Column: Neural Network Recurrence Directory
machine translation
Machine translation is the process of using computer technology to automatically translate text from one language into another. Machine translation technology aims to solve language barriers and make communication between different languages easier. The algorithms used in machine translation include statistical machine translation, neural machine translation, etc. Machine translation technology has made great progress, but there are still many challenges, such as language differences, ambiguity and polysemy, etc.
Article directory
data set
read dataset
The data set of this article comes from the bilingual sentence pairs (English: French) of the Tatoeba project: http://www.manythings.org/anki/
def read_data_nmt():
"""载入“英语-法语”数据集"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join('fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
data preprocessing
Replace spaces to facilitate subsequent cutting
#@save
def preprocess_nmt(text):
"""预处理“英语-法语”数据集"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
Lemmatization
#@save
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
source, target = tokenize_nmt(text)
source[:]
draw a chart
#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):
"""绘制列表长度对的直方图"""
d2l.set_figsize()
_, _, patches = d2l.plt.hist(
[[len(l) for l in xlist], [len(l) for l in ylist]])
d2l.plt.xlabel(xlabel)
d2l.plt.ylabel(ylabel)
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(legend)
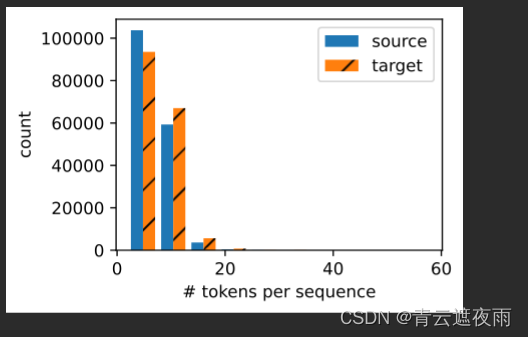
show_list_len_pair_hist(['source', 'target'], '# tokens per sequence',
'count', source, target);
Glossary of definitions
import collections
class Vocab:
"""Vocabulary for text."""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
"""Defined in :numref:`sec_text_preprocessing`"""
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# Sort according to frequencies
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# The index for the unknown token is 0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {
token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # Index for the unknown token
return 0
@property
def token_freqs(self): # Index for the unknown token
return self._token_freqs
def count_corpus(tokens):
"""Count token frequencies.
Defined in :numref:`sec_text_preprocessing`"""
# Here `tokens` is a 1D list or 2D list
if len(tokens) == 0 or isinstance(tokens[0], list):
# Flatten a list of token lists into a list of tokens
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
The code defines a class called Vocab, which is used to build the vocabulary of the text. Each method and property is explained below:
init (self, tokens=None, min_freq=0, reserved_tokens=None): Constructor, create a vocabulary. The parameter tokens is a list containing all the words in the text, min_freq is the least number of occurrences of the word in the text, and reserved_tokens is a reserved word list. The constructor first uses the count_corpus() function to count the number of occurrences of words, and sorts the words according to their frequency of occurrence from high to low. Then add the pre-defined words to the vocabulary, and build a word-to-index dictionary token_to_idx according to the order of appearance of the words, and build a list idx_to_token from the index to words according to the frequency of occurrence. For words whose occurrence times are less than min_freq, skip them directly and do not add them to the vocabulary. In the final vocabulary, index 0 corresponds to words with high frequency of occurrence, indexes 1 to n-1 correspond to words with high frequency of occurrence, and values at and after index n represent words with low frequency of occurrence.
len (self): Returns the size of the vocabulary, i.e. the total number of words.
getitem (self, tokens): According to the word or word list tokens returns its corresponding index or index list. If tokens is a word, returns its corresponding index. If tokens is a list of words, the getitem () method is called recursively for each word in it and returns the list of indices.
to_tokens(self, indices): returns the corresponding word or word list according to the index or index list indices. If indices is an index, returns its corresponding word. If indices is a list of indices, the to_tokens() method is called recursively for each index in it and returns the list of words.
unk: attribute, returns the index of the word, which is 0.
token_freqs: attribute, returns a list of words sorted from high to low frequency. This property is initialized when the vocabulary is created.
count_corpus(tokens): A function defined outside the Vocab class, used to count the frequency of words. The parameter tokens is a list containing all the words of the text, possibly a two-dimensional list. If tokens is a two-dimensional list, first convert it to a one-dimensional list. This function uses the collections.Counter() function to count the number of times each word occurs in the text and returns a dictionary.
