I. Background
In MySQL, almost all data tables will have a primary key, the master key is not allowed to repeat, the id of each data table are not the same.
Id primary key may be a number, or a string, will generally select number as a primary key id, numeric type, can be divided into int, long, float, double these categories (subdivided), to create the tables when the data type will be selected based on the expected amount of data.
For this type of primary numeric key, when inserting a new record, there are two options: 1, id increment, insert the data, id field is ignored (or set to null, will automatically increment id); 2, insert data when the value of the id specified manually. Two methods have advantages and disadvantages.
II. Increment primary key id advantages and disadvantages
Advantages and disadvantages can refer to the online blog: https://www.jianshu.com/p/f5d87ceac754
Despite the shortcomings of the above mentioned blog post aside (because so far I have not encountered such a problem), I usually have more problems, this is the following:
1, there is a data, multiple systems would share.
2, when the data are generated, all relevant systems can be based on an identification (id) to find out which data records.
You might think, after data generation, I first put in storage because there is a primary key id (increment) after the data storage, then I contains the primary key id check out the data, and then distributed to other systems, so that all systems You can know the id of this data.
However, there is a problem here, after storage, storage before you how to find out which of the data? In many cases, the only sign of data only primary key, this time how to do? Especially when inserted particularly high frequency, how to find the exact piece of data? It is almost impossible! Unless, at the time of insertion of data, specify the id.
III. Id manually specify the primary key strengths and weaknesses
Manually specify the primary key advantage of the id (id without increment) can solve the above problems;
Obvious shortcomings, is the primary key id prone to conflict, when inserted into the frequency reaches a certain level, there will be a lot of such problems, once this problem occurs, storage will fail, resulting in loss of data (application-level exception handling can be done to avoid data loss).
In fact, we only need to solve the problem of duplicate primary key id ok, right.
So how does the main generating duplicate primary keys id it? Especially in the current prevalence of distributed architecture, a large amount of data generated from different nodes, how to ensure that each piece of data can be assigned a unique id, this is a problem.
There are already a variety of algorithms, such as UUID, SnowFlake algorithm, there are some middleware, redis and zk also has its own unique id generation algorithm.
You can refer to:
Four. UUID algorithm
About algorithm introduced uuid, refer to Baidu Encyclopedia: https://baike.baidu.com/item/UUID
In Java UUID tools (java.util.UUID), may generate a hexadecimal string 128bit (32 bytes), the 4 "-" will be divided into a hexadecimal string section 5, rule 8-4-4-4-12, a total of 36, each section has a special meaning, such as: 4ab1416b-cafc-4932-b052-cd963aff22eb.
Here is an example:
java.util.UUID Import;
public class UuidDemo {
public static void main (String [] args) {
Final UUID.randomUUID the UUID = UUID ();
System.out.println (UUID);
// 4ab1416b-CAFC-4932-B052 -cd963aff22eb
// total 128bit (32 bytes) plus 4 - separator, a total of 36 rules are 8-4-4-4-12
}
}
Five. Snowflake algorithm
snowflake twitter open source is an algorithm that can generate globally unique id.
Id is generated by a 64bit the figure , which can be divided into four 64bit portion, as shown, each part has a special meaning:
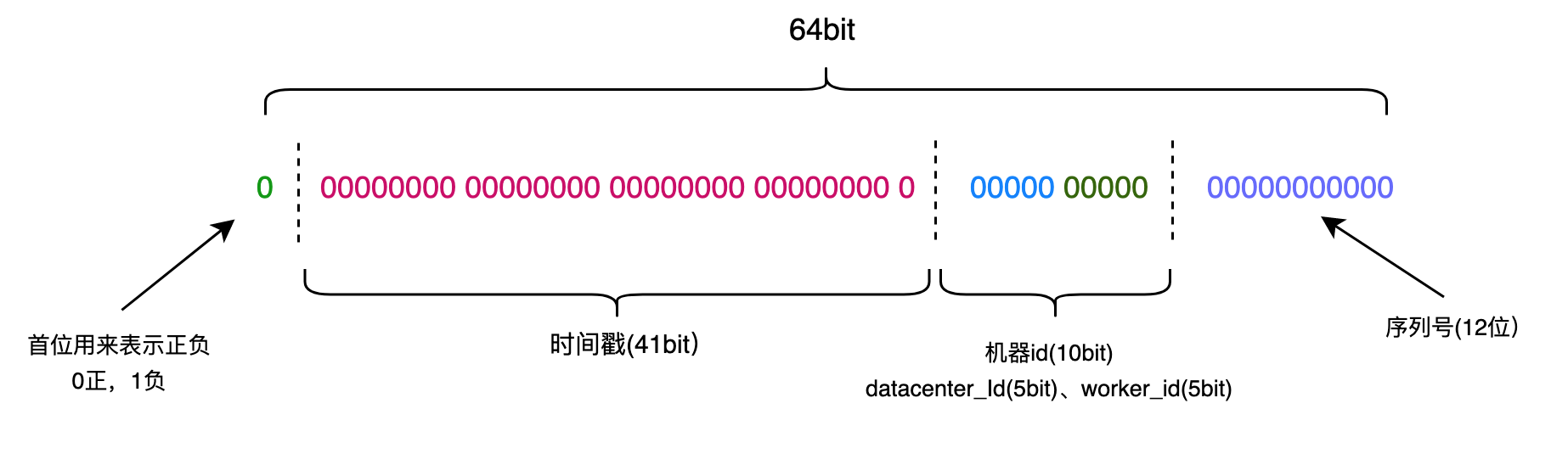
Snowflake code that implements the algorithm is as follows:
cn.ganlixin.ssm.util.common Package;
