MetaAI, the young man who has been smashed in the metaverse and Web 3.0, is now wielding the open source sword in the field of AIGC to kill the Quartet!
In the past few months alone, MetaAI has open sourced many useful projects on GitHub:
- Segment Anything (SAM), which can automatically segment all items in a picture or video, complete automatic segmentation with one click, and supports zero-sample transfer to other segmentation tasks.
- DINOv2, without fine-tuning, obtains visual features through self-supervision, directly promoting the progress of computer vision technology.
- Animated Drawings, using AI capabilities to quickly add animation effects to paintings.
The list goes on and on.
Today, Meta made another move and officially announced the open source ImageBind , which allows the model to communicate across 6 different modalities (image, text, audio, depth, temperature, and IMU data)!
Here is a video released by Zuckerberg on Facebook a few days ago, so that you can intuitively feel how powerful ImageBind is:
GitHub:https://github.com/facebookresearch/ImageBind
As I said before, AI models get closer to human-like capabilities with each modality they support.
We can see the bustling streets, hear the whistle on the road, and feel the hot summer, all of which come from the innate sensory abilities of human beings without exception.
Hearing, smell, taste, vision and other abilities allow us to better interact with the world.
If we want to make AI's capabilities closer to humans, we need to give AI more capabilities so that it can better perceive the world.
In the past, to achieve search association between various modalities, it was necessary to maintain and train multiple copies of data at the same time.
Now with ImageBind, images can be generated directly from audio. For example, if you listen to the sound of ocean waves for AI, it can directly generate images of the sea, which will save a lot of training costs.
From the interface point of view, AI is just like human beings, who can start to make up the picture based on the sound.
What's more, ImageBind also has built-in 3D perception and IMU sensors, which can be used to measure acceleration and rotational motion, allowing AI to feel the changes in our physical world.
In addition, ImageBind also provides a new type of rich memory retrieval method, allowing AI to directly use the combined data of text, audio and images to directly search for pictures, videos, audio files or text messages.
In this way, we can allow previous AIGC applications to generate higher quality content.
For example, if it is applied to the field of video editing, AI can directly search for video clips with a higher degree of matching based on the sound, image, and text we give, realizing the true one-click video editing function!
In traditional AI systems, each modality has a specific embedding (a numerical vector of data and its relation in machine learning).
This makes it difficult to interact and retrieve between different modalities, and we cannot accurately retrieve related images and videos directly based on audio.
However, ImageBind can do it. It enables cross-modal retrieval by aligning the embeddings of the six modalities into a common space.

As a multimodal model, ImageBind integrates the SAM and DINOv2 I mentioned above, so that its own capabilities have been fully improved.
Binding various modalities together to build a bridge for seamless communication is the core function implemented by ImageBind.
The Make-A-Scene tool previously developed by MetaAI can generate images from text.
Now with the help of ImageBind, you can directly generate images directly through sound. This enables AI to have a deeper understanding of human emotions, understand their emotions, and then provide better services for humans.
At the same time, based on ImageBind's cross-modal communication capabilities, the improvement of each modality's ability will also drive the progress of another modality, and then achieve a snowball-like effect.
In order to verify this, the MetaAI technical team also conducted a benchmark test and found that ImageBind is significantly better than other professional models in terms of audio and depth, which is derived from the experience absorbed and summarized by AI from other modalities.
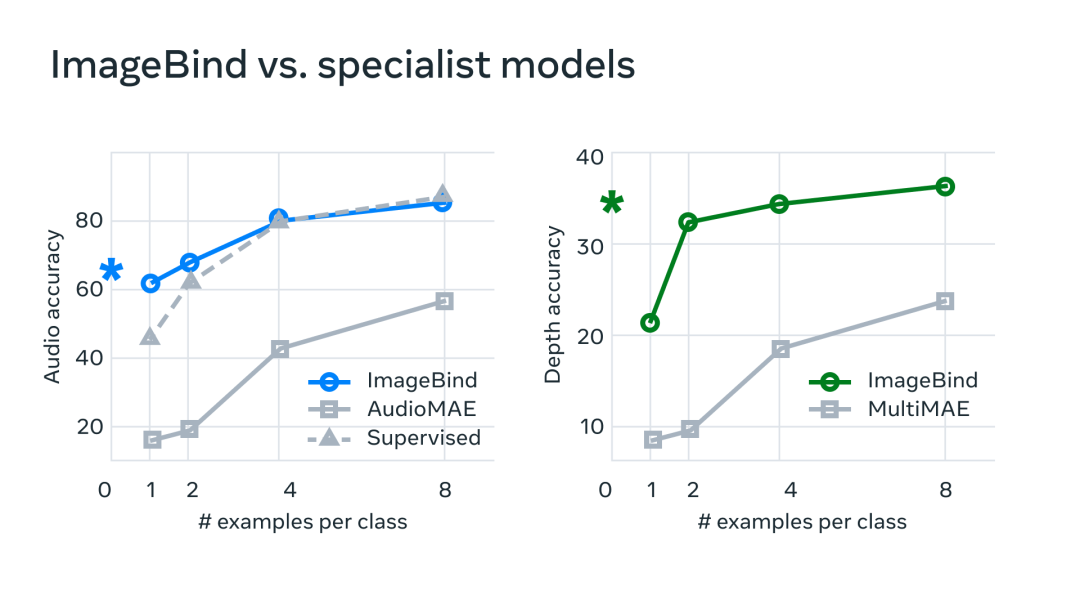
It is currently predictable that video editing will become easier and simpler in the future.
When you raise your phone and record a video of a seaside sunset, AI can automatically generate copywriting and subtitles based on the content of the video, and match it with appropriate background music.
It is even possible for AI to directly generate a video MV for the singer through a song.
In VR and AR games, users can also interact with game characters through various voices, gestures, and head movements to enhance the interactivity and immersion of the game.
In the medical field, doctors can collect patient's condition information through various methods such as voice and images, and then process and analyze it through machine learning and other technologies, so as to obtain more accurate diagnosis results and treatment plans.
Although ImageBind currently only has 6 modes, with the integration of more sensory functions, such as smell and touch, the capabilities of the AI model will become stronger, and the AIGC industry will also usher in earth-shaking changes.
The emergence of this project will bring AIGC technology to a wider range of application scenarios, and a large wave of more interesting and practical AI projects is coming soon.