src_vocab = Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
len(src_vocab)
filling
#@save
def truncate_pad(line, num_steps, padding_token):
"""截断或填充文本序列"""
if len(line) > num_steps:
return line[:num_steps] # 截断
return line + [padding_token] * (num_steps - len(line)) # 填充
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
Organization Dataset
#@save
def build_array_nmt(lines, vocab, num_steps):
"""将机器翻译的文本序列转换成小批量"""
lines = [vocab[l] for l in lines]#token to id
lines = [l + [vocab['<eos>']] for l in lines]# 加上eos代表结束
array = torch.tensor([truncate_pad(
l, num_steps, vocab['<pad>']) for l in lines])# 转换为数组
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)#有效长度
return array, valid_len
This function converts machine-translated text sequences into mini-batches, where input lines is a list containing text sequences, vocab is a vocabulary object, and num_steps is the maximum number of tokens contained in each sequence. The function returns two tensors, the first is a tensor containing sequences of num_steps tokens, and the second is the effective length of each sequence. For a sequence, its effective length is the number of tokens before the first filler, counted from the beginning.
The function first converts each sequence of text to a list of integers in the vocabulary, and then appends a token to each sequence. Next, it truncates or pads all sequences to length num_steps. If a sequence still has tokens after num_steps tokens, then its remaining tokens will be truncated. If a sequence has fewer than num_steps tokens, padding tokens will be added to the end of the sequence. Finally, the function computes the effective length of each sequence and returns two tensors.
#@save
from torch.utils import data
def load_array(data_arrays, batch_size, is_train=True):
"""Construct a PyTorch data iterator.
Defined in :numref:`sec_linear_concise`"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表"""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
src_vocab = Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:
print('X:', X.type(torch.int32))
print('X的有效长度:', X_valid_len)
print('Y:', Y.type(torch.int32))
print('Y的有效长度:', Y_valid_len)
break

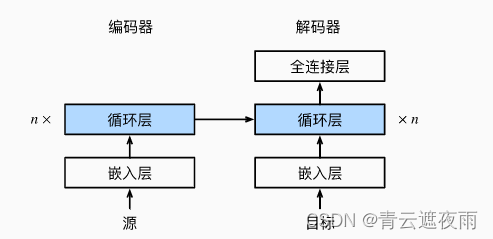
Encoder-Decoder Architecture
As we discussed in the previous section, machine translation is a central problem of sequence transformation models whose input and output are sequences of variable length. To handle this type of input and output, we can design an architecture with two main components: The first component is an encoder: it takes as input a sequence of variable length and converts it to An encoded state with a fixed shape. The second component is the decoder: it maps a fixed-shape encoded state to a variable-length sequence. This is called an encoder-decoder architecture and is shown in the figure below.
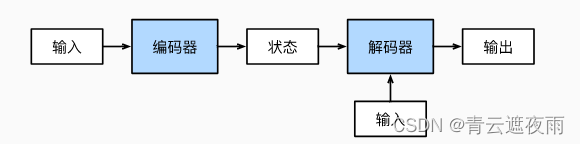
Let's take English-to-French machine translation as an example: Given an English input sequence: "They" "are" "watching" ".". First, this "encoder-decoder" architecture encodes a variable-length input sequence into a "state" and then decodes that state, token by token, to generate a translated sequence as output:" Ils" "regordent" "." Since the "encoder-decoder" architecture is the basis for forming different sequence conversion models in subsequent chapters, this section will convert this architecture into an interface for later code implementation.
Encoder
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
decoder
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
Combine Encoder and Decoder
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
Sequence-to-sequence learning (seq2seq)
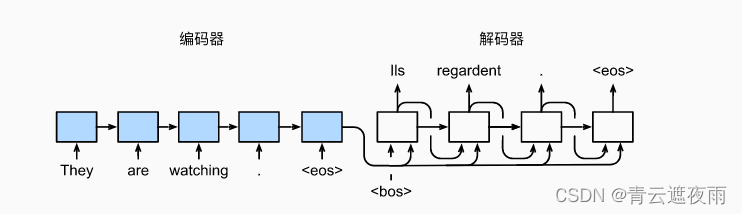
Following the design principles of the encoder-decoder architecture, a recurrent neural network encoder takes a variable-length sequence as input and transforms it into a fixed-shape hidden state. In other words, the information of the input sequence is encoded into the hidden state of the RNN encoder. To continuously generate tokens of the output sequence, a separate RNN decoder predicts the next token based on the encoded information of the input sequence and tokens already seen or generated in the output sequence. The figure below demonstrates how to use two recurrent neural networks for sequence-to-sequence learning in machine translation.