public class SnowFlakeIdGenerator {
// truncated initial time (2017-01-01)
Private Long INITIAL_TIME_STAMP = Final static 1483200000000L;
// number of bits occupied by the machine id
private static final long WORKER_ID_BITS = 5L;
// data to identify the number of bits occupied by id
Private static Final Long DATACENTER_ID_BITS = 5L;
// maximum supported machine id, the result is 31 (this shift algorithm can quickly calculate several binary number can be represented the maximum number of decimal)
Private Long Final static MAX_WORKER_ID = ~ (-1L << WORKER_ID_BITS);
the maximum data identification id // support, the result is 31 is
Private Long Final static MAX_DATACENTER_ID = ~ (-1L << DATACENTER_ID_BITS);
// sequence id accounted bits
private final long SEQUENCE_BITS = 12L;
offset // ID of the machine (12)
private final long WORKERID_OFFSET = SEQUENCE_BITS;
offset // ID of the data center (12 is +. 5)
Private Long DATACENTERID_OFFSET = Final SEQUENCE_BITS + WORKER_ID_BITS;
offset time // truncated (. 5 + + 12 is. 5)
Private Long TIMESTAMP_OFFSET = Final + + SEQUENCE_BITS WORKER_ID_BITS DATACENTER_ID_BITS;
// generating a mask sequence, here 4095 (0b111111111111 = 0xFFF = 4095)
Private Long SEQUENCE_MASK = Final ~ (-1L << SEQUENCE_BITS);
// data center ID (~ 31 is 0)
Private Long datacenterId;
// working node ID (~ 31 is 0)
Private Long workerId;
the // ms sequence (0 ~ 4095)
Private Long sequence = 0L;
// time of the last generation ID sectional
Private Long LastTimestamp = -1L;
/ * *
* constructor
*
* @Param datacenterId data center ID (~ 31 is 0)
*
* @Param workerId Job ID (~ 31 is 0)
* /
public SnowFlakeIdGenerator (datacenterId Long, Long workerId) {
IF (workerId> MAX_WORKER_ID || workerId <0) {
the throw new new an IllegalArgumentException (String.format ( "% d is not greater than or WorkerID less than 0 ", MAX_WORKER_ID));
}
IF (datacenterId> MAX_DATACENTER_ID || datacenterId <0) {
the throw new new an IllegalArgumentException (String.format ("% d dataCenterID not be greater than or less than 0 ", MAX_DATACENTER_ID));
}
this.workerId = workerId ;
this.datacenterId = datacenterId;
}
/ **
* get the next ID (thread-safe with synchronization lock)
* @return SnowflakeId
* /
Long nextId the synchronized public () {
// ms time stamp (13)
Long timestamp = System.currentTimeMillis ();
// if the current time is less than the timestamp of the last generation ID, indicating the system clock backoff time should be thrown through the abnormal
IF (timestamp <LastTimestamp) {
the throw a RuntimeException new new ( "current time is less than the last timestamp recorded!");
}
// if it is generated at the same time, the sequence milliseconds
IF (LastTimestamp == timestamp) {
sequence = (+ sequence. 1) & SEQUENCE_MASK;
// sequence equal to 0 milliseconds sequence has been described to increase the maximum
IF (sequence == 0) {
// blocking the next millisecond, obtain a new timestamp
timestamp = tilNextMillis (lastTimestamp) ;
}
} the else {
// change timestamp, sequence milliseconds reset
sequence = 0L;
}
// last generated ID sectional time
LastTimestamp = timestamp;
// shift to fight and consisting of 64-bit ID ORed together
return ((timestamp - INITIAL_TIME_STAMP) << TIMESTAMP_OFFSET)
| (datacenterId << DATACENTERID_OFFSET)
| ( << WORKERID_OFFSET workerId)
| Sequence;
}
/ **
* obstruction to the next millisecond, until a new timestamp
*
* @param LastTimestamp last run sectional ID
* @return current timestamp
* /
protected Long tilNextMillis (Long LastTimestamp) {
Long timestamp = System.currentTimeMillis ();
the while (timestamp <= LastTimestamp) {
timestamp = System.currentTimeMillis ();
}
return timestamp;
}
}
Test use:
package cn.ganlixin.ssm.util;
import org.junit.Test;
public class SnowFlakeGeneratorTest {
@Test
public void testGen() {
SnowFlakeIdGenerator idGenerator = new SnowFlakeIdGenerator(1, 1);
System.out.println(idGenerator.nextId()); // 429048574572105728
}
}