Target
During the tiring life process, enjoy the fun brought by other aspects. The goal is web crawlers, and I also learned about the content related to web page production. I organize it here, so that I can review it in the future and let everyone learn together and put forward my valuable opinions.
website
Image site: https://www.58pic.com/
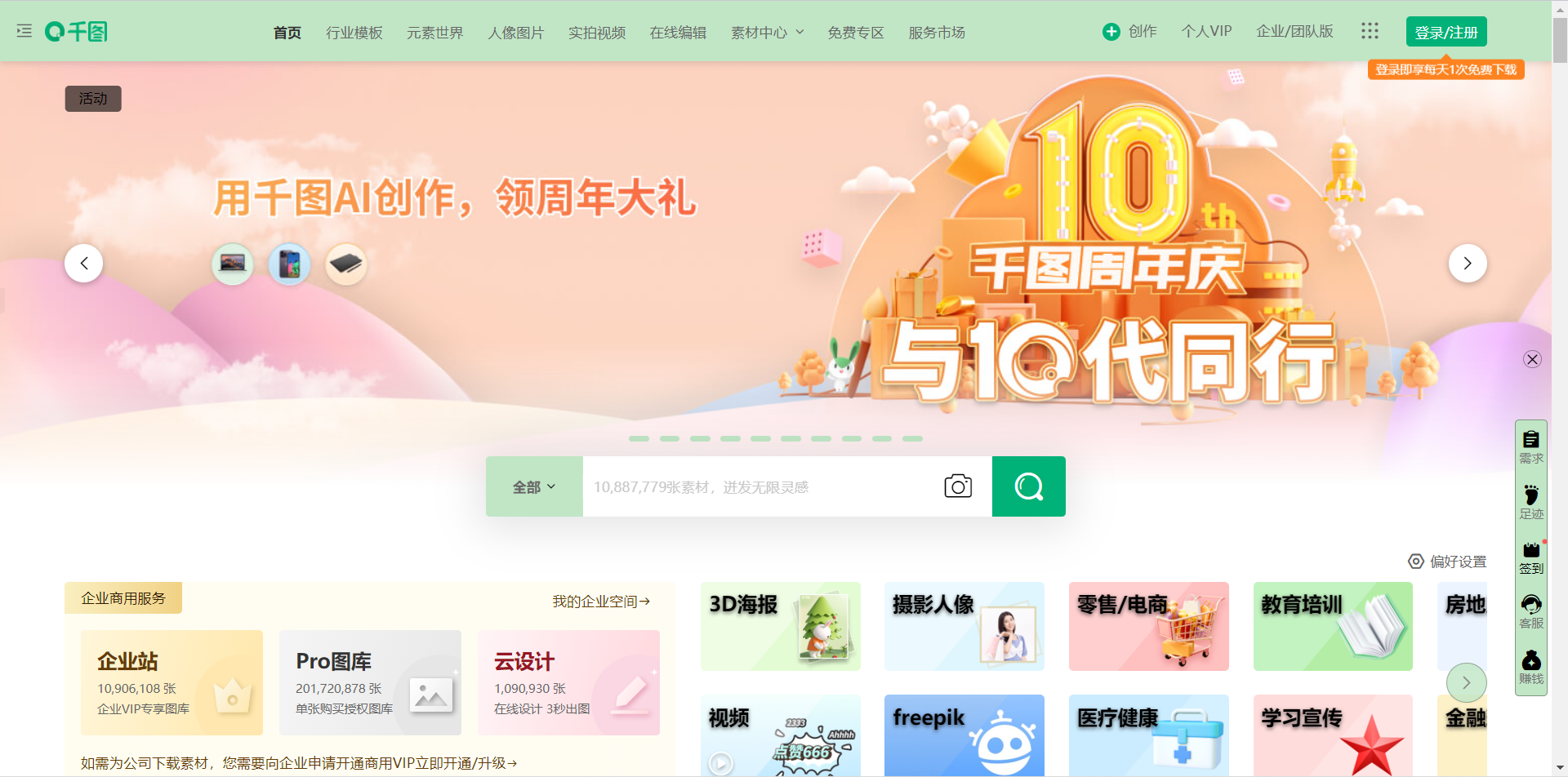
content
select site https://m.58pic.com/newpic/44666739.html
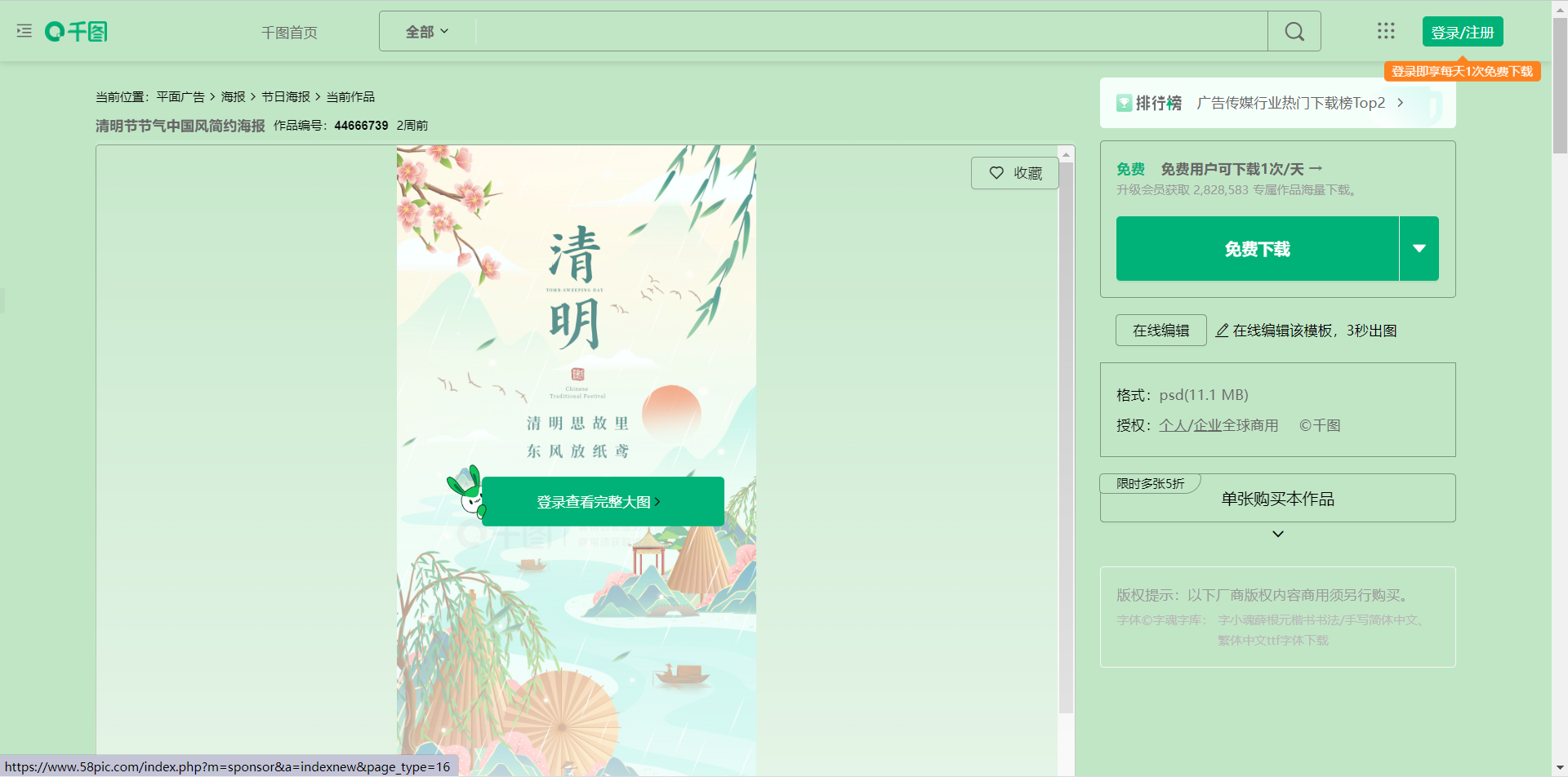
process:
crawl these small pictures

- Right mouse button selection
检测 - Click the arrow gesture in the image below
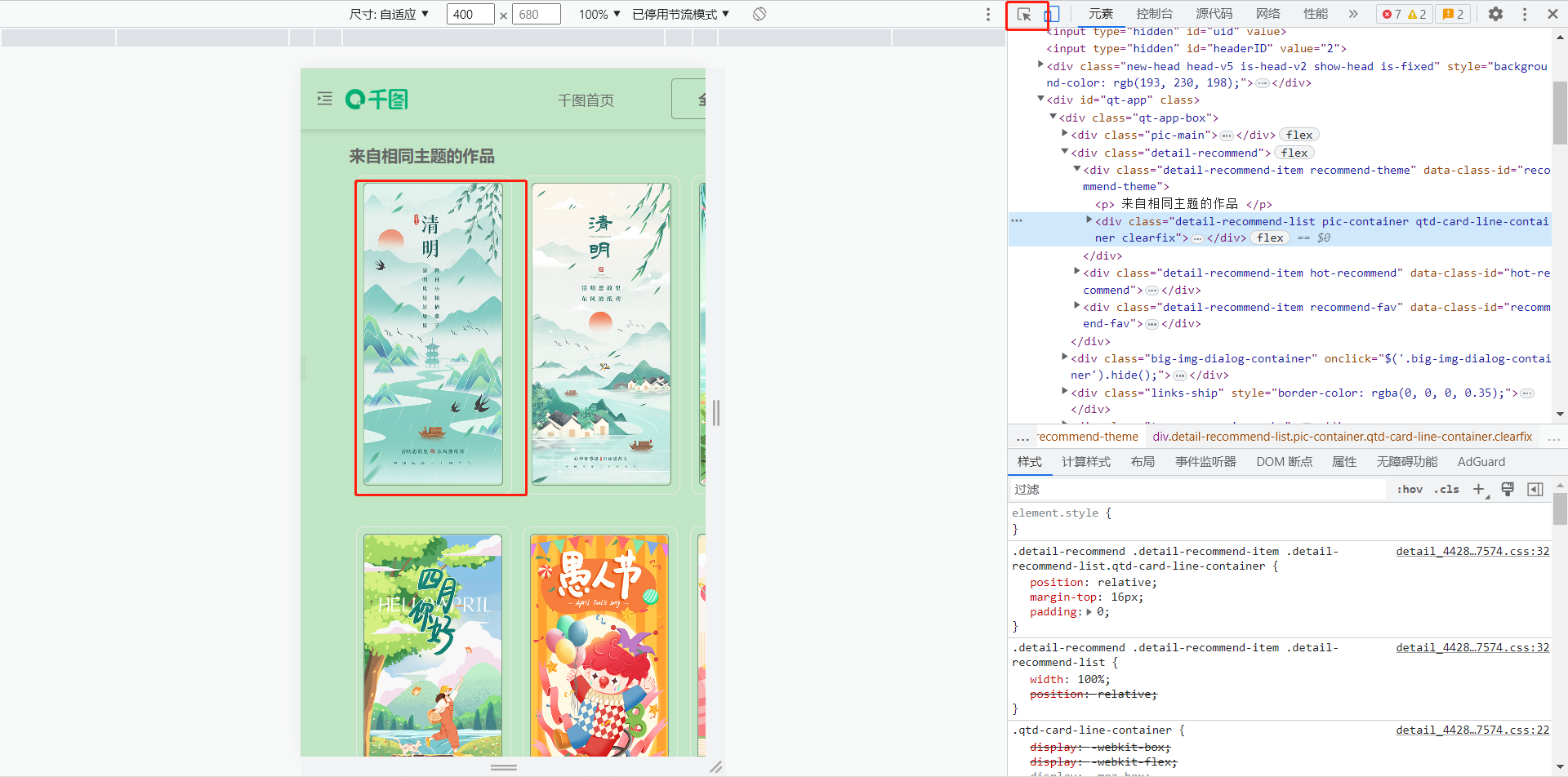
- After selecting the image, find the corresponding link (https://preview.qiantucdn.com/auto_machine/2023031…78c1be-f9a1-45bc-88bc-e9efe1269b58.jpg!qt_kuan320)
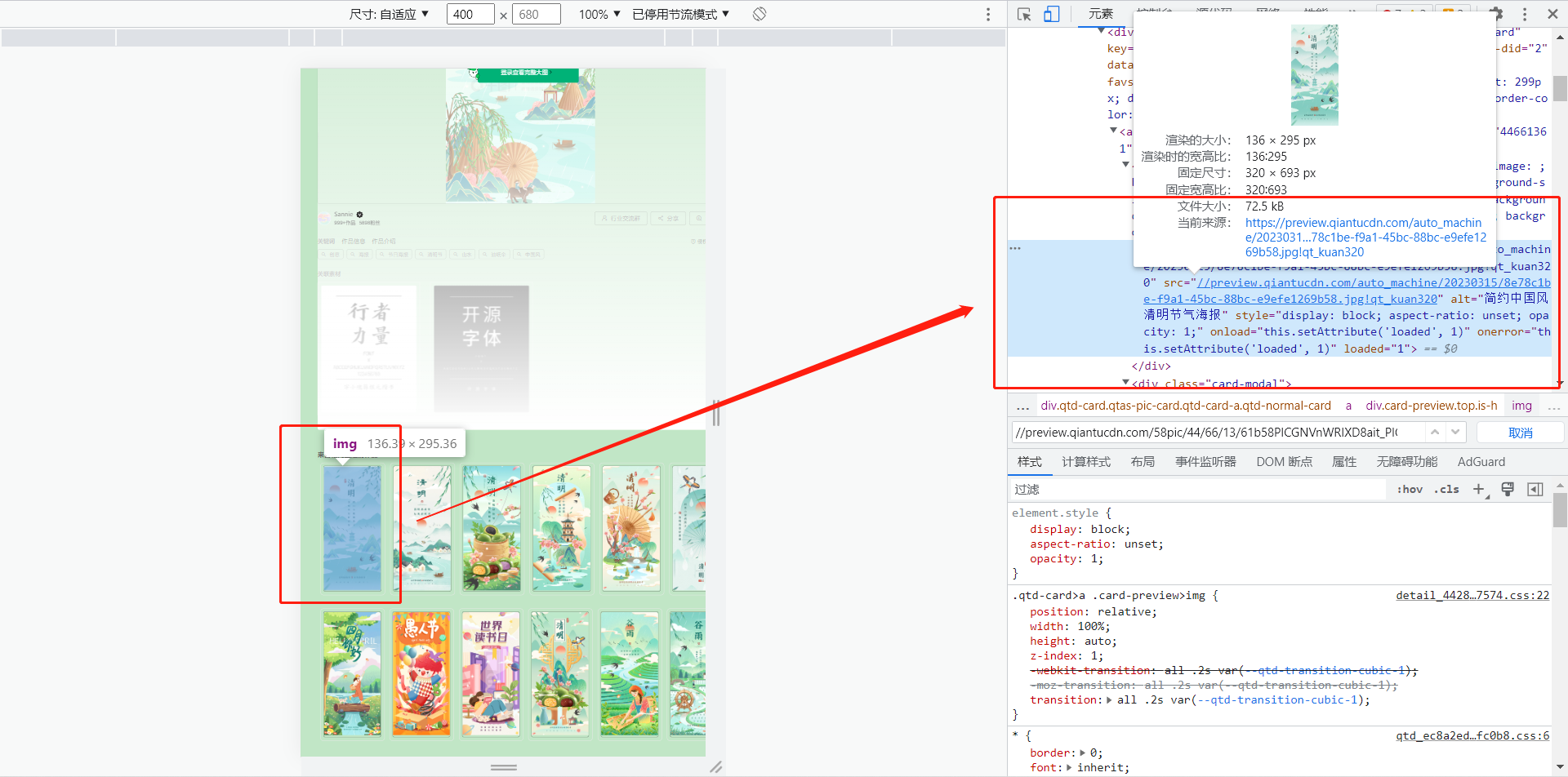
- right click
查看网页源代码
- Links to related images can be seen
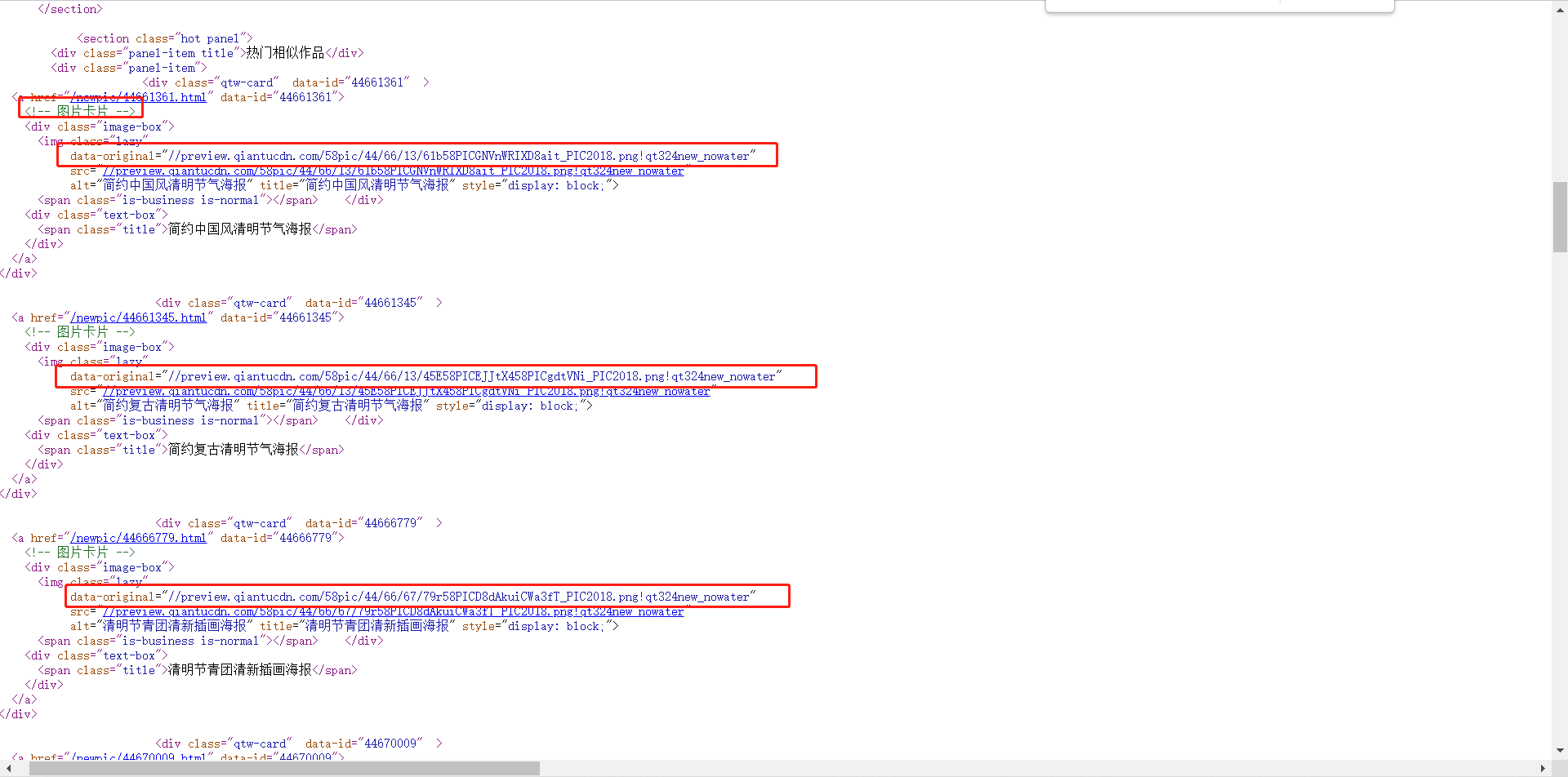
- Just
正则化表达式query this link and download the image
Code
import os
import time
import requests
import re
if __name__ == "__main__":
url = "https://m.58pic.com/newpic/44666739.html"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Mobile Safari/537.36'}
'''获取网页信息'''
response = requests.get(url=url, headers=headers, timeout=300)
html = response.text
# print(ret.text)
'''解析网页'''
urls = re.findall('data-original=".*?"', html)
print(urls)
save_path = "images"
os.makedirs(save_path, exist_ok=True)
'''保存图像'''
for idx, url in enumerate(urls):
time.sleep(1) # 密集请求容易对他人服务器造成影响
img = 'http://' + url.split('=')[-1][3:-1]
response = requests.get(img, headers=headers)
# 图像名称可以根据自己的情况进行设置
with open(save_path+"/"+str(idx)+'.jpg', 'wb') as f:
f.write(response.content)
Useful related content:
http://c.biancheng.net/view/2011.html