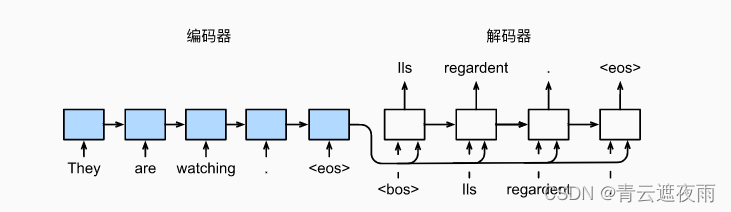
In the figure, a specific "" indicates a sequence-ending token. The model stops predicting once the output sequence produces this token. At the initialization time step of the RNN decoder, there are two specific design decisions: First, the specific "" denotes the sequence start token, which is the first token of the input sequence to the decoder. Second, the hidden state of the decoder is initialized with the final hidden state of the recurrent neural network encoder. For example, in the design of (Sutskever et al., 2014), it is based on this design that the encoding information of the input sequence is fed into the decoder to generate the output sequence. In some other designs (Cho et al., 2014), as shown in Figure 9.7.1, the final hidden state of the encoder is included as part of the input sequence to the decoder at every time step. It is possible to allow the label to be the original output sequence, moving the position of the prediction from the source sequence token """Ils""regardent""." to the new sequence token "Ils""regardent"".""".
Encoder
Detailed code
#@save
class Seq2SeqEncoder(Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
This code defines a recurrent neural network encoder for sequence-to-sequence learning. The encoder consists of an embedding layer and a multi-layer recurrent neural network. The specific explanation is as follows:
class Seq2SeqEncoder(Encoder):: defines a class named Seq2SeqEncoder, which inherits from the Encoder class.
def init (self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): defines the initialization function of the class, which accepts the following parameters:
vocab_size: Vocabulary size.
embed_size: Dimensions of the embedding vector.
num_hiddens: Dimensions of hidden states in recurrent neural networks.
num_layers: The number of layers in the recurrent neural network.
dropout: dropout probability, the default is 0.
**kwargs: Additional parameters.
super(Seq2SeqEncoder, self) .init (**kwargs): Call the initialization function of the parent class Encoder and pass in parameters.
self.embedding = nn.Embedding(vocab_size, embed_size): Defines an embedding layer that converts each word in the input sequence into an embedding vector.
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout): Define a multi-layer recurrent neural network, which contains num_layers GRU layers. The input dimension of the GRU layer is embed_size, the output dimension is num_hiddens, and it also includes the dropout layer, and the probability of dropout is dropout.
def forward(self, X, *args): : defines the forward propagation function of the class, which accepts the input sequence X and other parameters (*args).
X = self.embedding(X): Converts each word in the input sequence X to an embedding vector.
X = X.permute(1, 0, 2): Convert the dimension of the input sequence X from (batch_size, num_steps, embed_size) to (num_steps, batch_size, embed_size). This is done so that in recurrent neural network models, the first axis corresponds to time steps.
output, state = self.rnn(X): Pass the converted input sequence X into the multi-layer recurrent neural network for calculation, and return the output and state. Among them, the shape of output is (num_steps, batch_size, num_hiddens), indicating the output of each time step; the shape of state is (num_layers, batch_size, num_hiddens), indicating the state of the last time step.
return output, state: returns output and state.
X.permute
In PyTorch, X.permute(dims) is a tensor method that can be used to rearrange the dimensions of a tensor. dims is a tuple of integers representing, for each dimension in the original tensor, where in the new tensor it should be placed. For example, if a tensor has dimensions (3,4,5), and dims=(1,0,2), it means that the first dimension in the new tensor is the second dimension of the original tensor, and the second dimension is the first dimension of the original tensor, and third dimension is the third dimension of the original tensor.
