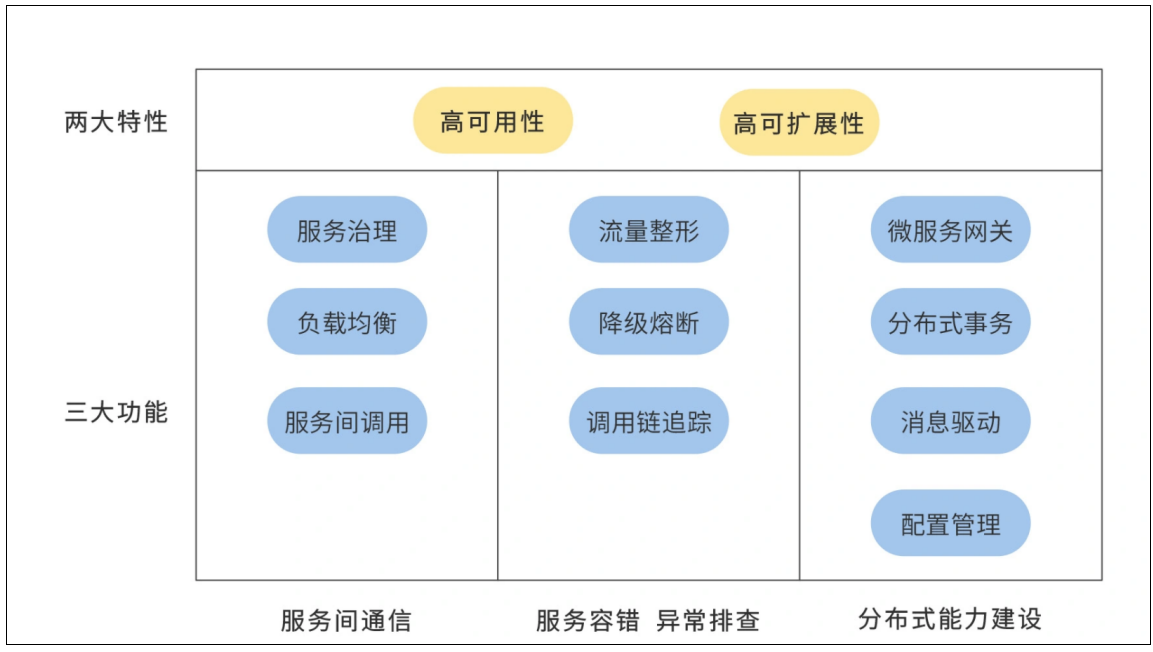
The three major functions refer to the functional dimensions of the core components of microservices, which are progressive from shallow to deep; the two major features are high availability and high scalability built on top of each service component.
Service Registry Discovery and Governance
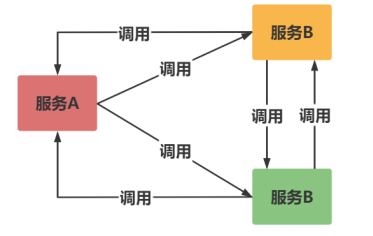
Before service governance, the communication between services is realized by calling each other directly between services.
There are many services in the microservice system, which will make it inconvenient to call each other between services. It is necessary to remember the IP, name, port, etc. of the services provided.
Responsibility for Service Governance
- who: service registration - service provider self-report
- where: service discovery - service consumers pull registration data
- how: Heartbeat detection, service renewal and service elimination are a set of processes that are completed by the cooperation of the service provider and the registration center
- leave: service offline - the service provider initiates an active offline
Service registration discovery Eureka
Eureka is a registration discovery package developed by Netflix. It is a REST-based service that not only provides registration discovery, but also provides load balancing and failover capabilities.
Service center-service provider-service consumer (three roles)

Eureka Server: server-side, provides service registration and discovery functions, and implements service governance
Service Provider: The service provider, which registers its own services into Eureka Server, so that service consumers can call through the service list (registered service list) provided by the server
Service Consumer: service consumer. Obtain the registered service list from Eureka to realize service consumption
Comparison between Eureka and Zookeeper
Eureka is an AP architecture, and Zookeeper is a CP architecture.
