Column: Neural Network Recurrence Directory
bidirectional recurrent neural network
Bidirectional Recurrent Neural Network (BRNN for short) is a neural network capable of processing sequence data, which can simultaneously consider past and future information in a sequence of data. Unlike traditional recurrent neural networks (RNNs), BRNNs use two separate recurrent structures at each time step, one for passing information from the past to the future and the other for passing information from the past to the past .
The main idea of BRNN is to process the input sequence from two directions (forward and backward) separately, and then combine their outputs. In this way, BRNN can utilize all the information in the sequence, including past and future, so as to better capture the long-term dependencies in the sequence. For example, in natural language processing, BRNN can process left-to-right and right-to-left text sequences, improve the quality of text representation, and thus improve the performance of the model.
Article directory
Dynamic Programming in Hidden Markov Models
Hidden Markov Model (HMM) is a probabilistic model for modeling sequence data, which is often used in speech recognition, natural language processing, bioinformatics and other fields. HMM assumes that each observation data is composed of a hidden state sequence and a state-related observation sequence. Among them, the hidden state sequence is a Markov process, that is, each state is only related to the previous state. An observation sequence is a sequence of observation data generated by each state.
In HMM, the forward algorithm and the backward algorithm are usually used to calculate the probability of a given observation sequence. Both algorithms are solved using dynamic programming.
The forward algorithm is used to calculate the observation sequence O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, ..., o_T)O=(o1,o2,...,oT) shapeλ = ( π , A , B ) \lambda = (\pi , A , B )l=( p ,A,B ) under the probabilityP ( O ∣ λ ) P(O|\lambda)P ( O ∣ λ ) . Its basic idea is that at each time stepttt , calculate all observations in the known previous valueso 1 , o 2 , . . . , ot − 1 o_1, o_2, ..., o_{t-1}o1,o2,...,ot−1In the case of , the system is in state iiProbability of i α t ( i ) \alpha_t(i)at( i ) . This probability can be calculated recursively. Specifically, fort = 1 t=1t=1 , we have
α 1 ( i ) = π ibi ( o 1 ) \alpha_1(i) = \pi_i b_i(o_1)a1(i)=Piibi(o1)
for t > 1 t>1t>1,我们有
α t ( i ) = [ ∑ j = 1 N α t − 1 ( j ) a j i ] b i ( o t ) \alpha_t(i) = \left[\sum_{j=1}^N \alpha_{t-1}(j)a_{ji}\right] b_i(o_t) at(i)=[j=1∑Nat−1( j ) hasji]bi(ot)
Among them, NNN is the number of hidden states,aij a_{ij}aijIndicates from state iii transitions to statejjThe probability of j ,bi ( ot ) b_i(o_t)bi(ot) means that in stateiii generate observationot o_totThe probability.
Calculate α t ( i ) \alpha_t(i) by recursionat( i ) , we can finally getP ( O ∣ λ ) = ∑ i = 1 N α T ( i ) P(O|\lambda) = \sum_{i=1}^N \alpha_T(i)P(O∣λ)=∑i=1NaT(i)。
The backward algorithm is used to calculate the given observation sequence OOO and modelλ \lambdaUnder λ , the system is in stateiiProbability of i β t ( i ) \beta_t(i)bt( i ) . The basic idea of the backward algorithm is to know all observationsot + 1 , ot + 2 , . . . , o T o_{t+1}, o_{t+2}, ..., o_Tot+1,ot+2,...,oTIn the case of , the system is in state iiprobability of i . Specifically, fort = T t=Tt=T , we have
β T ( i ) = 1 \beta_T(i) = 1bT(i)=1
for t < T t < Tt<T,我们有
β t ( i ) = ∑ j = 1 N a i j b j ( o t + 1 ) β t + 1 ( j ) \beta_t(i) = \sum_{j=1}^N a_{ij} b_j(o_{t+1}) \beta_{t+1}(j) bt(i)=j=1∑Naijbj(ot+1) bt+1(j)
Calculate β t ( i ) \beta_t(i) by recursionbt( i ) , possibleP ( O ∣ λ ) = ∑ i = 1 N π ibi ( o 1 ) β 1 ( i ) P(O|\lambda) = \sum_{i=1}^N \pi_i b_i( o_1) \beta_1(i)P(O∣λ)=∑i=1NPiibi(o1) b1(i)。
At the same time, the forward algorithm and the backward algorithm can also be used to calculate the given observation sequence and model, the system is in a certain state iiThe probability of i γ t ( i ) \gamma_t(i)ct( i ) and from stateiii to statejjThe transition probability of j ξ t ( i , j ) \xi_t(i,j)Xt(i,j ) . Specifically, fort = 1 , 2 , . . . , T t=1,2,...,Tt=1,2,...,T , we have
γ t ( i ) = α t ( i ) β t ( i ) P ( O ∣ λ ) \gamma_t(i) = \frac{\alpha_t(i) \beta_t(i)}{P(O|\lambda)} ct(i)=P(O∣λ)at( i ) bt(i)
ξ t ( i , j ) = α t ( i ) a i j b j ( o t + 1 ) β t + 1 ( j ) P ( O ∣ λ ) \xi_t(i,j) = \frac{\alpha_{t}(i) a_{ij} b_j(o_{t+1}) \beta_{t+1}(j)}{P(O|\lambda)} Xt(i,j)=P(O∣λ)at(i)aijbj(ot+1) bt+1(j)
Among them, P ( O ∣ λ ) P(O|\lambda)P ( O ∣ λ ) is the observation sequenceOOO in the modelλ \lambdaThe probability under λ .
