Click on "3D Vision Workshop" above and select "Star"
Dry goods delivered as soon as possible

Author丨Bubble Robot
Source丨Bubble Robot SLAM
标题: Three Ways to Improve Semantic Segmentationwith Self-Supervised Depth Estimation
Authors: Lukas Hoyer, Dengxin DaiYuhua Chen, Guangming Shi
Source: arXiv 2021
Compilation: cristin
Review: zhh

Summary

Hello everyone, today I bring you the article Three Ways to Improve Semantic Segmentation with Self-Supervised Depth Estimation.
Training deep networks for semantic segmentation requires large amounts of labeled training data, which is a significant challenge in practice because labeling segmentation masks is a highly labor-intensive process. To address this issue, we propose a semi-supervised semantic segmentation framework augmented by self-supervised monocular depth estimation from unlabeled image sequences. In particular, we propose three main contributions: (1) we transfer the feature knowledge learned during self-supervised depth estimation to semantic segmentation; (2) we achieve robust Data enhancement; (3) We also use deep feature diversity to select the most useful samples for semantic segmentation under the student-teacher framework according to the level of learning difficulty. We validate the proposed model on the Cityscapes dataset, where the modules show significant performance gains, and we achieve state-of-the-art results in semi-supervised semantic segmentation.

Main work and contribution

The main advantage of our method is that we can learn from a large number of easily accessible sequences of unlabeled images and use the learned knowledge to improve semantic segmentation performance in various ways. Our contributions are summarized as follows:
1) To our knowledge, we are the first to utilize SDE as an auxiliary task to exploit unlabeled image sequences and significantly improve the performance of semi-supervised semantic segmentation.
2) We propose DepthMix, a powerful data augmentation strategy that respects the geometry of the scene, combined with (1) to achieve state-of-the-art results in semi-supervised semantic segmentation.
3) To improve the flexibility of active learning, we propose an SDE-based method for automatic annotated data selection. It replaces human annotators with SDE oracles and raises the requirement to use human in data selection loops.

Algorithm flow

1. System Framework
In this work, we propose a triple method utilizing self-supervised monocular depth estimation (SDE) to improve the performance of semantic segmentation and reduce the amount of annotations required. Our contributions span the overall learning process, from data selection, data augmentation, to cross-task representation learning, while achieving unification through the use of SDE.
In this section, we introduce three approaches to improve semantic segmentation performance using self-supervised depth estimation (SDE). They focus on three distinct aspects of semantic segmentation, including annotation data selection, data augmentation, and multi-task learning. Given N images and K image sequences from the same task, our first approach is to annotate automatic data selection, using SDE learned on K (unlabeled) sequences to select NA images from N images for human annotation (see Alg.1). Our second approach, called DepthMix, leverages the learned SDE to create geometrically plausible "virtual" training samples from pairs of labeled images and their annotations (see Figure 1). The third method is to use SDE as an auxiliary task to learn semantic segmentation under the multi-task framework (see Figure 2). Learning is enhanced by a multi-task pre-training process that combines SDE and image classification.
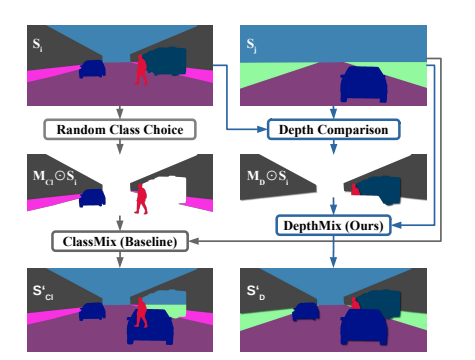
Figure 1. The proposed concept of DepthMix augmentation and its baseline class mix. By leveraging SDE, DepthMix mitigates geometric artifacts.

Figure 2. Architecture for learning semantic segmentation using SDE as an auxiliary task. The dashed path is only used during training, and only when image sequences and/or segmentation ground truths are available for training samples.
2. Method