The CAP principle, also known as the CAP theorem , refers to the consistency (Consistency), availability (Availability), and partition tolerance (Partition tolerance) in a distributed system, but the CAP principle indicates that the three elements can only achieve two points at the same time , it is impossible to take care of all three, because the network hardware will definitely have problems such as delay and packet loss, but in a distributed system, we must ensure that some network communication problems will not cause the entire server cluster to be paralyzed. In addition, even if it is divided into multiple areas, when When the network fault is eliminated, we can still ensure data consistency, so we must ensure partition fault tolerance;
As for the remaining consistency and availability, we need to choose one of the two, but fish and bear's paw cannot have both, assuming we choose consistency, then we cannot allow users to access machines that cannot perform data synchronization. After all, the data on this machine It is inconsistent with other normal machines, but in this way we discard availability; assuming we choose availability, then we can allow users to access servers that cannot perform data synchronization. Although availability is guaranteed, we cannot guarantee data consistency.
The AP structure chooses high availability and partition fault tolerance . At this time, the node that lost contact can still provide services to the system, but its data cannot be guaranteed to be synchronized (the C attribute is lost). Eureka is an example of an AP architecture. When the heartbeat of the Eureka client disappears, the Eureka server will start a self-protection mechanism, which will not eliminate the service of the EurekaClient client, and can still provide demand;
The CP structure chooses consistency and partition fault tolerance . If we choose consistency C (Consistency), in order to ensure the consistency of the database, we must wait for the lost node to recover. During this process, that node is not allowed to provide service, at this time the system is in an unavailable state (lost the A attribute). The best example is zookeeper. If the client's heartbeat disappears, zookeeper will quickly remove the service, and then it will not be able to provide demand;
Service Registry Discovery
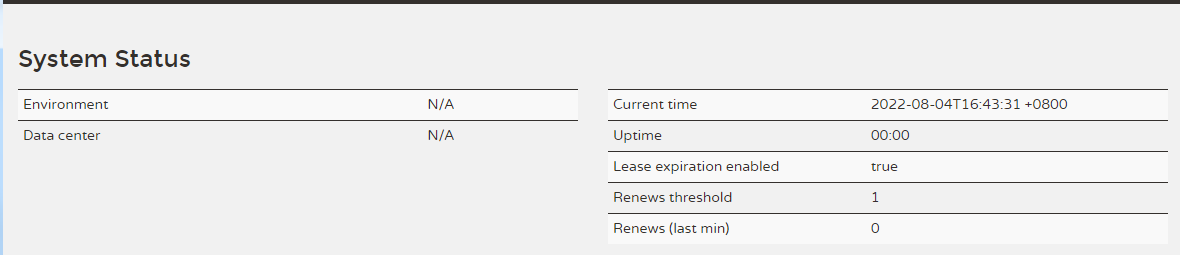
parameter
Environment: environment, the default is test, this parameter can not be changed during actual use
Data center **: The data center, using the default is ** "MyOwn"
Current time **: current system time **
Uptime **: How much time has been running**
Lease expiration enabled: Whether to enable lease expiration. When the self-protection mechanism is disabled, the value is true by default, and it is false after the self-protection mechanism is enabled.
Renews threshold: The minimum number of renewals per minute, Eureka Server expects to receive the total number of client instance renewals per minute.
Renews (last min): The number of renewals in the last minute (excluding the current one, updated every minute), the total number of renewals of client instances received by Eureka Server in the last minute.

parameter:
The following information is the adjacent nodes of this Eureka Server, which are a cluster of each other. Instance information registered to this service

- Application: Service name. The configured spring.application.name property. AMIs: n/a, the string n/a + the number of instances.
- Availability Zones: The number of instances.
- Status: The status of the instance + the value of eureka.instance.instance-id. The status of the instance is divided into UP, DOWN, STARTING,
OUT_OF_SERVICE, UNKNOWN. - UP: The service is running normally. In special cases, when entering the self-protection mode, all services are still in the UP state. Therefore, fault-tolerant mechanisms such as fusing and retrying need to be implemented to deal with catastrophic network errors.