The application of dynamic programming in HMM allows us to efficiently calculate the probability of the observation sequence, as well as the probability and transition probability of the system in a certain state given the observation sequence. This is very helpful for both model training and prediction.
two-way model
If we want to have a mechanism in the recurrent neural network that can provide similar forward-looking capabilities as hidden Markov models, we need to modify the design of the recurrent neural network. Fortunately, this is conceptually easy, just adding a RNN that "runs backwards from the last token" instead of just a "starting from the first token" in forward mode running" recurrent neural network. Bidirectional RNNs add hidden layers that pass information backwards in order to process such information more flexibly. The diagram below depicts the architecture of a bidirectional recurrent neural network with a single hidden layer.
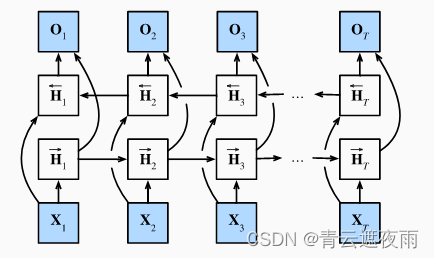
mathematical definition
Forward hidden state:
H → t = ϕ ( X t W xh + H → t − 1 W hh + bh ) H_{\rightarrow t} = \phi(X_t W_{xh} + H_{\rightarrow t-1} W_{hh} + b_h)H→t=ϕ ( XtWxh+H→t−1Whh+bh)
reverse hidden state:
H ← t = ϕ ( X t W xh + H ← t + 1 W hh + bh ) H_{\leftarrow t} = \phi(X_t W_{xh} + H_{\leftarrow t+1 } W_{hh} + b_h)H←t=ϕ ( XtWxh+H←t+1Whh+bh)
Export:
O t = H t W hq + bq O_t = H_t W_{hq} + b_qOt=HtWhq+bq
Among them, X t X_tXtCome in, W xh , W hh , W hq W_{xh}, W_{hh}, W_{hq}Wxh,Whh,Whqis the weight matrix, bh , bq b_h, b_qbh,bqis a bias term, ϕ \phiϕ is the activation function,H → t H_{\rightarrow t}H→t和 H ← t H_{\leftarrow t} H←tare the forward and reverse hidden states, H t = [ H → t ; H ← t ] H_t = [H_{\rightarrow t}; H_{\leftarrow t}]Ht=[H→t;H←t] is a two-way hidden state,O t O_tOtis the output.
The Computational Cost of the Model and Its Application
A key property of bidirectional recurrent neural networks is that they use information from both ends of the sequence to estimate the output. That is, we use information from past and future observations to predict current observations. But in the case of predicting the next token, such a model is not what we need. Because when predicting the next token, we can't know what the next token will be after all, so we won't get good accuracy. Specifically, during training, we are able to use past and future data to estimate the present vacant word; while during testing, we only have past data, so the accuracy will be poor. The following experiment will illustrate this point.
Another serious problem is that bidirectional recurrent neural networks are computationally very slow. The main reason is that the forward propagation of the network requires forward and backward recursion in the bidirectional layer, and the backward propagation of the network also depends on the result of the forward propagation. Therefore, the gradient solver will have a very long chain.
defect! !
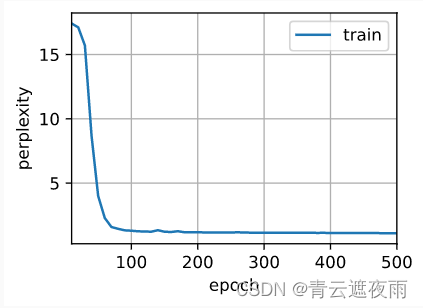
Since bidirectional recurrent neural networks use past and future data, we cannot blindly apply this language model to any prediction task. Although the perplexity levels produced by the model are reasonable, the model's ability to predict future tokens may be severely flawed. We use the sample code below as a warning in case they are used in the wrong context.
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)