Data cleaning - table merge and add timestamp
extract file name
Read the name of the specified type of file
separate file name
names = os.listdir(path)
for name in names:
index = name.rfind('.')
name = name[:index]
print(name)
flag = name.split('_')
The original form is shown in the figure above, without header
Add columns to the table and write the specified information into the columns
define header
merge table
总程序:
import os
import pandas as pd
path = os.getcwd()
names = os.listdir(path)
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
df = pd.read_csv(name,header=None,names=['temp','tempavg','tempmax','tempmin'])# 注意这里增加表头的方式!!
# df.columns=['temp','tempavg','tempmax','tempmin'] #增加表头,否则下一步添加列时不方便
name_new = name[:index]
flag = name_new.split('_')
print(flag)
time = flag[2]
series = flag[1]
df['time'] = time
df['series'] = series
df.to_csv(name,index=False) #保存更改,注意不需要自动添加索引!
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
print(csv)
df = pd.read_csv(name)
df.to_csv('allok.csv',encoding="utf_8_sig",header=False,index=False,mode='a+')
df = pd.read_csv('allok.csv',header=None,names=['temp','tempavg','tempmax','tempmin','time','series'])# 定义合并好的表格名字
df.to_csv('allok.csv',index=True)
index index problem
Indexes for default additions do not start at 1
df.index = np.arange(1, len(df))
The exported data is too long to be converted into scientific notation

Because the exported data was too long, it became a scientific notation; it caused the rounding when merging the tables later...
so df['time'] = str(time)+'\t'

it was successfully solved by adding it!
Merge table upgrade (feature row and column expansion and merging)
Original table style: (tens of thousands of such tables need to be merged) 

After merging, it becomes a total table with separate mean and maximum values of each parameter
path = os.getcwd()
names = os.listdir(path)
i = 0
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
df = pd.read_csv(name)
for index,row in df.iterrows():
feature_name = row[0]
feature_avg = feature_name+'_avg'
feature_min = feature_name+'_min'
feature_max = feature_name+'_max'
df[feature_avg] = str(row[1])+'\t'
df[feature_max] = str(row[2])+'\t'
df[feature_min] = str(row[3])+'\t'#防止科学计数
data =df.iloc[:1,4:] #定位表格
if(i == 0):
data.to_csv('gather_operate.csv',encoding="utf_8_sig",header =True,index = False ,mode='a+')
else:
data.to_csv('gather_operate.csv',encoding="utf_8_sig",header =False,index = False ,mode='a+')
i=i+1
Extract the file name to the table and save it to the parent directory
import os,sys
import xlwt
path = os.getcwd()
dirs = os.listdir(path)
write =xlwt.Workbook()
sheet = write.add_sheet('sheet_name')
i = 0
for file in dirs:
if os.path.splitext(file)[1]=='.csv':
sheet.write(i,0,file)
i+=1
print(i)
write.save('../file_name.xls')
Chinese garbled characters appear when pandas writes csv format file
df.to_csv("cnn_predict_result.csv",encoding="utf_8_sig")
Migrate table headers when merging tables in batches
i = 0
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
if(i==0):
print("header")
df = pd.read_csv(name)
df.to_csv('特征值数据汇总.csv',encoding="utf_8_sig",header=True,index=False,mode='a+')#拼接第一个表格时保留表头
else:
print(csv)
df = pd.read_csv(name)
df.to_csv('特征值数据汇总.csv',encoding="utf_8_sig",header=False,index=False,mode='a+')
i=i+1
Pandas output table string is too long to change to scientific notation
The method of directly changing the cell format on the Internet, the file is closed and then opened is still the same.
Later, I read an article
df['time']=[' %i' % i for i in df['time']] select Add /t to the column to be modified. My understanding is to add a character. Use
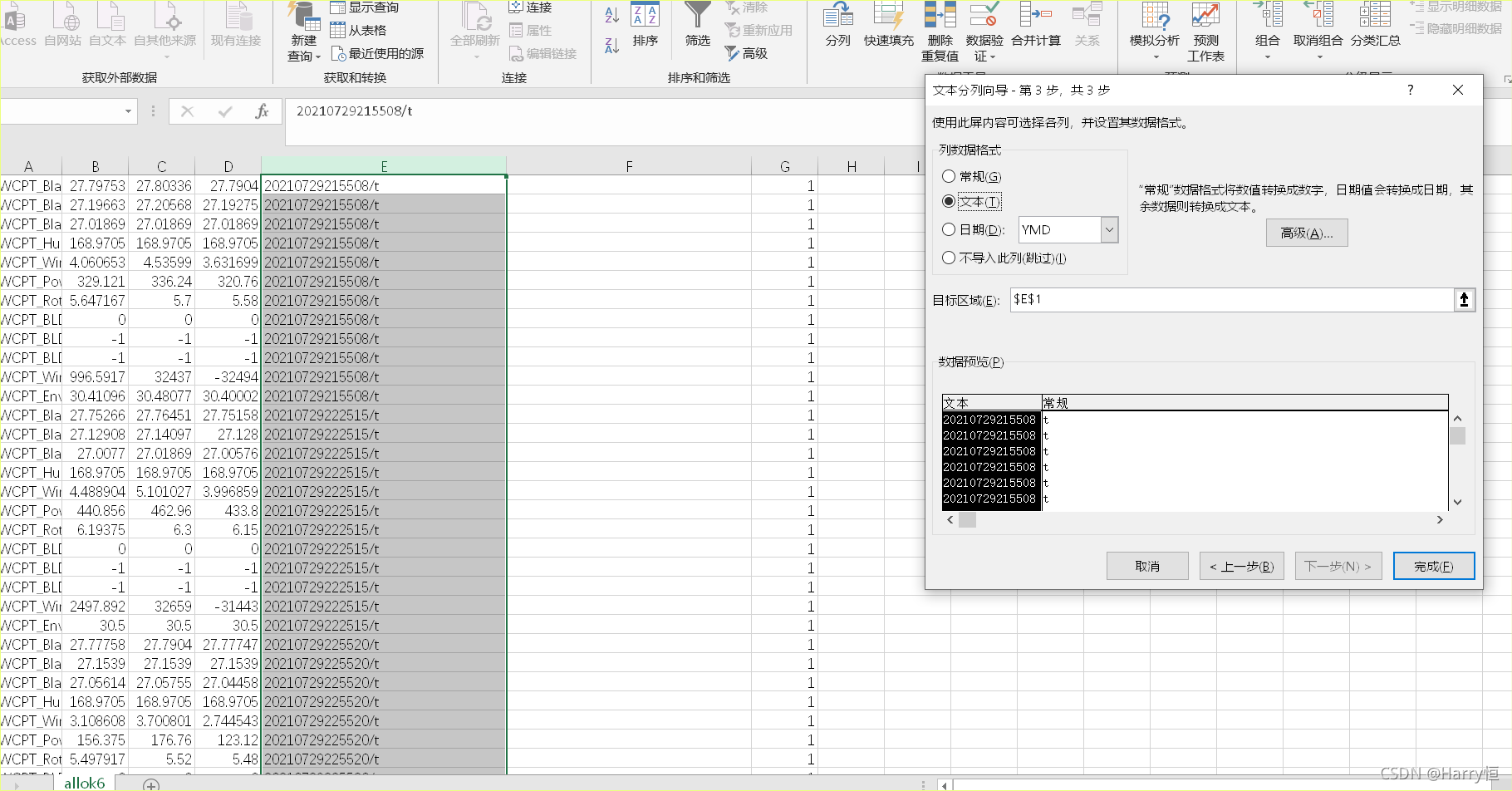
Excel to sort