Introduction to Recurrent Neural Networks
Structure introduction
The basic structure of the cyclic neural network RNN is the structure of the BP network, which also has an input layer, a hidden layer and an output layer. It’s just that the output of the hidden layer in RNN can not only be passed to the output layer, but also can be passed to the hidden layer at the next moment, as shown in the figure below: Note: the 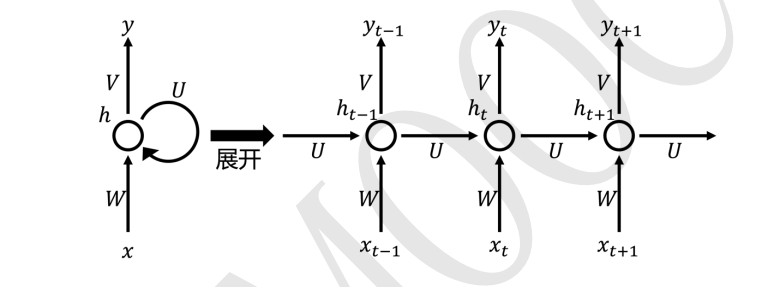
entire RNN structure shares a set of W, U, V, b , an important property of this RNN structure.
The structure of RNN can be expanded to the structure on the right, where xxx is the input signal,xt − 1 x_{t-1}xt−1is the input signal at time t-1, xt x_{t}xtis the input signal at time t, xt + 1 x_{t +1}xt+1for t + 1 {t+1}t+1 moment of the input signal. ht − 1 h_{t-1}ht−1is the hidden layer signal at time t-1, ht h_{t}htis the hidden layer signal at time t, ht + 1 h_{t+1}ht+1is the hidden layer signal at time t+1. yt − 1 y_{t-1}yt−1is the output layer signal at time t-1, yt y_{t}ytis the output layer signal at time t, yt + 1 y_{t+1}yt+1is the output layer signal at time t+1. W, U, V are the weight matrix of the network. h is a hidden initial
It can be observed from the structure that the biggest feature of RNN is that the information input in the previous sequence will affect the output of the model afterward.
Formula Derivation
There are two common models of RNN, one is Elman network and the other is Jordan network. Elman network and Jordan network are also known as Simple Recurrent Networks (SRN) or SimpleRNN, which is a simple recurrent neural network.
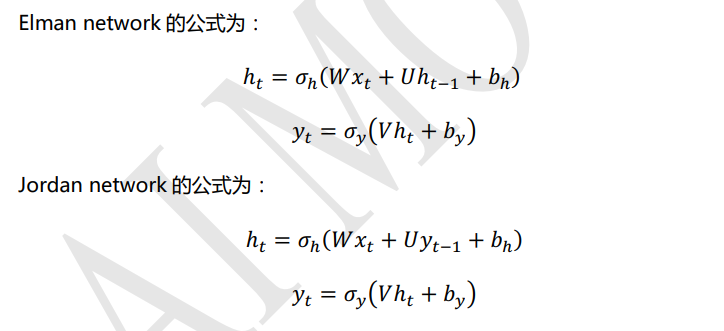
where xt x_{t}xtis the input signal at time t, ht h_thtis the output signal of the hidden layer at time t, yt y_tytis the output signal of the output layer at time t. W, U, V correspond to the weight matrix in Figure 9.5, and b is the bias value. σ h \sigma_hph和σ and \sigma_ypyis the activation function, and the activation function can be chosen by itself. Usually σ h \sigma_hphFor the tanh activation function , σ y \sigma_ypyIf you do binary classification tasks, you can choose sigmod, and you can choose softmax for multi-classification tasks.
As can be seen from the comparison of the formulas of Elman network and Jordan network above, the hidden layer ht h_{t} of Elman networkhtWhat is received is the hidden layer ht − 1 h_{t-1} of the previous momentht−1The signal; and the hidden layer ht of Jordan network h_{t}htWhat is received is the output layer yt − 1 y_{t-1} at the previous momentyt−1signal of. Generally, the form of Elman network will be more commonly used.
Question 1: Why choose tanh as the activation function of the hidden layer?
Reference link: Detailed explanation of the smallest white RNN in history

In the process of updating the gradient, the derivative of the hidden layer activation function needs to be multiplied when the final calculation of the gradient is derived from the formula . The derivative of the sigmoid function is between [0,0.25], and the import of the tanh function is [ 0,1], although both of them have the problem of gradient disappearance, but tanh performs better than the sigmoid function, and the gradient disappears not so fast.