- OUT_OF_SERVICE : no longer provide services, other Eureka
- The client will not be able to call the service, and it is generally set by an artificial call interface, such as: forced offline. UNKNOWN: Unknown status. STARTING: Indicates that the service is starting.
- DOWN: Indicates that the service has been down and cannot continue to provide services.
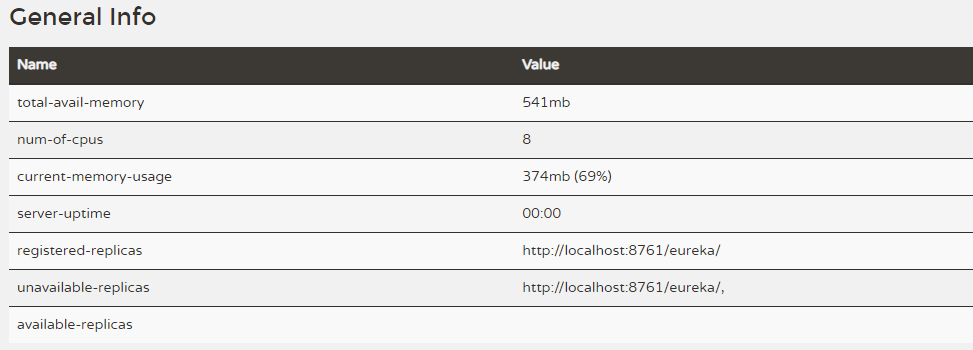
total-avail-memory : total available memory
environment : environment name, default test
num-of-cpus : the number of CPUs
current-memory-usage : the percentage of currently used memory
server-uptime : service startup time
registered-replicas : Adjacent cluster replication nodes
unavailable-replicas : Unavailable cluster replication nodes, how to determine unavailable? Mainly server1 to
server2 and server3 send interfaces to query their own registration information.
available-replicas : available adjacent cluster replication nodes
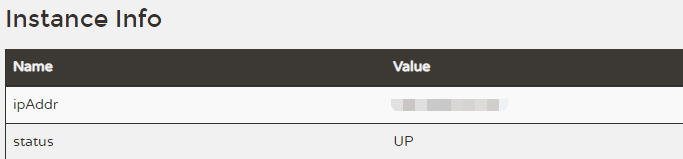
ipAddr: eureka server IP
status: eureka server status
Service self-protection and culling mechanism

Service self-protection and elimination cannot be used at the same time
service removal
Service removal removes the service node, even if the renewal request is sent, it is useless
Service self-insurance

Service self-insurance keeps all current nodes. In practical applications, not all services without heartbeat are unavailable. It may be due to short-term network jitter and other reasons that the service node and registration center cannot be renewed, but the call between service nodes is still available. At this time Forcibly removing service nodes may cause large-scale business stagnation.
The service self-insurance mode is to deal with short-term network environment problems. The renewal success rate of the ideal service node is 100%. If a sudden network problem occurs, such as some computer rooms cannot connect to the registration center, the success of contract renewal will be reduced. . Considering that Eureka adopts the service registration discovery mode of the client, the addresses of all the nodes of the client, if the service node cannot renew the contract due to network reasons, but its own service is available, then the client can still successfully initiate the call request, so that Avoid being killed by the service.
Service self-protection manual switch
Turn off the service protection mechanism, the default is true
eureka.server.enable-self-preservation : false
RestTemplate
RestTemplate is an HTTP request tool supported since Spring 3.0. It provides templates for common REST request schemes, such as GET, POST, PUT, DELETE requests, and some common request methods exchange and execute.
@Configuration
public class CloudConfig{
@LoadBalanced
@Bean
public RestTemplate restTemplage(){
return new RestTemplate();
}
}
//测试Controller
@RestController
@RequestMapping("/test")
public class TestRestController{
//HTTP请求工具
@Autowired
private RestTemplate restTemplate;
@GetMapping("/index")
public String index(){
//1.远程调用方法的主机
//Stringhost="http://localhost:1000";
//将远程微服务调用地址从"IP地址+端口号改成"微服务名称""
String host = "http://xxx.xx.xx"; 123456789
// 2. 远程调用方法具体URL地址
String url = "/payment/index";
// 3. 发起远程调用
//getForObject:返回响应体中数据转化成的对象,可以理解为json
//getForEntity:返回的是ResponseEntity的对象包含了一些重要的信息
String forObject = restTemplate.getForObject(host + url,String.class);
return forObject;
}
}
High availability registration center Eureka
In the microservice architecture based on SpringCloud, all microservices need to be registered to the registration center. If the registration center is blocked or collapsed, the entire system cannot continue to provide services normally, so here it is necessary to build high availability for the registration center ( HA) cluster.