Specifically, X.permute(1, 0, 2) means that the first dimension and the second dimension of the tensor X are exchanged, and the third dimension remains unchanged. In the code, this operation is used to adjust the dimensions of the input sequence tensor X of shape (batch_size, num_steps, embed_size), so that the first dimension is the time step, and the second dimension is the batch size, thus conforming to the loop Input requirements for neural networks.
Why X = X.permute(1, 0, 2)
In a recurrent neural network, the dimensions of the input data need to meet the following requirements:
- The first dimension is the time step.
- The second dimension is the batch size.
Therefore, for an input sequence X of shape (batch_size, num_steps, embed_size), it needs to be resized to (num_steps, batch_size, embed_size).
In the code, the dimension adjustment is realized by calling X.permute(1, 0, 2). Specifically, X.permute(1, 0, 2) means converting the dimension of X from (batch_size, num_steps, embed_size) to (num_steps, batch_size, embed_size), that is, the first dimension (num_steps) and the second dimension ( batch_size) for exchange. The purpose of this is to take each time step in the input sequence X as input, and all samples (batch_size) in each time step are processed as a batch. Doing so can make full use of the parallel computing capability of the GPU and improve training efficiency.
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
output.shape

embedding layer
In natural language processing, embedding layer (Embedding Layer) is a common technique for mapping discrete words or characters into continuous vector representations. The embedding layer can represent each word or character as a fixed-length vector, and these vectors are usually called embedding vectors or word embeddings (Word Embeddings). Embedding vectors can capture the semantic and associative relationships between words or characters, and can be used as input to neural network models.
In PyTorch, nn.Embedding is a built-in embedding layer class that maps integer-encoded words or characters into continuous vectors. The input to nn.Embedding is a tensor of shape (batch_size, seq_length), where each element is an integer representing a vocabulary or character index. The output of nn.Embedding is a tensor of shape (batch_size, seq_length, embedding_size), where each element is a vector representing the embedding vector of a word or character. embedding_size is the dimension of the specified embedding vector.
In the code above, nn.Embedding is used to create an embedding layer that encodes words from a vocabulary of size vocab_size into a vector representation of dimension embed_size . In the forward method of Seq2SeqEncoder, the input sequence X is passed into the embedding layer to encode the index of each word into an embedding vector. The output tensor shape is (batch_size, num_steps, embed_size), where num_steps is the number of time steps of the sequence and batch_size is the batch size of the sequence.
The implementation of the embedding layer is very simple, you can use a weight matrix E ∈ R v × d E \in \mathbb{R}^{v \times d}E∈Rv × d , each input wordxi x_ixiMapped to its corresponding embedding vector ei ∈ R d e_i \in \mathbb{R}^dei∈Rd . Specifically, given a sizen × mn \times mn×The input matrix XXof mX , wherennn represents the sample size,mmm represents the length of the input, then the output matrixE ∈ R n × m × d E \in \mathbb{R}^{n \times m \times d} of theE∈Rn × m × d can be calculated by:
E i , j , : = EX i , j E_{i,j,:} = E_{X_{i,j}}Ei,j,:=EXi,j
where E i , j , : E_{i,j,:}Ei,j,:Denotes the output matrix EEE middleiii sample,jjthEmbedding vectors corresponding to j input positions, X i , j X_{i,j}Xi,jDenotes the input matrix XXiiin Xi sample,jjthWord indices corresponding to j positions.
This formula is used in the embedding layer. Hypothesis EEE is a shape( V , d ) (V,d)(V,d ) Tensors whereVVV is the size of the vocabulary,ddd is the dimension of the embedding vector. XXX is a shape( n , m ) (n,m)(n,Integer tensor of m ) , where nnn is the batch size,mmm is the sequence length. ThenE i , j , : E_{i,j,:}Ei,j,:Indicates that the index in the vocabulary is X i , j X_{i,j}Xi,jThe embedding vector of the word. where iii represents the sample index in the batch,jjj represents the positional index in the sequence. Therefore, the meaning of this formula is: for the iithin the batchi sample and the jjthin the sequencej position, the embedding layer will index the wordX i , j X_{i,j}Xi,jConverted to the word embedding vector EX i , j E_{X_{i,j}}EXi,j。
In deep learning models, the embedding layer is usually used as the first layer of the model. During the training of the model, the weight matrix of the embedding layer can be updated through backpropagation to minimize the loss function of the model. Meanwhile, at test time, a pre-trained embedding layer can be used to convert the input into a vector representation, which is then fed into the model for prediction.
decoder
class Seq2SeqDecoder(Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
This code defines a sequence-to-sequence learning cyclic neural network decoder Seq2SeqDecoder, whose role is to convert the input sequence into the target sequence.