2.1 Automatic data selection for annotations
We use SDE as a surrogate task to select NA samples from a set of N unlabeled samples for humans to create semantic segmentation labels. Similar to the standard active learning cycle (model training), selection is done incrementally in multiple steps → Query Selection → Annotation → Model Training. However, our data selection is completely automatic and requires no human involvement, as the annotation is done by the proxy task SDE oracle.
Diversity Sampling: To ensure that the selected annotated samples are sufficiently diverse to represent the entire dataset well, we use an iterative furthest point sampling based on features computed by the middle layers of the SDE network ΦL2 on SDE distance.
Uncertainty Sampling: While diversity sampling is able to select different new samples, it does not know the uncertainty of the semantic segmentation model about these samples. The purpose of uncertainty sampling is to select difficult samples.
2.2 DepthMix data enhancement
Inspired by recent successful data augmentation methods, we propose an algorithm called DepthMix that utilizes self-supervised depth estimation to preserve scene structure integrity during the mixing process, which mixes pairs of images and their (pseudo) labels to generate more training samples for semantic segmentation.
Given two images Ii and Ij of the same size, we want to copy some regions from Ii and paste them directly into Ij to get a dummy sample I0. The copied area is represented by mask M, which is a binary image of the same size as the two images. The image creation process is as follows
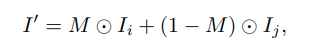
Our DepthMix is designed to alleviate this problem. It uses the estimated depths Diˆ and Djˆ of the two images to generate a blending mask M that follows the geometric relationship. It achieves that the depth value is smaller than the pixel depth value of the same position in Ij only by selecting pixels from Ii:
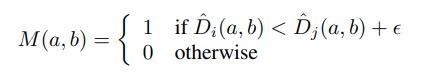
2.3 Semi-supervised Semantic Segmentation
We utilize the labeled image dataset GA, the unlabeled image dataset GU, and K unlabeled image sequences to train a semantic segmentation model. We first discuss how to utilize SDE for semantic segmentation of image sequences. Then, we show how GU can be used to further improve performance.
To properly initialize the pose estimation network and deep decoder, the structure is first trained on K sequences of unlabeled images for SDE. Typically, we initialize the encoder with ImageNet weights because they provide useful semantic features learned during image classification. To avoid forgetting semantic features during SDE pre-training, we exploit the feature distance loss between the current bottleneck feature f Eθ and the encoder’s bottleneck feature, the image net weight f EI:
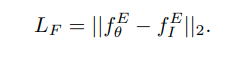
The loss for deep pretraining is a weighted sum of the SDE loss and the ImageNet feature distance loss:
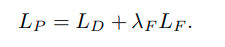

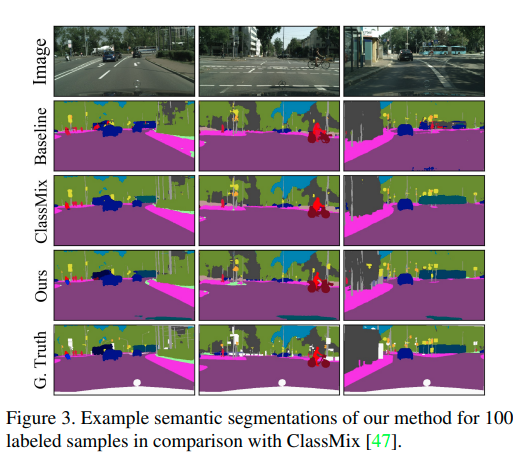
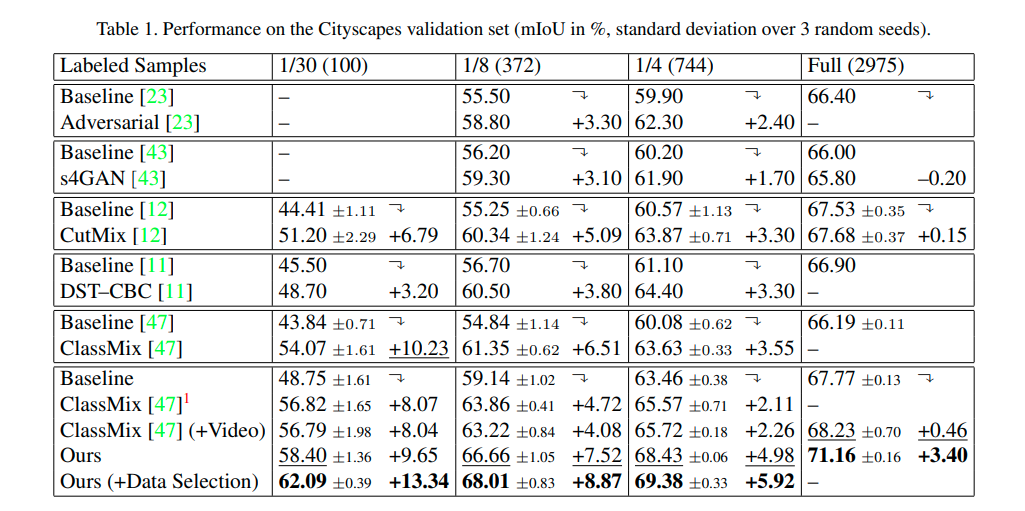
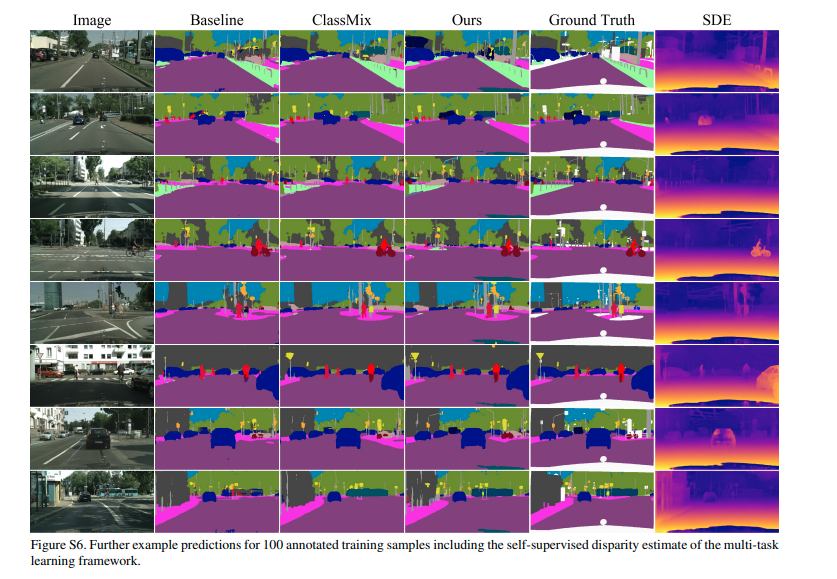
Experimental results


