Article directory

Conference/Journal: 2023 AAAI
论文题目:《Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning》
论文链接:[JeffWang987/MOVEDepth: AAAI 2023]Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning (github.com)
Open source code: AutoAILab/DynamicDepth (github.com)
solved problem
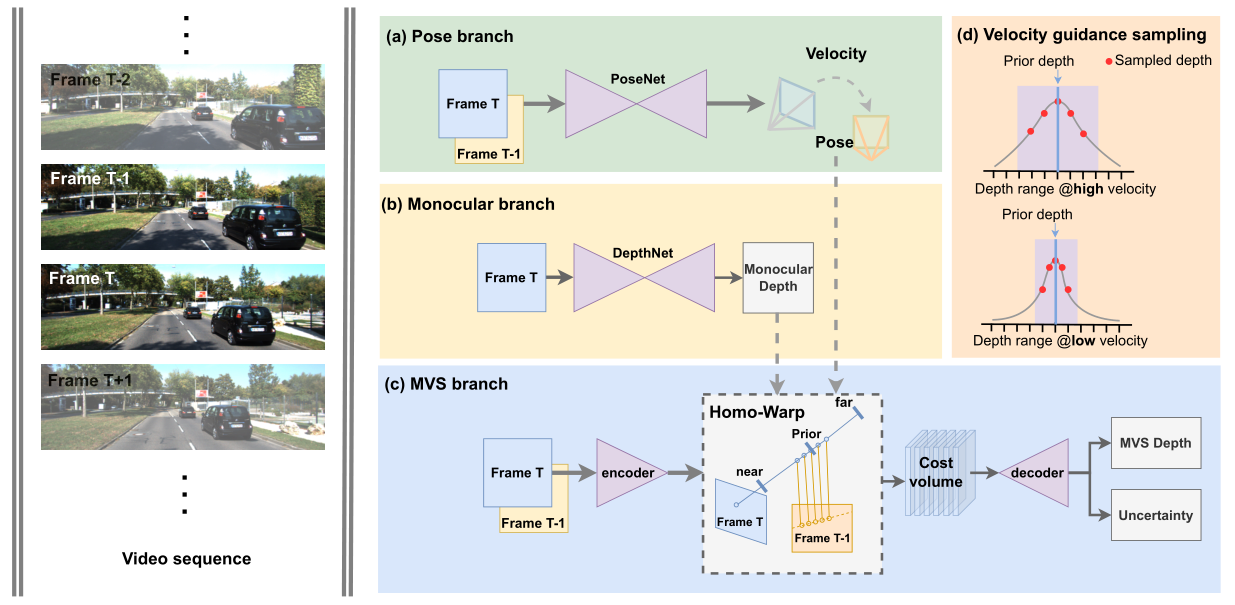
MOVEDepth no longer uses the MonoDepth decoder to directly decode the depth from the cost volume, but follows the paradigm in the MVS field, and returns the depth from the cost volume. MOVEDepth believes that using the cost volume can preserve the geometric information to the greatest extent and obtain a more accurate depth Estimated results. However, as mentioned in ManyDepth and DepthFormer, it is not ideal to regress the depth result directly from the cost volume. This is because in the field of monocular multi-frame depth estimation, there are many "uncertain factors", such as camera static (static frame), Weak textures, reflective areas, dynamic scenes, etc.
In order to solve these problems, MOVEDepth uses information such as single-frame depth prior and predicted vehicle speed to construct a lightweight cost volume to decode depth.
implementation details
-
Pose branch uses posenet to estimate camera extrinsics, which is consistent with previous work.
-
The Monocular branch uses the monocular depth estimation network to predict the "rough" prior depth. DepthNet can be any current monocular model. The author gives two models, MonoDepth2 and PackNet, in the experimental part.