The design of Eureka Server has considered the issue of high availability from the very beginning. In Eureka's service governance design, all nodes are service providers and service consumers, and the service registry is no exception.
Client load balancing
There are load balancing, server load balancing and client load balancing
Server load balancing
Set up a central load balancer, such as Nginx, within the service cluster. When an inter-service call is initiated, the service request is not sent directly to the target server but to the global load balancer, which then forwards the request to the target service according to the configured load balancing policy.
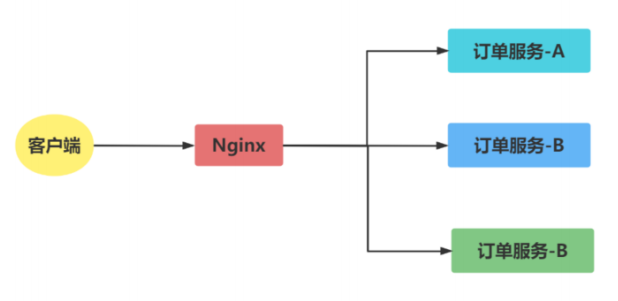
advantage:
Server-side load balancing has a wide range of applications. It does not rely on service discovery technology. The client does not need to pull the complete service list. At the same time, the client that initiates the service call does not need to worry about what load balancing strategy to use.
shortcoming:
Increased network consumption, complexity and failure rate
Client load balancing
Spring Cloud LoadBalaner
Spring Cloud LoadBalaner adopts client-side load balancing technology. Each client that initiates a service call has a complete list of target service addresses. According to the configured load balancing strategy, the client decides which server to call.
Advantages: small network overhead, simple configuration
Disadvantage: A precondition needs to be met. The client that initiates the service call needs to obtain the addresses of all target services, so that the load balancing rules can be used to select the called service. Client load balancing technology needs to rely on service discovery to obtain service list
Spring Cloud Ribbon
Ribbon is helpful for Http and TCP clients, and can automatically help consumers' requests according to the load balancing algorithm (polling, random or automatic). The default is polling
Ribbon has been stopped, alternative (Spring Cloud LoadBalancer)
Client load balancing strategy
- RandomRule - Do as you please
- RoundRobinRule - step by step (polling)
- RetryRule - comeback
- WeightedResponseTimeRule - Can do more work
- BestAvailableRule - let the least available
- AvailabilityFilteringRule - I have a bottom line
- ZoneAvoidanceRule - I call the shots on my territory
OpenFeign

Spring Cloud OpenFeign Declarative REST client for Springboot applications
The difference between OpenFeign and Feign
Feign is a declarative WebService client. Using Feign can make writing WebService clients easier (by defining a service interface and annotating it). Pluggable encoders and decoders are supported. Spring Cloud encapsulates Feign and supports SpringMVC standard annotations and HttpMessageConverters
OpenFeign log enhancements
OpenFeign provides log enhancements, the default is to display any log configurable
log level
NONE: no levels are displayed by default
BASIC: Only record the request method, URL, response status code
HEADER: In addition to the information defined in BASIC, there is also the header information of the request response
FULL: In addition to the information defined in the HEADER, the body and metadata of the request and response
@Configuration
public class OpenFeignConfig{
/**
* 日志级别定义
*/
//Logger包位于Feign
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
}
/**
配置文件配置接口日志级别
logging:
level:
com.service: debug #openfeign接口所在包名
*/
OpenFeign timeout mechanism
The service consumer is blocked and waiting when calling the service provider. At this time, the service consumer will wait forever. At a certain peak moment, a large number of requests are all requesting service consumers at the same time, which will cause a large number of threads to accumulate, which will inevitably cause an avalanche. Use the timeout mechanism to solve this problem, set a timeout period, within this period of time, if the service access cannot be completed, the connection will be automatically disconnected.
avalanche
Dependencies between services and services, faults will propagate, causing a chain reaction, which will have catastrophic consequences for the entire microservice system
reason:
- The service provider is unavailable (hardware failure, program error, cache breakdown, high volume of user requests).