Click to read the original text , you can get the download link of this article.
This article is for academic sharing only, if there is any infringement, please contact to delete the article.
Dry goods download and study
Backstage reply: Barcelona Autonomous University courseware, you can download the 3D Vison high-quality courseware accumulated by foreign universities for several years
Background reply: computer vision books, you can download the pdf of classic books in the field of 3D vision
Backstage reply: 3D vision courses, you can learn excellent courses in the field of 3D vision
3D visual quality courses recommended:
1. Multi-sensor data fusion technology for autonomous driving
2. A full-stack learning route for 3D point cloud target detection in the field of autonomous driving! (Single-modal + multi-modal/data + code)
3. Thoroughly understand visual 3D reconstruction: principle analysis, code explanation, and optimization and improvement
4. The first domestic point cloud processing course for industrial-level combat
5. Laser-vision -IMU-GPS fusion SLAM algorithm sorting
and code
explanation
Indoor and outdoor laser SLAM key algorithm principle, code and actual combat (cartographer + LOAM + LIO-SAM)
9. Build a structured light 3D reconstruction system from scratch [theory + source code + practice]
10. Monocular depth estimation method: algorithm sorting and code implementation
11. The actual deployment of deep learning models in autonomous driving
12. Camera model and calibration (monocular + binocular + fisheye)
13. Heavy! Quadcopters: Algorithms and Practice
14. ROS2 from entry to mastery: theory and practice
15. The first 3D defect detection tutorial in China: theory, source code and actual combat
Heavy! 3DCVer- Academic paper writing and submission exchange group has been established
Scan the code to add a WeChat assistant, and you can apply to join the 3D Vision Workshop - Academic Paper Writing and Submission WeChat exchange group, which aims to exchange writing and submission matters such as top conferences, top journals, SCI, and EI.
At the same time , you can also apply to join our subdivision direction exchange group. At present, there are mainly 3D vision , CV & deep learning , SLAM , 3D reconstruction , point cloud post-processing , automatic driving, multi-sensor fusion, CV introduction, 3D measurement, VR/AR, 3D face recognition, medical imaging, defect detection, pedestrian re-identification, target tracking, visual product landing, visual competition, license plate recognition, hardware selection, academic exchanges, job search exchanges, ORB-SLAM series source code exchanges, depth estimation and other WeChat groups .
Be sure to note: research direction + school/company + nickname , for example: "3D Vision + Shanghai Jiaotong University + Jingjing". Please note according to the format, it can be quickly passed and invited to the group. Please contact for original submissions .

▲Long press to add WeChat group or contribute

▲Long press to follow the official account
3D vision from entry to proficient knowledge planet : video courses for 3D vision field ( 3D reconstruction series , 3D point cloud series , structured light series , hand-eye calibration , camera calibration , laser/vision SLAM, automatic driving, etc. ), summary of knowledge points , entry and advanced learning route, the latest paper sharing, and question answering for in-depth cultivation, and technical guidance from algorithm engineers from various large factories. At the same time, Planet will cooperate with well-known companies to release 3D vision-related algorithm development jobs and project docking information, creating a gathering area for die-hard fans that integrates technology and employment. Nearly 5,000 Planet members make common progress and knowledge for creating a better AI world. Planet Entrance:
Learn the core technology of 3D vision, scan and view the introduction, unconditional refund within 3 days

There are high-quality tutorial materials in the circle, answering questions and solving doubts, and helping you solve problems efficiently
I find it useful, please give a like and watch~ 