Introduction to iris dataset
Collected and published by statistician and botanist Ronald Fisher in 1936. The data set contains 150 samples, each of which represents an iris flower (iris flower), and contains four features (sepal length (sepal length), sepal width (sepal width), petal length (petal length ) and petal width (petal width)) and the corresponding class labels (iris setosa, iris versicolor and iris virginica).
- Sample size: 150 pieces
- Number of categories: 3 categories
- Each type of sample: 50 pieces
- Feature Dimensions: 4
read dataset
import numpy as np
import torch
def load_iris(filename):
data = np.load(filename)
features = data['data']
labels = data['label']
return torch.tensor(features, dtype=torch.float64), torch.tensor(labels, dtype=torch.int64)
train_data, train_label = load_iris(r"../../Dataset/iris/iris_train.npz")
valid_data, valid_label = load_iris(r"../../Dataset/iris/iris_valid.npz")
print(train_data.shape, train_label.shape, valid_data.shape, valid_label.shape,)
input_dim = train_data.shape[1]
output_dim = int(train_label.max().numpy()) + 1
print(input_dim, output_dim)
import random
def data_iter(feature, label, _batch_size):
num_samples = len(label)
index_list = list(range(num_samples))
random.shuffle(index_list)
for i in range(0, num_samples, _batch_size):
batch_index = index_list[i: min(i + _batch_size, num_samples)]
batch_features = torch.index_select(feature, dim=0, index=torch.LongTensor(batch_index))
batch_labels = torch.index_select(label, dim=0, index=torch.LongTensor(batch_index))
yield batch_features, batch_labels
for x, y in data_iter(train_data, train_label, 2):
print(x, y)
break
In the Iris dataset, the values of the labels are 0, 1, 2, so the maximum value is 2. In order to use labels for multi-classification problems, they need to be converted to one-hot encoding with an output dimension of 3.
network model
Using the most basic softmax network
def net(_input, _w, _b):
output = torch.mm(_input, _w) + _b
exp = torch.exp(output)
exp_sum = torch.sum(exp, dim=1, keepdim=True)
output = exp / exp_sum
return output
w = torch.normal(0, .01, [input_dim, output_dim], requires_grad=True, dtype=torch.float64)
b = torch.normal(0, .01, [1, output_dim], requires_grad=True, dtype=torch.float64)
with torch.no_grad():
random_input = torch.normal(0, .01, [10, 4], dtype=torch.float64)
output = net(random_input, w, b)
print(output.shape)
Define the loss function
def cross_entropy(y_pred, y):
pred_value = torch.gather(y_pred, 1, y.view(-1, 1))
_loss = -torch.log(pred_value)
return _loss.sum()
A cross-entropy loss function that measures the difference between the model output and the true labels.
define optimizer
def optimizer(params, _lr, _batch_size):
with torch.no_grad():
for param in params:
param -= _lr * param.grad / _batch_size
param.grad.zero_()
Defines a gradient descent optimizer for updating the parameters of the model.
training evaluation
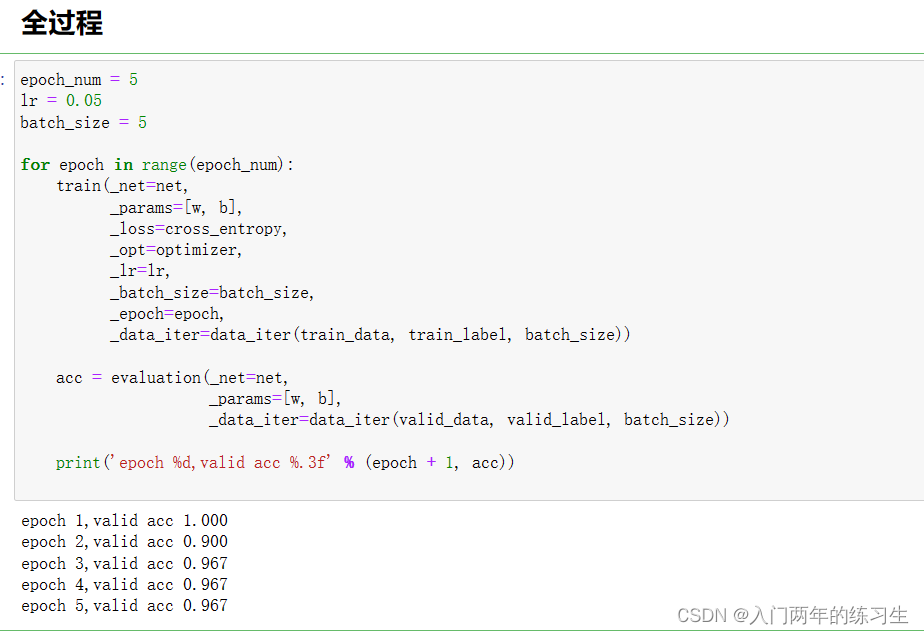
epoch_num = 5
lr = 0.05
batch_size = 5
for epoch in range(epoch_num):
train(_net=net,
_params=[w, b],
_loss=cross_entropy,
_opt=optimizer,
_lr=lr,
_batch_size=batch_size,
_epoch=epoch,
_data_iter=data_iter(train_data, train_label, batch_size))
acc = evaluation(_net=net,
_params=[w, b],
_data_iter=data_iter(valid_data, valid_label, batch_size))
print('epoch %d,valid acc %.3f' % (epoch + 1, acc))
Result graph:
Iris data set download free