Thinking question 2: So why not use the ReLU activation function in RNN to completely solve the problem of gradient disappearance?
In fact, using the ReLU function in RNN can indeed solve the problem of gradient disappearance, but it will introduce a new problem of gradient explosion.
The derivative of the activation function needs to be multiplied by a Ws each time. As long as the value of Ws is greater than 1, the gradient explosion will occur after multiple multiplications. But the problem of gradient explosion here is not unsolvable, and the problem of gradient explosion can be solved by setting an appropriate threshold.
But at present, when everyone solves the problem of gradient disappearance, they generally choose to use LSTM, a variant structure of RNN, to solve the problem of gradient disappearance, and the activation function of LSTM is tanh, which will not introduce the new problem of gradient explosion, so Maybe there is no need to worry too much about whether to choose ReLU or tanh on the basic RNN, because everyone actually uses LSTM, and only needs to understand the idea of RNN, so I chose a compromise ratio The effect of sigmoid is good, and tanh, which does not introduce a new gradient explosion problem, is used as an activation function.
Various types of tasks for RNNs
one to one
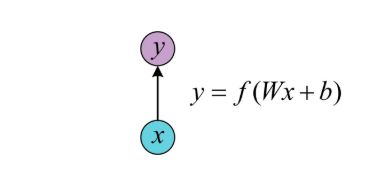
The input is independent data, and the output is also independent data. Basically, it cannot be regarded as RNN, and it is no different from a fully connected neural network.
one to n
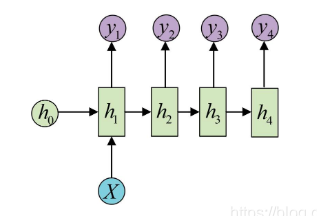
The input is an independent data, and a sequence of data needs to be output. Common task types are:
- Generate text descriptions based on images
- Generate a paragraph of language and text description based on the category
n to n
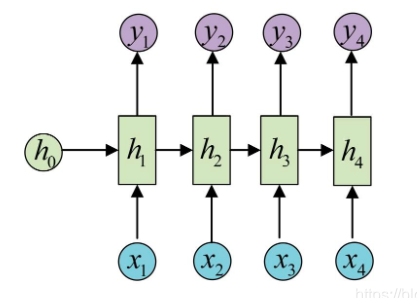
The most classic RNN task, the input and output are sequences of equal length, the common tasks are:
- Calculate the classification label for each frame in the video
- Enter a sentence and judge the part of speech of each word in a sentence
n to one
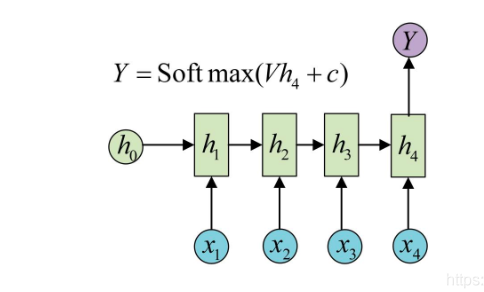
Input a sequence, and finally output a probability, which is usually used to deal with sequence classification problems. Common tasks:
- Text Sentiment Analysis
- Text Categorization
n to m
The full name of Seq2Seq is Sequence to Sequence, which is a sequence to sequence model. seq2seq is also a many-to-many architecture
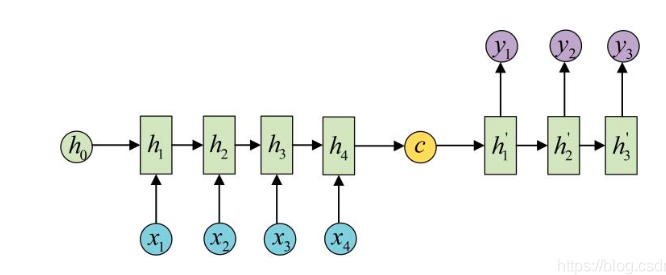
The task of unequal length between the input sequence and the output sequence is the Encoder-Decoder structure, which has many usages:
- Machine translation: the most classic application of Encoder-Decoder, in fact, this structure was first proposed in the field of machine translation
- Text summary: the input is a text sequence, and the output is a summary sequence of this text sequence
- Reading comprehension: Encode the input article and question separately, and then decode it to get the answer to the question
- Speech recognition: the input is a sequence of speech signals, and the output is a sequence of words
Based on the Encoder-Decoder structure, the big killer transformer and Bert in NLP have been improved.
Reference link: Seq2seq and attention
Xiaobai explain seq2seq, attention, self-attention in detail