1. Background
Recently, the company adopts the Hbase scan method, and often encounters that the task cannot run out and the region read times out. Due to the full amount of scan data, the total number of rows is 1 billion and the number of columns is close to 500. According to the suggested solution, change to the Hbase snapshot read method to avoid excessive pressure on the region
2. Hbase snapshot principle
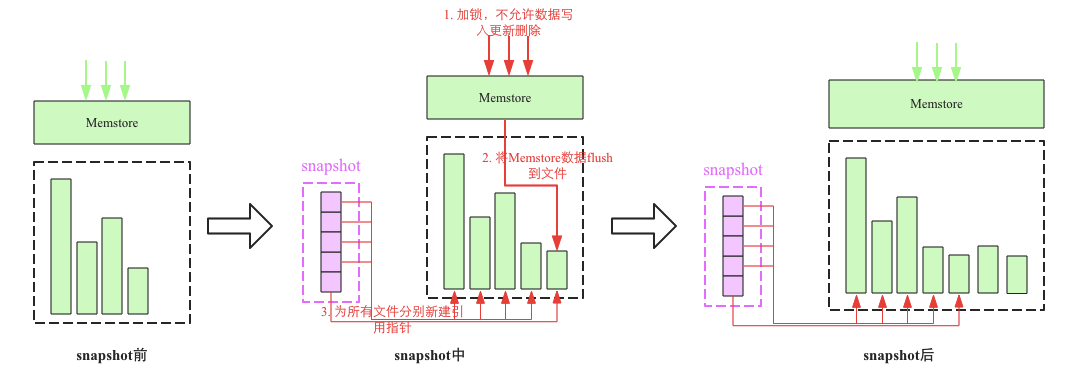
The snapshot process mainly involves 3 steps:
1. Add a global lock. At this time, no data is allowed to be written, updated or deleted.
2. Flush the cached data in Memstore to a file (optional)
3. Create new reference pointers for all HFile files, and these pointer metadata are snapshots
3. Actual online performance
After switching to snapshot scanning, the submitted tasks cannot be submitted for half a day, and the tasks can only be started after nearly an hour.
Generally, when the program is stuck, you will think of using jstack to view the stack information of the program
(1) View the process pid of the program (top command or ps -ef|grep command)
(2) Find the pid of the program and print the jstack information
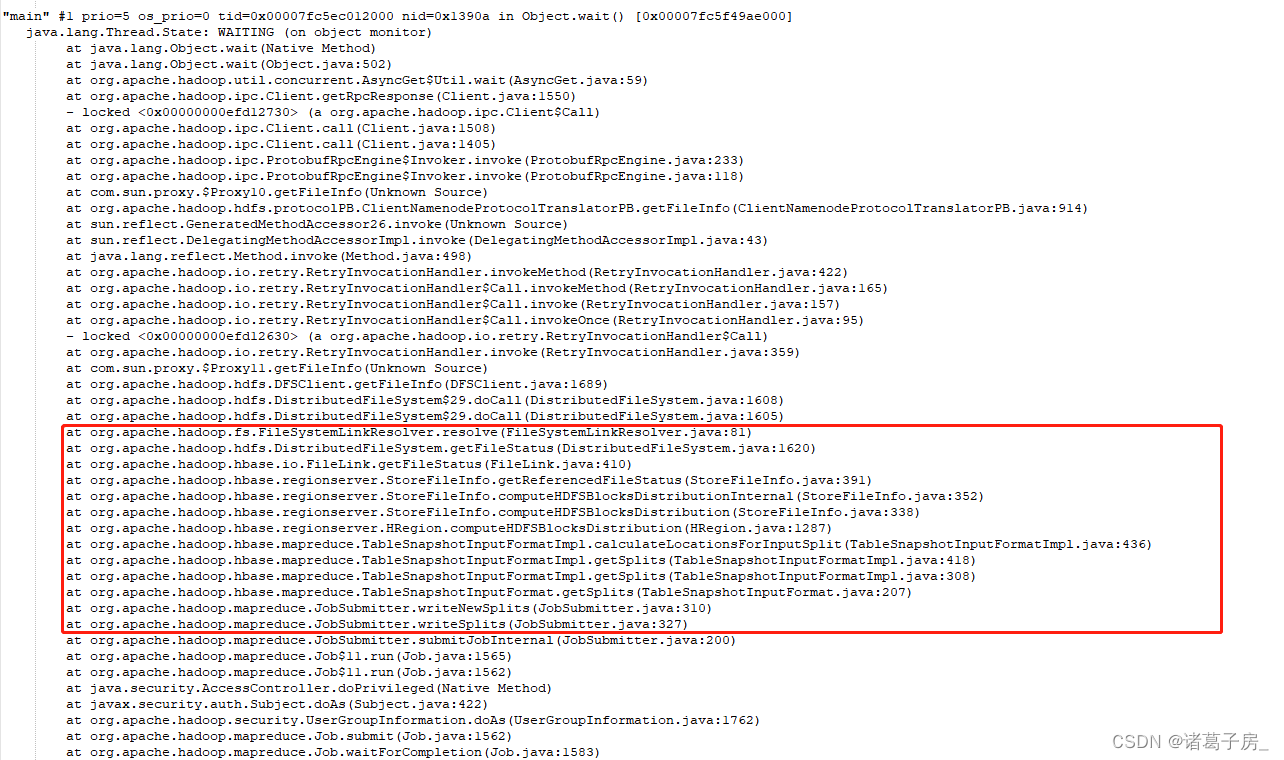
You can see that the program has been stuck in this place, and has been calculating the block information, find the corresponding Hbase source code, and view the corresponding code information