The construction of the decoder is similar to that of the encoder, except that the embedding vector of the input sequence and the output vector of the encoder are concatenated as the input of the decoder.
The specific explanation is as follows:
init function: initialize the decoder. Similar to the encoder, it consists of an embedding layer, a recurrent neural network layer, and a fully connected layer. The input dimension of the embedding layer and the cyclic neural network layer is embed_size + num_hiddens, that is, the splicing of the input of the current time step and the output vector of the previous time step on the feature dimension. The output dimension of the fully connected layer is the target vocabulary size vocab_size.
init_state function: Initialize the initial state of the decoder. Since the initial state of the decoder needs to be obtained from the output of the encoder, an init_state function is implemented here, which takes the last hidden state of the encoder as the initial state of the decoder.
forward function: the forward calculation process of the decoder. Firstly, word embedding is performed on the input sequence X through the embedding layer, and then dimension replacement is performed on the feature dimension, so that the time step dimension is the first dimension. Then, by broadcasting, the last hidden state context of the encoder is repeated for X time step dimensions, and spliced with X on the feature dimension to obtain X_and_context. Input X_and_context into the cyclic neural network layer to get the output vector output of the decoder and the final hidden state state. Finally, the output is converted into an output vector of the target vocabulary size through the fully connected layer, and the dimension is replaced, so that the time step dimension is restored to the second dimension, and the output vector output of the decoder and the final hidden state state are returned.
The structure of the above model is shown in the figure:
loss function
At each time step, the decoder predicts the probability distribution of the output tokens. Similar to language models, distributions can be obtained using softmax and optimized by computing a cross-entropy loss function. Recall from the previous section that specific filler tokens are added to the end of the sequences so that sequences of different lengths can be loaded in mini-batches of the same shape. However, we should exclude the prediction of filler tokens from the calculation of the loss function.
To do this, we can use the sequence_mask function below to mask out irrelevant items by zeroing them out, so that any subsequent calculations of irrelevant predictions are multiplied with zero, and the result is equal to zero. For example, if two sequences have effective lengths (excluding filler tokens) of 1 and 2, respectively, the first item of the first sequence and the remaining items after the first two items of the second sequence will be cleared to zero.
#@save
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
This is a function for masking irrelevant items in a sequence, mainly used to exclude filler items when computing the sequence loss function. Its input consists of three parameters:
X: The sequence to be masked, the shape is (batch_size, sequence_length, embedding_size);
valid_len: the effective length of each sequence, the shape is (batch_size,);
value: the value used to replace irrelevant items, the default is 0.
In the function, first obtain the maximum length maxlen of the sequence through X.size(1), and then use torch.arange() to create a tensor of shape (1, maxlen), which represents the subscript of each position in the sequence. The dtype and device of the quantity are the same as X. Next, use the broadcasting mechanism to convert valid_len into a tensor of shape (batch_size, maxlen), where the first valid_len[i] elements of each row are True, and the rest are False, which means the elements before the i-th position in the sequence It is effective. Finally, the masked sequence is obtained by replacing irrelevant items with the specified value by setting X[~mask] to value. Finally, the function returns the masked sequence.
Broadcasting mechanism
Broadcasting (broadcasting) is an important mechanism in PyTorch, which allows some operations with different shapes between two tensors, such as tensor addition and subtraction, multiplication and division, element-wise operations, etc. When two tensors have different shapes, if they satisfy certain rules, they can be broadcast to make them the same shape, so as to perform corresponding operations.
The broadcast rules are as follows:
- If the dimensions of the two tensors are different, 1 is prepended to the shape of the smaller tensor until the dimensions are the same.
- If two tensors have different sizes along a certain dimension, and one of them has size 1, you can extend that tensor along that dimension to be the same size as the other tensor.
- If two tensors have different sizes in a dimension, and neither size is 1, broadcasting will fail and the operation will fail with an error.