- User retries, code logic retries.
- Service caller is unavailable (resource exhaustion due to synchronous wait).
service circuit breaker
Three solutions to the avalanche
service fuse
Fusing is like a fuse. When a service request is extremely concurrent, the server is overwhelmed, and the call error rate soars. When the error rate reaches a certain threshold, the service will be blown. After the circuit breaker, subsequent requests will no longer request the server to reduce the pressure on the server.
When the failure rate (such as a high failure rate due to network failure/timeout) reaches the threshold, the downgrade is automatically triggered, and the fast failure triggered by the fuse will perform a fast recovery.
service downgrade
Causes: Abnormal program operation, timeout, server fuse trigger, thread pool semaphore full
When the downstream service responds too slowly for some reason, the downstream service actively stops some less important services to release server resources and increase the response speed. When the downstream service is unavailable for some reason, the upstream actively invokes some local degradation logic to avoid lag and return quickly.
The server is busy, please try again later, do not make the client wait and return a friendly prompt.
service isolation
Avoid Interaction Between Services
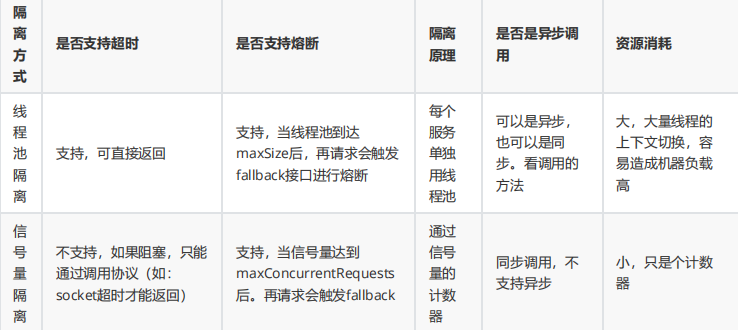
thread pool isolation
Separate user request threads and service execution threads, and agree on the maximum number of available threads for each service
Different http services use different thread pools. When their own resources are exhausted, they directly return failure without occupying other resources. Advantages:
can improve concurrency
Disadvantages: increase CPU scheduling overhead Usage
scenarios: third-party applications or interfaces; large amount of concurrency
Semaphore isolation
The atomic counter method records the number of currently running threads. If it exceeds, it will be rejected, if it does not exceed it, it will be +1, and if it returns, it will be -1. Usage scenarios: internal applications or middleware; the concurrent requirements are not large
Difference: The semaphore can be adjusted dynamically, but the thread pool cannot be adjusted
Service throttling
Both service fusing and service isolation are fault-tolerant mechanisms after an error occurs, while service current limiting is a preventive mechanism
The current limiting mode is mainly to set the highest QPS threshold for each type of request in advance. If it is higher than the set threshold, it will return directly and will not call subsequent resources.
The purpose of current limiting is to protect the system by limiting the speed of concurrent access/requests, or limiting the speed of requests within a time window. Once the speed limit rate is reached, the service can be refused, queued or waited, downgraded, etc.
flow control
Gateway current limiting: prevent a large number of requests from entering the system, MQ realizes peak elimination; user communication restrictions: submit button limit click frequency limit, etc.
Resilience4j
Resilience4j is a lightweight fault-tolerant component, mainly JAVA8 and functional programming design (Lambda), which are lightweight and now only use VAVR (formerly javaslang), without relying on any external components. Provides a series of usability-enhancing features for microservices:
- resilience4j-circuitbreaker: circuit breaker
- resilience4j-ratelimiter: current limiting
- resilience4j-bulkhead: isolation
- resilience4j-retry: automatic retry
- resilience4j-cache: result cache
- resilience4j-timelimiter: timeout handling
Resilience4j Circuit Breaker
A circuit breaker (circuitBreaker) usually has three states (CLOSE, OPEN, HALF_OPEN) and records the current request success rate or slow rate through a time or quantity window, so as to make a correct fault-tolerant response.
