1. What is the snowflake algorithm SnowFlake?
SnowFlake is an algorithm adopted by Twitter to generate globally unique IDs with increasing trends in distributed systems.
Snowflake algorithm is a very common thing in distributed architecture, but generally you don’t need to go deep into it
- On the one hand, general personal projects do not use large-scale architectures such as distributed
- On the other hand, even if it needs to be used, many ID generators on the market can also help us complete this work.
2. Problems caused by sub-database and sub-table: global primary key avoidance problem
2.1 Detailed description of the problem
When generating table primary key IDs, primary key auto-increment or UUID can be considered, but they all have obvious disadvantages. Primary
key auto-increment:
(1) Auto-increment IDs are easy to be traversed by crawlers.
(2) There will be ID conflicts in sub-table and sub-database.
UUID:
(1) Too long, and there are index fragments, and the index takes up too much space
(2) Out of order. It is not possible to sort by primary key.
2.2 Problem solving method
Consider using the snowflake ID as the primary key of the database. The snowflake algorithm is very suitable for generating unique IDs in distributed scenarios, which can ensure uniqueness and sorting.
In order to improve the efficiency of producing Snowflake ID, the operation of the data in it is bit operation
Snowflake ID: Static inner class singleton mode to realize snowflake algorithm: https://www.cnblogs.com/qdhxhz/p/11372658.html
3. Characteristics of Distributed ID
3.1 Global Uniqueness
There should be no duplicate IDs, which is a basic requirement.
3.2 Incrementality
Make sure to generate IDs that are incremental for users or businesses.
3.3 High Availability
Make sure to generate the correct ID at all times.
3.4 High Performance
In a high-concurrency environment, it still performs well.
4. Common solutions and selection of distributed ID
4.1 UUID
4.1.1 Introduction
Java comes with an algorithm that generates a unique random 36-bit string (32 strings + 4 "-").
4.1.2 Advantages
- Guaranteed uniqueness
- And it is said to be enough for N billion years
4.1.3 Disadvantages
- Poor business readability
- cannot be incremented sequentially
4.2 Snowflake Algorithm SnowFlake
4.2.1 Introduction
It is Twitter's open source distributed ID composed of 64-bit integers
https://github.com/twitter-archive/snowflake
4.2.2 Advantages
Higher performance
Incremental on a single machine
4.3 UidGenerator
4.3.1 Introduction
Baidu's open source distributed ID generator
is implemented based on the snowflake algorithm
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
4.4 Leaf
4.1.1 Introduction
- Meituan open source distributed ID generator
- Meituan Comments Distributed ID Generation System
https://tech.meituan.com/2017/04/21/mt-leaf.html
https://tech.meituan.com/MT_Leaf.html
4.1.2 Advantages
Guaranteed to be globally unique and
trend increasing
4.1.3 Disadvantages
Requires middleware such as dependency database and ZK
Five, the components of the snowflake algorithm
Since the 64-bit integer in Java is of type long, the id generated by the SnowFlake algorithm in Java is stored in long.
The result of the ID generated by the SnowFlake algorithm is a 64bit integer, and its structure is as follows:
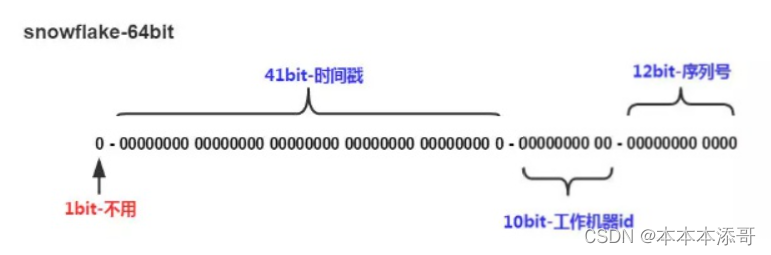
Components (64bit)
5.1 The first bit (occupies 1 bit)
Its value is always 0 and has no practical effect.
Because the highest bit in binary is the sign bit, 1 means a negative number and 0 means a positive number.
The generated IDs are all positive integers, so the highest bit is fixed at 0.
5.2 Timestamp (occupies 41bit)
In total, it can hold about 69 years.
Accurate to the millisecond level, the length of 41 bits can be used for 69 years.
Another important function of time bits is that they can be sorted according to time.
5.3 Working machine id (occupies 10bit)
Among them, the high-order 5bit is the data center ID, and the low-order 5bit is the working node ID, which can accommodate up to 1024 nodes.
10-digit machine ID, the length of 10 digits supports the deployment of up to 1024 nodes.
5.4 Serial number (occupies 12bit)
Each node starts to accumulate from 0 every millisecond, and can accumulate up to 4095, and a total of 4096 IDs can be generated.
The serial number is a series of self-incrementing ids, which can support the same node to generate multiple ID serial numbers in the same millisecond.
The largest positive integer that can be represented is 2^12 -1 = 4095, that is, 4095 numbers of 0, 1, 2, 3, ... 4094 can be used to represent 4095 ID serial numbers generated by the same machine within the same time interval (milliseconds) .
How many globally unique IDs can the SnowFlake algorithm generate in the same millisecond:
Number of IDs in the same millisecond = 1024 X 4096 = 4194304