For example, when performing a + b, if the shape of a is (3, 4) and the shape of b is (4,), according to the broadcasting rule, b can be expanded to (1, 4) and then compared with a Adding, the resulting shape is (3, 4). In this way, we can perform corresponding operations on two tensors of different shapes without explicitly copying the data, which greatly improves the readability and efficiency of the code.
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
This is a class inherited from PyTorch's built-in cross-entropy loss function nn.CrossEntropyLoss, known as the masked softmax cross-entropy loss function. The role of this class is to implement a loss function that can ignore the padding part of the label sequence.
Specifically, the forward function of this class accepts three inputs: the result pred predicted by the model, the real label sequence label and the effective sequence length valid_len. Among them, the shape of pred is (batch_size, num_steps, vocab_size), indicating the probability that the model predicts for each category at each time step; the shape of label is (batch_size, num_steps), indicating the real label sequence (category number); valid_len The shape is (batch_size,), indicating the effective length of each sample. When calculating the loss, we first create a tensor weights with the same shape as the label, and call the previously implemented sequence_mask function to set the invalid position in the weights (after the sequence length) The value is set to 0. Next, we use PyTorch's built-in cross-entropy loss function to calculate the unweighted loss. Here we need to convert the shape of pred from (batch_size, vocab_size, num_steps) to (batch_size, num_steps, vocab_size) to match the shape of label. Finally, we average the loss over the timestep dimension and return it. Since the effective length of each sample is already taken into account when calculating the loss, we don't need to divide by the effective length before returning.
注意:unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred.permute(0, 2, 1), label)
When calculating the cross-entropy loss function, the input pred is usually a three-dimensional tensor with a shape of (batch_size, num_steps, vocab_size), where batch_size is the batch size, num_steps is the number of time steps, and vocab_size is the vocabulary size. The shape of the label label is (batch_size, num_steps), which is a two-dimensional tensor. When calculating the cross-entropy loss function, you need to align the last dimension of pred and label , that is, move the last dimension of pred to the first dimension, so that you can call nn.CrossEntropyLoss to calculate the cross-entropy loss.
Therefore, the code uses pred.permute(0, 2, 1) to swap the last two dimensions of pred into a shape of (batch_size, vocab_size, num_steps), and then pass it into the forward method of nn.CrossEntropyLoss for calculation Cross entropy loss.
train
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {
metric[0] / metric[1]:.3f}, {
metric[1] / timer.stop():.1f} '
f'tokens/sec on {
str(device)}')
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
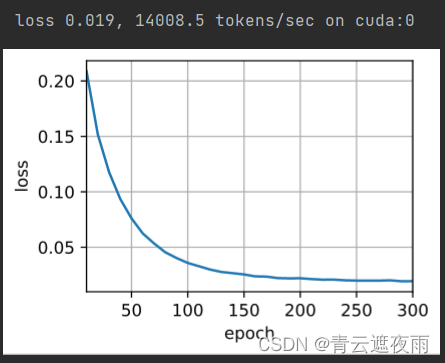
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
predict
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
This code implements the prediction of a sequence-to-sequence (seq2seq) model, where given a source language sentence, it is translated into a target language sentence using a trained seq2seq model.
Specific steps are as follows:
First, set the seq2seq model to evaluation mode (net.eval()).
Preprocess the source language sentence: convert it into the corresponding vocabulary index, then add a terminator "", and finally use the truncate_pad function to truncate or pad it to the specified length num_steps.
Input the processed source language sequence enc_X into the encoder of the seq2seq model, and obtain the output enc_outputs of the encoder and the effective length enc_valid_len of enc_X.
Input the output enc_outputs and enc_valid_len of the encoder into the init_state function of the decoder of the seq2seq model, and initialize the hidden state dec_state of the decoder.
Initialize the decoder's input to the start character "", and add it to the input of the first time step.
Iterate num_steps times to make predictions:
a) Input the input dec_X of the decoder and the current hidden state dec_state to the decoder of the seq2seq model, and obtain the output Y of the current time step and the new hidden state dec_state.
b) According to the softmax output of Y, select the word with the highest probability as the input of the next time step, that is, use Y.argmax(dim=2) to get the input dec_X of the next time step.
c) Convert dec_X to int type, and save it as the predicted value of the next time step in the output sequence output_seq. Stop prediction if the predicted value is terminator "".
d) If you need to save the attention weight (save_attention_weights=True), save the attention weight net.decoder.attention_weights to attention_weight_seq.