Three important states:
- closed -> open : Closed state to blown state. When the failed call rate (such as timeout, exception, etc.) is 50% by default, when a certain threshold is reached, the service will be turned into an open state. In the open state, all requests will be intercepted.
- open-> half_open: After a certain period of time, the default value in CircuitBreaker is 60s. The service caller allows certain requests to reach the service provider.
- half_open -> open: When the call failure rate of the half_open state exceeds the given threshold, it will switch to the open state. half_open -> closed: If the failure rate is lower than the given threshold, it will switch to the closed state by default.
There are six states
- CLOSED: Closed state, representing the state under normal circumstances, allowing all requests to pass through, and can be converted to OPEN through the state
- HALF_OPEN: Half-open state, which allows some requests to pass through, and can be converted to CLOSED and OPEN through the state
- OPEN: Fuse state, that is, the request is not allowed to pass, and the pass state can be changed to HALF_OPEN
- DISABLED: Disabled state, that is, all requests are allowed to pass, and the failure rate reaches a given threshold and will not be fused, and will not
- A state transition occurs.
- METRICS_ONLY: Like the DISABLED state, it also allows all requests to pass without fusing, but it will record failures
- Failure rate and other information, no state transition will occur.
- FORCED_OPEN: Contrary to the DISABLED state, the CircuitBreaker is enabled, but no request is allowed to pass
- However, no state transition occurs.
Microservice Gateway
The gateway uniformly provides REST APIs to external systems (visitors, services). In Spring Cloud, Zuul, Spring Cloud Gateway, etc. are used as API Gateway to implement functions such as dynamic routing, monitoring, fallback, and security.

Spring Cloud Gateway
Spring Cloud Gateway is a gateway in the Spring Cloud ecosystem, developed based on technologies such as Spring5.0, springboot2.0 and project reactor. Implemented with "Netty+WebFlux". All are providing a simple, effective and unified API routing management method for the microservice architecture
features
- Easy to write predicates (Predicates) and filters (Filters). Its Predicates and Filters can act on specific routes.
- Path rewriting is supported.
- Supports dynamic routing.
- Integrated with Spring Cloud DiscoveryClient.
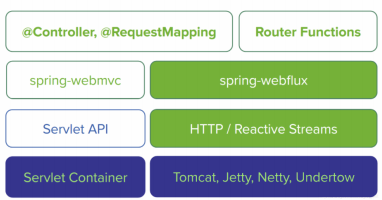
WebFlux
The Webflux pattern replaces the old Servlet threading model. Use a small number of threads to process request and response io operations. These threads are called Loop threads, and the business is handed over to the responsive programming framework. Responsive programming is very flexible. Users can submit blocked operations in the business to the responsive framework. The non-blocking operations can still be processed in the Loop thread, which greatly improves the utilization of the Loop thread.
WebFlux is compatible with multiple underlying communication frameworks, but in most cases it uses Netty, which is currently the most recognized communication framework. The loop thread of WebFlux is the Reactor thread of the famous Reactor mode IO processing model.
Netty
- High concurrency: Based on NIO (Nonblocking IO, non-blocking IO) development, compared with BIO (Blocking I/O, blocking IO), its concurrency performance has been greatly improved;
- Fast transmission: transmission relies on the zero-copy feature, which minimizes unnecessary memory copies and achieves more efficient transmission;
- Well-encapsulated: Encapsulates many details of NIO operations and provides an easy-to-use calling interface
Three cores
First of all, any requests come in, the gateway will block them. They are assigned to different routes according to the URL of the request, and there will be assertions on the route to determine whether the request can come in. After coming in, there will be a series of filters to modify the request before or after it is forwarded. The specific modification method is customized according to different businesses. Generally, it is monitoring, current limiting, log output, etc.
Route
The Gateway basic building block, which is defined by an ID, a target URL, a set of assertions and a set of filters, if the assertion is true, the route matches.
predicate
The input type is ServerWebExchange, which can be used to match any content from the HTTP request, such as HEADER or parameters
Filter
Requests can be modified before or after they are routed