-
MVS branch follows the traditional MVSNet paradigm, the only difference is that in the Homo-warp stage, MOVEDepth does not sample the global depth, but samples near the monocular prior depth (monocular priority), as shown in the figure below. (Note that ManyDepth and DepthFormer use 96 and 128 prior depths respectively, while MOVEDepth only samples 16 depth candidates due to the prior depth )
-
Velocity guidance sampling, mentioned above that MOVEDepth samples 16 depth points near the depth prior, but does not constrain the range of depth sampling. Different from ManyDepth, MOVEDepth no longer uses the learning scheme to learn the range to be sampled, but dynamically adjusts the depth search range according to the predicted vehicle speed (estimated by posenet). The Motivation is: if the camera moves faster, the stereo baseline of the two frames before and after will be larger, which is more in line with the triangulation prior of MVS, and a more accurate depth can be obtained, which means that MVS will be more reliable, so this article adds depth search scope. On the contrary, if the camera moves slowly, or even is still, the scene captured in the two frames before and after does not change, and there is no geometric correlation of MVS. Therefore, MVS is not reliable at this time. We need to narrow the depth search range so that the output of MVS is close to the result of monocular depth estimation. The specific depth search range formula is as follows (it is worth mentioning that the author gives the specific in the appendix The geometric derivation of , deduced that the stereo basleine and the camera motion speed of the two frames before and after are linearly related ):
d min = D Mono ( 1 − β T ( v ) ) d max = D Mono ( 1 + β T ( v ) ) \begin{aligned} d_{\min } & =D_{\text {Mono }}(1-\beta \mathcal{T}(v)) \\ d_{\max } & =D_{\text {Mono }}(1+\beta \mathcal{T}(v)) \end{aligned}dmindmax=DMono (1−βT(v))=DMono (1+βT(v))
v = α ∥ T ∥ 2 v=\alpha\|\mathbf{T}\|_{2} v=α∥T∥2, T is the camera translation matrix estimated by posenet, α is the camera frame rate, β is the hyperparameter, T( ) is the scaling function that transforms v into the real world -
In order to solve problems such as dynamic scenes , MOVEDepth proposes Uncertainty-Based Depth Fusing. Specifically, the reliability of the MVS local area is learned from the entropy function of the cost volume, and then the single-frame depth prior and multi-frame depth are used as weights. Fusion:
U ( p ) = θ u ( ∑ j = 0 D − 1 − pj log pj ) D Fuse = U ⊙ D Mono + ( 1 − U ) ⊙ DMVS \begin{array}{c} \mathbf{U }(\mathbf{p})=\theta_{\mathrm{u}}\left(\sum_{j=0}^{D-1}-\mathbf{p}_{j} \log \mathbf{p }_{j}\right) \\ D_{\text {Fuse }}=\mathbf{U} \odot D_{\text {Mono }}+(\mathbf{1}-\mathbf{U}) \odot D_{\mathrm{MVS}} \end{array}U(p)=iu(∑j=0D−1−pjlogpj)DFuse =U⊙DMono +(1−U)⊙DMVS
It can be seen from the visualization that the uncertain region learned from the cost volume of the deep fusion part of the network is on dynamic vehicles and pedestrians, which helps to alleviate the problems caused by multi-frame depth estimation in dynamic scenes:
The image on the right is the learned uncertainty map (white: sure, black: not sure)
Summarize
MOVEDepth uses the monocular depth prior and predicted vehicle speed information to dynamically construct the cost volume and regress the depth according to the paradigm of the MVS field, and explores how to better combine single-frame depth estimation and multi-frame depth estimation to obtain more accurate prediction results . But the possible problems of MOVEDepth are:
-
Although only 16 depth assumption points are used in the MVS part, the monocular prior network is still required, which undoubtedly increases the learning burden.
Possible problems with pth are: -
Although only 16 depth assumption points are used in the MVS part, the monocular prior network is still required, which undoubtedly increases the learning burden.
-
In the dynamic part, it is still "curve to save the country", starting from the entropy function of cost volume, learning the untrustworthy area brought by dynamic objects, not directly processing dynamic objects, so the performance still needs to be improved. (It is worth mentioning that the current method of processing dynamic objects is similar to this "curve to save the country" scheme, which is to use the pre-trained segmentation network, which is not "beautiful" and the effect is not experienced, so how to deal with it elegantly Dynamic objects will be an open problem)