Convert the predicted value in output_seq to the target language sentence, and use the tgt_vocab.to_tokens function to convert the predicted value into the target language vocabulary. If attention weights need to be saved, attention_weight_seq is also returned.
The main role of this code is to demonstrate how to use the trained seq2seq model for translation prediction. It should be noted that the prediction here is carried out step by step, rather than predicting the entire target language sentence at one time. At each time step, the model predicts only the next word and uses that as input for the next time step.
Detailed code:
enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
The function of this line of code is to convert the input src_tokens into the tensor format of PyTorch, and add a dimension to the first dimension, that is, increase the dimension of a batch. Specifically, src_tokens is a Python list containing the input sequence, each element in the list is an integer representing a word in the input sequence. torch.tensor(src_tokens, dtype=torch.long, device=device) converts src_tokens into a PyTorch tensor format, and specifies the data type as long and the device as device. The torch.unsqueeze function adds a dimension to the first dimension, converting a tensor of shape (num_steps,) into a tensor of shape (1, num_steps). The resulting enc_X is a tensor of shape (1, num_steps), representing the input sequence in a batch of size 1.
Evaluation of Predicted Sequences
We can evaluate the predicted sequence by comparing it with the real label sequence. Although BLEU (bilingual evaluation understanding) proposed by (Papineni et al., 2002) was first used to evaluate the results of machine translation, it has now been widely used to measure the quality of output sequences for many applications. In principle, for any metagram (n-grams) in the predicted sequence, the evaluation of BLEU is whether this n-gram appears in the label sequence.
BLUE
BLEU (Bilingual Evaluation Understudy) is an evaluation index commonly used in the field of machine translation, which aims to compare the similarity between machine translation results and human reference translation results.
BLEU evaluates the quality of machine translation results. The calculation method includes two aspects: one is to consider the word overlap between the machine translation results and the reference translation, the higher the machine translation results, the better; the second is to consider the machine translation results and the reference translation. Whether the word order information between them is consistent.
The calculation method of the BLEU algorithm is relatively complicated. It first divides the machine translation results into multiple phrases according to different n-grams, and then calculates the number of occurrences of each phrase in the reference translation and the number of occurrences in the machine translation results, and finally synthesizes Consider the precision values of these n-grams to get the final BLEU score.
The commonly used n-gram range is 1-4, that is, calculate the scores of unigram, bigram, trigram, and fourgram respectively, and finally consider these four scores to calculate the BLEU score. Generally, the higher the BLEU score, the better the machine translation result, but the specific evaluation needs to be considered in combination with other factors.
Calculation formula
BLEU (Bilingual Evaluation Understudy) is an indicator for automatic evaluation of machine translation results, which integrates factors such as accuracy and fluency of translation results. Specifically, it calculates the similarity between the translation result and the reference answer, giving a score between 0 and 1, with a higher score indicating a better translation result. The following is the calculation formula of BLEU:
BLEU = BP ⋅ exp ( ∑ n = 1 N w n log p n ) \operatorname{BLEU} = \operatorname{BP}\cdot\exp\left(\sum_{n=1}^Nw_n\log p_n\right) BLEU=BP⋅exp(n=1∑Nwnlogpn)
where BP \operatorname{BP}BP is a phrase penalty item,wn w_nwnis nnWeights of n -tuples (usually wn = 1 N w_n=\frac{1}{N}wn=N1), p n p_n pnis nnThe precision of n -tuples.
n n The precision of the n- tuple refers to the translation results, appearing innnThe words in the n-tuple appear in the same n -tupleThe ratio of the number of words in an n -tuple. Specifically, for eachnnn -tuple, calculate the number of times it appears in the translation result, and then take the minimum value of these times as the numerator, and refer tothe nnThe total number of n -tuples is used as the denominator, and finally these ratios are added to getnnn -tuple precisionpn p_npn。
Phrase Penalty BP \operatorname{BP}BP is introduced to avoid translation results that are too prone to use phrases, resulting in an overly high score. Its calculation formula is as follows:
BP = { 1 , if c > r e 1 − r c , otherwise \operatorname{BP} = \begin{cases} 1, & \text{if }c>r \\ e^{1-\frac{r}{c}}, & \text{otherwise} \end{cases} BP={ 1,e1−cr,if c>rotherwise
Among them, ccc is the total number of words in the translation result,rrr is the total number of words in the reference answer. If the number of words in the translation result is more than the number of words in the reference answer, the penalty termBP \operatorname{BP}BP is equal to 1; otherwise,BP \operatorname{BP}BP is equal toe 1 − rce^{1-\frac{r}{c}}e1−cr。
p n p_n pnIt is an indicator for calculating the accuracy of n-gram in calculating the BLEU indicator. It represents how often n-grams in the predicted sequence appear in the reference sequence.
Specifically, assuming that the reference translation has m sentences, for each n, the n-gram counts of the predicted sequence and the reference translation can be calculated by the following formula:
count n = ∑ i : c i , … , i + n − 1 ∈ c min ( freq ( c i , … , i + n − 1 ) , max j = 1 m freq ( r j , … , j + n − 1 ) ) \operatorname{count}n = \sum{\boldsymbol{i}:\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{i}+n-1}\in \boldsymbol{c}} \min(\operatorname{freq}(\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{i}+n-1}), \max_{\boldsymbol{j}=1}^{m} \operatorname{freq}(\boldsymbol{r}_{\boldsymbol{j}, \ldots, \boldsymbol{j}+n-1})) countn=∑i:ci,…,i+n−1∈cmin(freq(ci,…,i+n−1),j=1maxmfreq(rj ,…, j +n−1))
where, c \boldsymbol{c}c is the predicted sequence,rj \boldsymbol{r}_jrjis jjj reference translations. freq ( x ) \operatorname{freq}(\boldsymbol{x})freq ( x ) means n-gramx \boldsymbol{x}how often x occurs in a sequence,iii is all withc \boldsymbol{c}The index of the location where the n-gram in c matches.
This formula is a counting function in the BLEU metric, representing the number of times an n-gram appears in the machine translation output. Among them, ccc represents the output sequence of machine translation,r 1 , … , rm r_1,\ldots,r_mr1,…,rmrepresents the sequence of reference translations, i \boldsymbol{i}i is a pointer to traverse all possible n-grams,freq ( ci , … , i + n − 1 ) \operatorname{freq}(\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{ i}+n-1})freq(ci,…,i+n−1 ) indicates the number of times the n-gram appears in the machine translation output,freq ( rj , … , j + n − 1 ) \operatorname{freq}(\boldsymbol{r}{\boldsymbol{j}, \ldots, \boldsymbol{j}+n-1})freq(rj,…,j+n−1 ) Indicates the number of occurrences of this n-gram in the reference translation. This formula is used to calculate the number of n-gram matches in the BLEU metric.
Then, calculate the precision pn p_npnThe following formulas can be used:
p n = ∑ i : c i , … , i + n − 1 ∈ c min ( freq ( c i , … , i + n − 1 ) , max j = 1 m freq ( r j , … , j + n − 1 ) ) ∑ i : c i , … , i + n − 1 ∈ c freq ( c i , … , i + n − 1 ) p_n = \frac{\sum_{\boldsymbol{i}:\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{i}+n-1}\in \boldsymbol{c}} \min(\operatorname{freq}(\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{i}+n-1}), \max_{\boldsymbol{j}=1}^{m} \operatorname{freq}(\boldsymbol{r}{\boldsymbol{j}, \ldots, \boldsymbol{j}+n-1}))}{\sum{\boldsymbol{i}:\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{i}+n-1}\in \boldsymbol{c}} \operatorname{freq}(\boldsymbol{c}{\boldsymbol{i}, \ldots, \boldsymbol{i}+n-1})} pn=∑i:ci,…,i+n−1∈cfreq(ci,…,i+n−1)∑i : c i , … , i + n − 1 ∈cmin(freq(ci,…,i+n−1),maxj=1mfreq(rj,…,j+n−1))
where the numerator represents the total number of n-gram matches between the predicted sequence and the reference translation, and the denominator represents the total number of n-grams in the predicted sequence.
In other words, pn p_npnis the ratio of two quantities: the first is the number of matching metasyntaxes in the predicted sequence and the label sequence, and the second is the ratio of the number of metasyntaxes in the predicted sequence.
accomplish
def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
evaluation
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{
eng} => {
translation}, bleu {
bleu(translation, fra, k=2):.3f}')