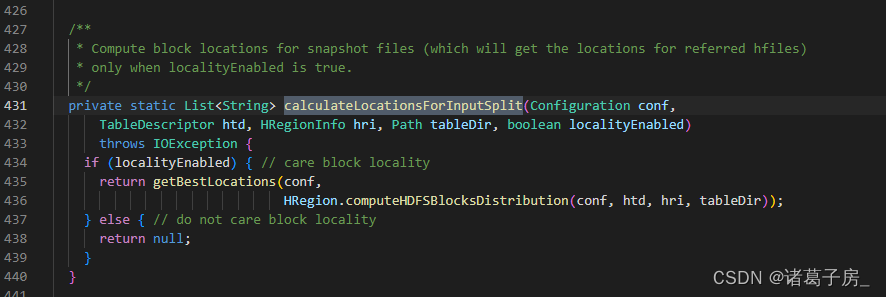
It can be seen that it is due to the calculation of block location information, so what is location?
Using chatGPT to query the meaning of hbase locality, we can find that it is actually data locality, and we do not need to calculate the locality ratio in our actual tasks, because we only need to be able to pull data, whether it is from local or remote

HBase locality的原理可以分为两个方面,即数据本地性和任务本地性。
数据本地性
在HBase中,数据是以Region的形式存储的,一个Region包含了一段连续的行键范围。每个Region都会被分配到一个RegionServer上进行管理,并在该RegionServer上存储它所包含的所有数据。
当客户端访问HBase中的数据时,它会首先向HBase的Master节点请求获取对应数据所在的RegionServer的信息,然后再从该RegionServer上获取所需的数据。如果客户端所在的节点与该数据所在的RegionServer节点相同,就可以直接在该节点上获取数据,避免了网络传输的延迟,从而提高了数据访问的效率。
任务本地性
HBase中的任务包括数据写入和数据查询两种类型。在HBase中,数据写入是通过向表中的RegionServer发送写请求来完成的。如果客户端所在的节点与该RegionServer节点相同,那么写请求可以直接发送到该节点上,从而实现本地写入。
另一方面,数据查询任务是由HBase的RegionServer节点完成的。当RegionServer节点接收到查询请求时,它会首先检查所需数据所在的Region是否已经在该节点上加载到内存中,如果是,则可以直接在该节点上执行查询操作,否则需要从其他节点上获取数据,这将导致额外的网络延迟和资源开销。
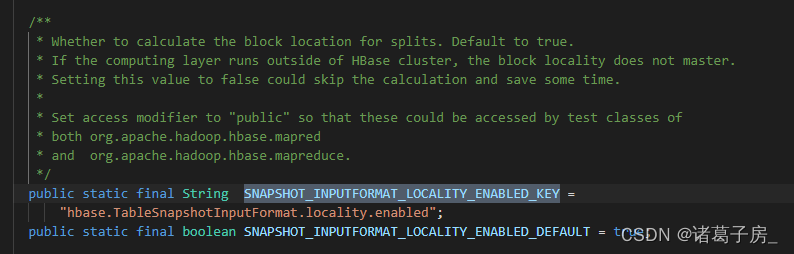
因此,为了最大化任务本地性,HBase通常会将数据分布在多个Region中,并将这些Region分配到尽可能多的节点上进行管理,从而最大化数据和任务之间的本地性。此外,HBase还提供了一些机制来管理Region的负载均衡和RegionServer节点的故障转移,以保证系统的高可用性和稳定性。In the end, you only need to set hbase.TableSnapshotInputFormat.locality.enabled to false at the place where the task is submitted , and the task submission will be very fast.
reference: