Author Homepage: Programming Compass
About the author: High-quality creator in the Java field, CSDN blog expert, invited author of Nuggets, many years of architect design experience, resident lecturer in Tencent Classroom
Main content: Java project, graduation design, resume template, learning materials, interview question bank, technical mutual assistance
Favorites, likes, don't get lost, it's good to follow the author
Get the source code at the end of the article
Item number: BS-XX-206
1. Environmental introduction
Locale: Java: jdk1.8
Database: Mysql: mysql5.7
Application server: Tomcat: tomcat8.5.31
Development tools: IDEA or eclipse
Development technology: JSP
2. Project introduction
Since the concept of big data was proposed, Internet data has become the object of data mining for more and more scientific research institutes. Online news data accounts for half of the Internet data. Compared with traditional media, it has the characteristics of rapid dissemination, short exposure time, and containing netizens' opinions, and its value is also increasing.
Use related web crawler technology and algorithms to realize automatic collection and structured storage of network media news data, and use Chinese word segmentation algorithm and Chinese similarity analysis algorithm to conduct some induction and sort out relevant news development trends, reflecting the mining of network news data value.
If a commercial company can select the news related to itself for analysis, it can get many unexpected gains, such as whether there are black hands behind the scenes deliberately discrediting, and the situation of competitors. It is of great value to today's enterprises to grasp the negative effects of online news related to it in the first place, use public relations power, correct mistakes in time, and quell negative news.
If you want to monitor the development and changes of network news in real time, you must use relevant tools. The manual speed is too slow. At this time, web crawlers came into being. The crawler needs to regularly crawl relevant network media pages, obtain and analyze the source code of the page, and extract the text. This involves the filtering algorithm, or the analysis algorithm of the web page structure, and also involves how to deal with the website anti-crawler strategy, which is mainly divided into the following parts:
Crawler technology: what language and framework are used to write crawlers, and what kind of popular java crawler frameworks are there at this stage? How to get structured and compact network news data from loose and unstructured network news.
Webpage processing technology: how to deal with js, what strategy should be used in the face of ajax loaded website, and how to accurately extract the text of the article from the html statement, and at the same time beware of the anti-crawler technology of the website. May need to bring cookies etc.
Chinese word segmentation technology: the extracted text can be segmented at noon with a relatively high accuracy rate, so that word segmentation can be used later to determine the similarity of articles. There are endless new words on the Internet, so it is very important whether word segmentation can accurately identify unknown new words. At present, word segmentation tools are prepared to use IK word segmentation using Lucene as the core, or domestic Ansj Chinese word segmentation and other word segmentation tools.
Chinese corpus similarity matching: With the relevant theoretical research in recent years, some semi-mature solutions have been introduced, such as methods for calculating the cosine theorem, methods for analyzing semantics and word order, and methods for calculating edit distance. Firstly, the algorithm for calculating the similarity of the edit distance corpus is introduced. Specifically, after any two Chinese-character sentences are given, the minimum number required in the process of converting any one of the two Chinese-character sentences into another Chinese-character sentence is calculated. number of edits. The algorithm of the minimum edit distance was first proposed by the Russian scientist Levenshtein, so it is also called Levenshtein Dsitance. Of course, the algorithm cannot achieve 100% similarity matching at present, and the solution to this problem is regarded as a major problem in the world.
Similar news trend display: Use jfreechart or Baidu's echarts to display the analysis results in a graph.
According to the content analysis of the system requirements calls, the system functions are divided into the following five modules:
Data acquisition module:
The data collection module is responsible for data collection, that is, the regular collection of hot network news data, and the preliminary splitting and processing of data.
(1) Chinese word segmentation module:
The Chinese word segmentation module can perform more accurate Chinese word segmentation on the hot network news data collected by the data collection module.
(2) Chinese similarity judgment module:
The Chinese similarity determination module conducts similarity analysis of network hot news by combining the hot network news data collected by the data collection module with the word segmentation results of the Chinese word segmentation module, and can merge similar news data.
(3) Data structured storage module:
The data structured storage module runs through other modules. In the data collection module, it is responsible for storing the collected and split hot network news data; in the Chinese word segmentation module, it is responsible for reading out the network news data that needs word segmentation processing from the database; In the Chinese similarity judgment module, it is responsible for storing similar news obtained from the analysis; in the data visualization display module, it is responsible for reading similar hot news data from the database, which involves a lot of processing of database resources.
(4) Data visualization display module:
The data visualization display module is responsible for displaying the data judged as similar news by the Chinese similarity judgment module in a visual form, and the display form can be customized.
Three, system display
3.3.1 Module Structure Diagram
Reptile system software structure diagram:
Input the URL of the webpage to the crawler system, the crawler opens the webpage, parses and extracts the text of the webpage, and then outputs the text of the webpage, as shown in Figure 3-1.

Figure 3-1 Structural diagram of crawler subsystem
Input the text of the webpage into the system, and the system starts word segmentation according to the thesaurus and related strategies, and finally outputs the word segmentation results in the form of data (in the form of phrases), as shown in Figure 3-2.

Figure 3-2 Structural diagram of word segmentation subsystem
First, the first step is to input data: the data collected by the web crawler system is used as the input of the similarity matching system, and then enters the processing process, which uses the improved cosine theorem for processing, and then the system returns the processed results, and finally the system The processed results are output and passed to the next subsystem for processing, as shown in Figure 3-3.
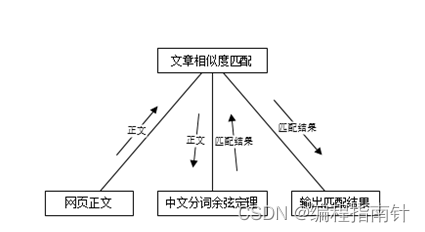
Figure 3-3 Structural diagram of article similarity matching system
The system is designed to be composed of three subsystems, respectively: the web crawler system is the data collection system, the news analysis system is the Chinese corpus similarity analysis system and the final result display system, as shown in Figure 3-4.

Figure 3-4 System Hierarchy Diagram
(1) Here first introduce the database connection pool used in the system, a database connection pool written by MF_DBCP itself, the UML class diagram is shown in Figure 3-5.

Figure 3-5 System class diagram
In the UML diagram of the DBCP connection pool, the database exception throwing class, the POJO class of the database configuration, the core class Pool of the database connection pool, and the proxy implement the close() method of Connection, setAutoCommit() and other methods, as well as the database connection pool. Monitor class, used to monitor the health status of the database and so on.
 (2) The core of the crawler is the Web class. Fenghuang.com News, Sohu News, and NetEase News respectively integrate the core Web class, and then implement their own parsing rules. The core Web class is responsible for some basic operations, such as opening the web page, obtaining the source code of the web page, and There are some regular expression extraction and analysis algorithms. In fact, the Web class also includes the role of the POJO class, which is also the carrier of the results generated by the crawler after crawling news, as shown in Figure 3-5.
(2) The core of the crawler is the Web class. Fenghuang.com News, Sohu News, and NetEase News respectively integrate the core Web class, and then implement their own parsing rules. The core Web class is responsible for some basic operations, such as opening the web page, obtaining the source code of the web page, and There are some regular expression extraction and analysis algorithms. In fact, the Web class also includes the role of the POJO class, which is also the carrier of the results generated by the crawler after crawling news, as shown in Figure 3-5.
Figure 3-5 Class diagram of crawler system
Fourth, the core design display
The system structure logically consists of four parts: the first part is the data acquisition module, which is responsible for data collection and text extraction of native web documents; the second part is the data collection solidification module, which collects the original web documents collected by the data Storage and solidification; the third part is responsible for the processing and analysis of webpage document data. After reading the original webpage document data from the database, Chinese word segmentation is performed, and then similarity analysis is performed based on the word segmentation results, and the analysis results are the same as similar news results. storage; the fourth layer is the data display module, which is responsible for drawing the analyzed and sorted data in the form of charts.
4.1.1 Data Acquisition Module
The data acquisition module (crawler system) acquisition tool uses the HttpClient framework, cooperates with regular expression analysis, and extracts web page content. HttpClient is a sub-project under Apache Jakarate Common. It is open source and free. The original purpose of HttpClient was for web testing. Later, its functions have been continuously improved and strengthened. In terms of functions, it can basically be a real browser, but it It is not a browser, but only implements some functions of the browser. HttpClient has been used in many projects. For example, Cactus and HTMLUnit, two other well-known open source projects on Apache Jakarta, both use HttpClient. Based on the standard and pure Java language, HttpClient implements Http1.0 and Http2.0, and implements all methods of the Http protocol (GET, POST, PUT, DELETE, HEAD, OPTIONS, TRACE) with an extensible object-oriented mechanism. And support Https protocol, establish transparent connection through Http proxy, use CONNECT method to connect through Http proxy tunnel Https, support NTLM2 Session, SNENPGO/Kerberos, Basic, Digest, NTLMv1, NTLMv2 and other authentication schemes, and comes with plug-in Customize the authentication scheme. HttpClient is designed with focus on scalability and customization, so HttpClient can support a variety of different configuration schemes. At the same time, HttpClient is more convenient to use in a multi-threaded environment. HttpClient defines a webpage connection manager, which can automatically manage various webpage connections. It can find abnormal connections and close them, which plays a good role in preventing memory leaks. effect. HttpClient can automatically process the Cookie in Set-Cookie, and can customize the Cookie policy in plug-in style. The output stream of Request can effectively read related content directly from the Socket server. In Http1.0 and Http1. In 1, use Keep-Alive to maintain a long-term (persistent) connection, and you can directly obtain the response code and headers sent by the server. In addition, HttpClient can set the connection timeout and experimentally support Http1.1 response cahing.
Using HttpClient GetMethod to crawl a webpage corresponding to a URL requires the following steps:
Generate an HttpClient object and set corresponding parameters.
Generate a GetMethod object and set the corresponding parameters.
Use the object generated by HttpClient to execute the Get method generated by GetMethod.
Handle the returned response status code.
If the response is normal, process the Http response content.
Release the connection.
After obtaining the response content, it is necessary to parse the Html DOM object. Here, jsoup is selected. Jsoup is a Java Html document parser that can directly parse a certain URL address, but here HttpClient is used instead of him to obtain Html DOM objects, because the function of opening and parsing URLs that comes with jsoup is a relatively basic function , far less rich than that provided by HttpClient. Here, this article uses other tools to replace Jsoup to obtain Html DOM objects, such as the HttpClient introduced above. After obtaining the web document data, the web document data can be passed in the form of strings Give Jsoup for Html parsing. In terms of parsing HTML documents, Jsoup comes with many very convenient methods and APIs. For example, you can directly manipulate HTML web page elements like jQuery. In addition, there are other methods for extracting the required content in HTML documents. Readers can do it by themselves Read the official usage documentation of Jsoup. The last point is also very important. Using Jsoup is completely free, including copying and cloning the code. You can modify the source code of Jsoup according to the different needs of the project. As a very popular Html document parser, Jsoup has the following advantages:
Jsoup can directly parse the URL of the web page to extract the required content, and can also directly extract the Html document string for parsing;
Jsoup is a selector that implements CSS, and can directly manipulate elements like jQuery;
Jsoup can not only handle the text content of Html documents conveniently, but also handle related elements of Html document elements, such as obtaining the attributes of Html tags, etc.;
In addition, there is a very important feature. At present, many websites use different background environments, such as Java, PHP, Python, Node.js, etc. as development tools, and there are various web development frameworks, so some mistakes are likely to occur. , such as the lack of closed parts of webpage tags, anyone who is familiar with Html knows that Html language is a language with high fault tolerance. For those who use Html documents to obtain web page information, this feature is very fatal and will have a great negative impact on the final analysis results. However, using Jsoup can completely avoid this problem. Jsoup has been designed with these problems in mind, and it is also fault-tolerant to the closure of Html tags, such as the following states:
1. There are unclosed html tags in the Html document (for example: <p>Chen Jinhao’s thesis<p>The thesis is difficult to write<p>It’s good to have the content</p> <p>AB123</p>)
2. Implicit tags in Html document data (for example: it can automatically wrap <td>table</td> into <table><tr><td>)
3. Can create a very reliable Html document structure (for example: html tags include head and body, only appropriate elements appear in the head)
The crawling objects of the crawler system selected Fenghuang News, NetEase News, and Sohu News respectively, because these news are open to the number of hits, and these three major media are very large and extensive in terms of influence and coverage. , is very suitable as a crawling object, and there is no complicated Ajax to deal with during the crawling process, and the access data of these news are updated every day.
The crawler program needs to run regularly on the corresponding server in a cyclical manner, crawl the news content of the above websites regularly every day, and store them in the database. The database uses Mysql, because Mysql is relatively lightweight, and there is a free academic research version, and it is relatively suitable for the current scene. The Mysql database engine uses MyIASM. Logically speaking, MyIASM is a relatively old engine, but the performance of the MyIASM storage engine is better than that of INNODB in terms of curvature. Although it does not support transactions, crawler storage does not involve the use of transactions for the time being. MyIASM's excellent insertion and query speed makes the crawler data access very fast and fast, so MyIASM is selected as the storage engine of Mysql here.
The crawler of the data acquisition system uses multi-threaded concurrent crawling when crawling the website, so the multi-threaded crawler will perform many concurrent operations on the database. When performing database operations, the first step is to establish a database connection. In a threaded environment, these operations will be performed very frequently, but these operations consume a lot of network and memory space. These operations will have a great negative impact on system resources and system operating efficiency, so a database connection pool must be used. There are many open source and excellent database connection pools on the Internet, such as Apache’s open source dbcp. Usually, when tomcat uses DateSource to configure the connection pool, it uses the built-in dbcp connection pool of tomcat. In addition, there is also the c3p0 database connection pool, which is also a very good connection pool. , Hibernate, one of the three major SSH frameworks, uses c3p0 as its built-in connection pool. Its excellent performance is evident, but these connection pools are relatively heavyweight, so I wrote a relatively lightweight one here. The connection pool MF_DBCP, the following will introduce the related content of the custom connection pool.
The connection pool of relational database has several basic principles:
1. The purpose of pooling database connections is to realize the reuse of resources. Using database connection pools can easily reuse database connections. In the process of reusing resources, it can also be supplemented by related management strategies, so that the entire connection pool It has the characteristics of spontaneity, intelligence, low energy consumption, and high efficiency, and is easy to deal with operations that consume computer resources such as high concurrency.
2. The most important thing in the design process of the database connection pool is to accurately grasp the principle of transaction atomicity of relational databases, so as to ensure that transactions will not be interfered by other database operations at any time, that is, transactions will occupy a single database connection. Conversely, when no transaction is started or related database operations do not involve transactions, multiple database requests can share one database connection, and the database uses a queue mode to process multiple requests of the same database connection. There will be no interruptions, while the processing speed is guaranteed to be efficient.
3. The strategy maintains the connection pool to ensure the robustness of the connection pool, and establishes an appropriate strategy to create a database connection pool monitor to monitor the situation of the database. Here it can be summed up in one sentence: at any time, the connection pool must be able to To be able to withstand the pressure from business calls, and to ensure the minimum load on the database system at all times, an optimized processing link has been established between the business layer and the database system.
ConfigurationException is used to throw an exception configured by the user, and DataSourceException is used to throw an exception during connection pool operation, see the code for details. The internal class Config is similar to the JavaBean class, saving the most original data read from the configuration file. Configuraiton inherits from Config and provides a method for constructing a connection pool. As an added note here, the specific functions of Configuration should be abstracted into a functional interface, so that it will be clearer when expanding the functions of Configuration. The Pool class is the core of the connection pool. It provides the getInstance() method (singleton mode) to obtain a unique connection pool. concs is a single connection pool container queue (described below), and the busy field indicates that the current connection pool is busy. greater than 0), the free field indicates that the current connection pool is idle (load is equal to 0), and the sum field indicates the size of the current connection pool (busy+free). In the ConnectionContainer class, when the connection does not open a transaction, multiple database requests can share the same connection. The load field is used as a load indicator to record the number of times the connection is currently used. DataSource provides the getInstance() method to obtain the only user-oriented database connection pool (singleton mode). The PoolSnapshot class creates a snapshot of the connections currently in use by the pool to determine whether the pool needs to shrink as part of the database's monitor strategy. The MonitorControler interface can expand the functions of the monitor and is implemented by two monitoring classes ConnectionStatusMonitor and ConnectionNumMonitor.
After the monitor is initialized, two threads are started:
1. No. thread runs periodically according to the status_checktime field in the configuration file to scan for bad links in the connection pool and fix them
2. No. thread periodically creates a snapshot of the connection pool usage status according to the num_checktime field in the configuration file. When there are enough three states, determine how many connections need to be saved in the database connection pool according to the curve drawn at three points, and ensure the number of connections Not less than the minimum number of connections.
The following uses + to indicate that the number of connections in the current snapshot is greater than that of the previous snapshot, and – indicates that the number of connections in the current snapshot is smaller than that of the previous snapshot:
+++ The monitor does nothing because the number of connections is steadily increasing;
-+- The average number of connections of the last two connection snapshots is kept at the end of the monitor, and the remaining redundant connections are recycled;
— The monitor retains the average connection number of three snapshots as the current connection, and the remaining redundant connections are recycled;
The related APIs of custom database connection pool are as follows:
The addNew() method adds a new connection to the connection pool;
The addLast() method provides a "load balancing" strategy for connections that do not open transactions and can be shared (when a connection is used once, put it at the end of the queue, imagine that the queue can be circulated);
The deleteFirst() method can be called cyclically to clear the connection pool queue;
The delete() method provides a method to remove a connection from the connection pool;
The getFirst() method provides access to the connection with the lightest load, which is the head of the queue;
The getLoad() method provides a method to obtain the load size of the specified connection;
The getConnectionContainer() method provides access to the connection container where a connection is located (thus operating the connection pool container queue in the connection pool);
The remove() method provides to remove a connection that has opened a transaction from the connection pool, and the deleteLater() method provides a connection that can be cleared (load equal to 0) in the database;
The getMinLoadConnection() method provides access to the connection with the lowest load in the connection pool in order to create a dedicated transaction connection;
The getConnectionContainers() method provides the outside world with a method to obtain the database connection pool queue;
The isFullFree() method judges whether the current connection pool is completely idle (close the connection pool judgment);
The size() method provides access to the number of remaining connections in the connection pool after removing transaction connections;
The createConnection() method provides a method for the connection pool to create a new connection;
The destroyConnection() method specifies to close a connection;
The repairPool() method provides a method to repair bad connections in the connection pool and replace them with new available connections; the releasePool() method provides a method to shrink the size of the connection pool to ensure that the number of reserved connections is the most appropriate;
The revokeConnection() method provides a method to recycle the connection and add it to the connection pool queue again;
getConnection() is called when the user needs to connect;
getPoolStatus() returns the usage of the current connection pool;
close() closes the database connection pool;
4.1.2 Chinese word segmentation module
First, briefly introduce the concept of Chinese word segmentation. Chinese word segmentation is the process of correctly dividing the original Chinese sentence or longer Chinese corpus into Chinese words one by one through relevant algorithms.
Speaking of Chinese word segmentation, let’s first introduce English word segmentation. Computers were invented by Europeans and Americans, so they conducted research on English word segmentation very early. This article introduces it from simple to complex. English word segmentation is very simple. For articles, there is a space between English words and words. Using this feature, the program can quickly segment English articles into English words. Looking back at Chinese at this time, I found that the problem came. Except for the punctuation marks in the sentence, basically all Chinese is continuous, and there is no very obvious segmentation feature. At this time, the set of tools originally used for word segmentation in English has no effect on the word segmentation of Chinese corpus. Of course, it is not required to learn English in Chinese writing. Spaces are used as intervals between words, so It is necessary to study the Chinese word segmentation strategy specifically.
At this time, let's go back to the idea of English word segmentation. I have learned English phrases a lot since I was a child. Have you discovered anything? The word segmentation between English phrases and phrases cannot simply be judged by spaces. However, the combination and rules between English words are much stronger than Chinese, but Chinese has the largest user group in the world, so it is very necessary to study Chinese word segmentation technology. How to do Chinese word segmentation? Therefore, we must first study the grammar of Chinese.
Under the statement here, the Chinese word segmentation does not currently involve the word segmentation of ancient Chinese. The specific reason is that the word segmentation of ancient Chinese is extremely difficult and basically irregular.
After years of research and exploration by a large number of computer enthusiasts and academic workers, some semi-mature Chinese word segmentation algorithms have been gradually introduced. The road to Chinese word segmentation is difficult, and everyone needs to work hard. Here, this article first introduces several common Chinese word segmentation algorithms:
(1) Chinese word segmentation method for character matching
The Chinese word segmentation method for character matching is based on the word segmentation algorithm based on the corpus dictionary. The accuracy of the word segmentation results depends on whether there is a good word segmentation dictionary. The specific content of the algorithm is to first load the word segmentation dictionary into memory in the form of a certain data structure , generally Hash hash storage method, because this method has an extremely fast search speed, and then match the Chinese corpus strings to be segmented according to the words in the word segmentation dictionary. The Chinese corpus string is split into several non-repetitive Chinese words, that is, the matching is completed.
When splitting the Chinese corpus to be segmented, a variety of splitting methods should be combined, because different splitting methods may bring completely different word segmentation results. In the face of a random standard Chinese corpus, if it is of sufficient length, clear enough, and free from ambiguity, the resulting word segmentation results must be consistent from different segmentation methods.
If computer word segmentation is used, there must be many strange word segmentation results, and statistical methods can be used to improve the correct hit rate of the final word segmentation result set. The specific method is to customize multiple algorithms for splitting the Chinese corpus, and then calculate their final word segmentation results respectively, and then count the final result set. Which part of the word segmentation results appears the most times in the final word segmentation result set, then take that The word segmentation is used as the final word segmentation result.
The word segmentation method finally adopted in this paper is an improved version of this word segmentation method, which combines some features of IK word segmentation and Lucene. The Chinese word segmentation algorithm for character matching is very dependent on a suitable word segmentation dictionary, so how to get this word segmentation dictionary? The most stupid way is to manually review news materials, or download Chinese dictionaries, and extract the words in them as word segmentation dictionaries. Secondly, word segmentation dictionaries need to continue to evolve. The endless emergence of new words on the Internet poses a huge challenge to the word segmentation results. Here we will not discuss the self-learning of the program and the automatic expansion algorithm of the dictionary. The commonly used Chinese word segmentation algorithms are as follows:
(2) Chinese word segmentation method for semantic analysis and understanding
The word segmentation method of this Chinese corpus must first analyze the semantics, grammar, syntax, etc. of Chinese, and the goal of obtaining these laws is to use these laws to allow computers to understand the meaning of Chinese sentences, but this method seems perfect. But there is very far. First of all, it is very complicated to thoroughly summarize these laws, because of the complexity of the entire Chinese grammatical system and the flexible combination of Chinese. Different combinations have different meanings, such as "I still owe him money. ", if you pronounce "also" as "hai", the whole sentence means "I still owe him money", but if you pronounce "return" as "huai", then the meaning of the whole sentence is It becomes "I paid back the money, and I paid him back all the money owed to him", and there will definitely be problems in the identification of this situation. Furthermore, if these laws are obtained, it is also very difficult to realize these laws in a programming way. The Chinese word segmentation method for semantic analysis and understanding is closely related to the development of artificial intelligence. If the word segmentation of Chinese corpus based on semantic analysis can be realized, then artificial intelligence can also achieve considerable development.
Because the development cycle of this algorithm is long and difficult, it is still in the conceptual stage in the world. Even if the semantic and grammatical understanding of Chinese is realized, there are other languages in the world: English, Russian, French, Arabic, etc., and the development process is bound to be difficult. This article mentions this method here only as a way of thinking, and there is currently no way to implement it.
(3) Statistical Chinese word segmentation method
If we study the rules of words from the perspective of Chinese words, we can quickly get a conclusion that the frequency of two Chinese characters that form a word appear together in sequence is very high. This feature can be used to determine whether any adjacent Chinese characters form a word, but there is obviously a problem, how high is the frequency to prove that these characters form a word? From a mathematical point of view, this is not a problem that can be solved by a single coefficient, and it is definitely not a single functional relationship, because there are too many variables, and it is possible that different Chinese characters themselves can reach the threshold for judging that it can be combined with a certain Chinese character to form a word. Different, such as some uncommon words, this article presents an example in this section: the word "good", it can form "good person", "beautiful", "just right", "just right", "good luck", "curious" ", "He Hao", "Friendly", "Say hello", "Pleasure"... and other words, there are as many as 7,500 results found on Baidu; take another word "Yu", use "Yu" group There are only about 120 words, such as "controlling", "controlling the wind", etc. Obviously, the two words "good" and "controlling" cannot be judged by the same criteria, and the frequency of their occurrence is too different, so it cannot be A set of judging schemes is shared to judge whether they form words or not.
Secondly, there is another problem. There are some special Chinese characters, and they will also have a non-negligible interference effect on the entire Chinese word segmentation results, such as "le", "de", and "zhu". These words can be combined into words, For example, "know", "purpose", "start", etc., but their more forms in the whole Chinese corpus are similar to this form: "go", "tired", "drop", "good The", "your", "his", "walking", "running", "got" and other forms, such forms are obviously not words, and these words often appear as concluding words, which may affect the entire word frequency-based The advanced Chinese word segmentation algorithm has a huge interference effect, and in the Chinese corpus, these words listed are only the tip of the iceberg. So this method is not enough to rely on word frequency alone.
However, so far, artificial intelligence is becoming more and more popular, and its development has become rapid. It has to be said that this method is forward-looking. If a large amount of Chinese corpus training sets can be given in advance, supplemented by artificial intelligence Error correction and correction operations make this statistical Chinese word segmentation algorithm more and more accurate. I believe this method will replace other word segmentation algorithms in the near future. In dealing with natural language, it is the right way to understand semantics and grammar. By establishing relevant grammatical models and continuously conducting statistical word segmentation training, the later algorithm will definitely have very good word segmentation results. However, the research in this paper only borrows Chinese word segmentation tools, and will not conduct too in-depth discussions on this aspect. By the way, the corpus used as a training set can be trained by using a crawler system similar to this article to collect the latest news information from the Internet every day for training, and manual error correction, because there is no Chinese corpus training set that is more effective than news, so "New words on the Internet" can also be supplemented and learned in a timely manner. The number of manual corrections required in the later stage will be less and less, and the word segmentation results will become more and more accurate.
This article uses IK Analyzer as a tool for Chinese word segmentation. IK Analyzer is a completely free and open source Chinese word segmentation tool. It is a very excellent and fast Chinese word segmentation toolkit developed based on Java. There is also a relatively well-known Chinese word segmentation tool Ansj in China, which claims to be able to recognize names and place names very well, and its processing speed completely surpasses IK word segmentation. However, since IK word segmentation is based on Lucene, I have been studying Lucene recently. The word segmentation results are also quite satisfactory.
The version of IK Analyzer used in this system is 2012u6, and the author Lin Liangyi is a Java program development engineer himself. You can see a lot of Lucene shadows in IK Analyzer. For example, the core of IK word segmentation is based on Lucene, and a large number of import packages can also be seen from Apache Lucene. Now I am free to study the algorithm and principle of IK word segmentation, hoping to add my own contribution to the IK word segmentation that has not been updated for a long time. The structure diagram of IK word segmentation system is shown in Figure 4-1.

Figure 4-1 Design structure diagram of IK word segmentation
4.1.3 Similarity matching module
After using the Chinese word segmentation tool to perform Chinese word segmentation on the data collected by the crawler system, it is necessary to analyze the similarity of the articles, and then integrate the data of similar articles together to lay the foundation for visually displaying the changing trend of the same news in the future. There are many algorithms for calculating the similarity of articles. There are mainly two types, one is the law of cosines, and the other is the method of calculating the Jaccard distance.
1. Cosine law similarity calculation method
How can the law of cosines be applied to calculate the similarity of articles? First think about the concept of the law of cosines. If two articles can be converted into two vectors in mathematics, then the law of cosines can be used to calculate the angle between the two vectors. Specifically, how can the article be converted into a vector in mathematics? Chinese word segmentation is used here, and then the Chinese corpus with analysis can be segmented in Chinese, and the respective word segmentation result sets A, B can be saved. After the word segmentation is finished, set another set S, let S = A ∪ B, then calculate the word frequency of the words in the two sets A and B respectively in the original expectation, and then establish the mapping from A, B to S, if there are If there is no word in A or B, then remember that the word frequency of the word is 0, then you can get two vectors with the same dimension, so that you can use the law of cosines to calculate the similarity.
The first step is to segment the Chinese corpus.
Sentence A: I /like/watch/TV, don't /like/watch/movies.
Sentence B: I /don't/like/watch/TV, and I /don't/like/watch/movies.
The second step is to list the collection of all Chinese words.
I, like, watch, TV, movies, no, also.
The third step is to calculate the word frequency of each word in the set.
Sentence A: I am 1, like 2, watch 2, TV 1, movie 1, not 1, and also 0.
Sentence B: I 1, like 2, watch 2, TV 1, movie 1, not 2, also 1.
The fourth step is to write the word frequency vector of each sentence.
Sentence A: [1, 2, 2, 1, 1, 1, 0].
Sentence B: [1, 2, 2, 1, 1, 2, 1].
With the word frequency vector, the similarity calculation problem of Chinese articles is simplified, and it becomes how to calculate the degree of separation and separation of these two word frequency vectors. First of all, these two word frequency vectors can be imagined as two arbitrary line segments existing in the space. These two line segments must be able to form an angle similar to the figure below, and then calculate the cosine value of the angle.
Let’s discuss the simplest dimension here, that is, two-dimensional space. The a and b in the figure below are two letters representing two different vectors. It is necessary to calculate the cosine value COSθ of their angle, as shown in Figure 4-2 .

Figure 4-2 Two vectors form an angle
The angle formed by the vectors a and b is shown in Figure 4-3.

Figure 4-3 Angle formed by vector a, b
The following formula can be used to calculate the cosine value of the included angle θ, and the calculation formula is shown in Figure 4-4.

Figure 4-4 Calculate the cosine value formula of two vectors ab
What about multidimensional vectors? How to calculate the cosine of the angle between a multidimensional vector in space? Through mathematical derivation, the following multidimensional vector cosine calculation formula can be used as shown in Figure 4-5.

Figure 4-5 Calculation formula of cosine value of multidimensional vector
The cosine value of the word frequency vectors of two Chinese phrases can be used as a measure of the overall similarity of the two Chinese corpora, because mathematically speaking, when the cosine values of the two vectors are closer to or completely equal to 0, it indicates that the angle between the two vectors is The two directions are completely perpendicular. From the perspective of Chinese grammar, to explain the vector verticality, the word segmentation results of the two corpora are completely different. This shows that the content of the two articles is completely irrelevant. Conversely, if the cosine of the angle between the two vectors is close to or completely equal to 1, it means that the two vectors can be regarded as almost the same vector, which is explained from the perspective of Chinese grammar, that is, the word segmentation of two Chinese corpora The results are largely consistent, with a high degree of confidence that the content of the two articles is completely similar.
As a result, an algorithm for "finding similar articles" is obtained:
(1) To use the Chinese word segmentation algorithm, you first need to find out the important keywords of these two articles with analysis.
(2) Take out all the keywords from each article, merge them into a set, and then calculate the word frequency of the two articles relative to the keyword set, thus generating two word frequencies of the two articles to be analyzed vector.
(3) Finally, calculate the cosine value of the two word frequency vectors. The closer the cosine value is to 1, the more similar the articles are.
"Cosine similarity" is a very useful algorithm. Anyone who wants to know the similarity between any two vectors can use the law of cosines.
4.1.4 Data display module
Algorithms that match similar articles through the similarity matching algorithm are stored in the same data record and stored in the database, and then the similar data is read out and displayed in a visual form. The steps are as follows:
(1) Convert the POJO object to JSON:
JSON (JavaScript Object Notation) is a very lightweight data exchange format similar to but beyond Extensible Markup Language. JSON is based on a subset of ECMAScript. JSON uses a writing format that is completely independent of any programming language, but also uses some grammatical conventions that are very similar to the C language family (including C, C++, C#, Java, JavaScript, Perl, Python, etc.).
Once JSON was launched, until now, there is a tendency to completely replace XML in the choice of data exchange carrier. A financial project I recently wrote in the company is a financial project for real-time bond quotes written for Caixin. In the project, the background data is transmitted to the front desk using Servlet, and the Servlet is the data object obtained from the Service layer (generally It is List, Map, or other POJO objects), which is converted into a JSON string by fastjson, and finally output on the Servlet. Then the front-end js uses ajax asynchronous loading to call the Servlet, which can easily convert the obtained JSON string into related objects.
In addition, a large number of tests have shown that the amount of data information that can be loaded in JSON with the same number of bytes and the same size is much larger than that of XML, which shows that JSON has better compression and higher load efficiency. More and more website data interactions, as well as enterprise-level information interactions, and the classic CS model have gradually switched to JSON as the carrier of data transmission.
From the perspective of the JavaScript language layer, JSON is like a combination of array types and object types in JavaScript, which is somewhat similar to the syntax definition mode of structure strut in C language. Obviously, strut can combine different data structures , adding a variety of data nesting, can represent any information format in the world, JSON is very similar to this structure, because JSON is "omnipotent" as an efficient data carrier , in recent years, the development of JSON is rapid and rapid. The following is a brief introduction to objects and arrays in JavaScript:
object:
JSON objects are expressed in js as content enclosed by "{}", and its data structure is a key-value pair structure of {key: value, key: value,...}, which is used in most object-oriented programming In the language, the key is the name of the object property, and the value is the value of the property of the object. In C language, Java, Python and other languages, the specific value of value can be obtained through Object.key.
array:
The array in js is the content enclosed by brackets "[]" symbols. The data structure of the js array is like ["this", "a", "test",...], and the index of the array can be used to obtain the data The value of the corresponding position, the data type of the value includes a variety of data types: object, string, number, array, etc. Experiments have proved that the two data structures of object and array can be combined into various data structures of arbitrary complexity.
Nowadays, there are many tools that can convert POJO objects to JSON, such as Google's Gson toolkit, such as the open source JSON conversion tool fastjson contributed by Ali, and Alibaba's fastjson is used in this article. Fastjson provides JSON-related functions including "serialization" and "deserialization" of JSON data. Its advantages are: it claims to be the fastest in parsing and de-parsing JSON data. Tests show that fastjson has extremely fast Performance, beyond any other Java Json parser, including the self-proclaimed fastest JackJson. FastJson is powerful and fully supports common data patterns and types such as Date, Enum, Java Bean, Set, Map, etc., and is native and can run in all places where Java can run. Java objects are converted to JSON format, generally in the following situations:
The principle of converting ordinary single-node objects in Java to JSON:
Use the get() method of the object to get the value of the attribute of the object, that is, the value of the JSON data, and then use the function name of the get() method to get the specific member variable of get, so the key of the JSON data can be obtained in this way , and then through the splicing and combination of composite JSON syntax, the object is successfully converted into JSON. But what if the object doesn't provide a get() method for the response? Then it is necessary to use Java's reflection mechanism to take out the fields of the object to be converted into JSON, and then determine which fields are necessary, and discard the "garbage data" fields, and finally combine the fields into JSON. When combined into JSON, its field name exists as a key of String type, and its attribute value exists as a key of the corresponding data type, as shown in Figure 4-6.

Figure 4-6 Schematic diagram of object conversion to JSON
The principle of converting ordinary single-node arrays in Java to JSON:
The conversion of ordinary Java single-node arrays to JSON can be extended from single-node conversion to JSON, as shown in Figure 4-7.

Figure 4-7 Principle of converting an object array to JSON
The principle of converting Java composite objects to JSON:
The conversion of Java conforming objects to JSON is actually an extension of the principle of converting Java ordinary single-node objects to JSON. After obtaining the field name, when obtaining the attribute corresponding to the field, it is necessary to determine the specific data type of the attribute. If the specific data of the attribute If the type is one of the basic data types, it must be represented by the JSON representation method corresponding to the data type (for example, whether there are quotation marks or not is the difference between a string variable and other variables), as shown in Figure 4-8 shown.

Figure 4-8 Principle of converting composite objects to JSON
(2) Display Json data in a visual form
The open charting class library JfreeChart is used to display similar news data. The JfreeChart tool is written in pure Java language and is completely designed for the use of applications, applets, servlets and JSP. JFreeChart can generate charts such as scatter plots, bar charts, pie charts, Gantt charts, time series, etc., and can also generate PNG and JPEG formats for output, and can also be associated with tools such as PDF and EXCEL.
So far, JFreeChart is a very good statistical graphics solution in Java. JFreeChart can basically meet the various needs of current Java in statistical graphics. The outstanding features of JFreeChart include the following:
Consistent and clear API, and support for multiple chart types.
The design is very flexible and very easy to expand for various applications.
Supports a variety of output types, including Swing components, image files (PNG, JPEG), vector graphics files (PDF, EPS, SVG).
JFreeChart is completely "Open Source", or more specifically, Free Software. It follows the GNU protocol.
The advantages of JfreeChart are as follows:
Stable, lightweight and very powerful.
It is free and open source, but development manuals and examples cost money to purchase.
Its API is very easy to learn, and the entire tool is easy to use.
The generated charts run very smoothly.
5. Project result test
Software testing is the last and most important part of a series of processes and activities in software system development. It is a solution to ensure the logical rigor, rigor, and high availability of software. Through the verification of the logical branch of the software, it is determined whether the software can meet the requirements in the requirement analysis, and to the greatest extent, it can be guaranteed that the software will not bring other BUG. Only through software testing, the final product of the entire software engineering can be delivered to users.
5.1 White box testing
White-box testing is a test based on software logical structure design. During the entire testing process, the test participants are fully familiar with the logical branches of the entire system. The box of white-box testing refers to the software system under test. White-box means that the program structure and logic code are known, and the internal logical structure and operating logic of the box are very clear. The "white box" method fully understands the internal logical structure of the program and conducts relevant tests on all logical paths. "White box testing" will strive to be able to test all possible logical paths in the software system. When using the white-box testing method, it is necessary to draw all the logical sequence structure and design of the software, and then design appropriate and comprehensive test cases respectively, and finally complete the white-box testing.
5.1.1 Test results of crawler system
Because the logic design of the crawler system is relatively simple and does not involve the basic path method, because the entire positive sequence only needs to be run regularly, unlike other software systems, which have a deep foundation of user needs and require the cooperation of relevant personnel. . The crawler system developed this time is fully automatic, so the Lily test results are consistent with the black box test results.
The figure below is a screenshot of the Lily test results of the crawler system. The test method is to run the crawler regularly. The items in the figure below are part of the results crawled by the crawler this time. The crawled results are shown in Figure 5-1.

Figure 5-1 Crawler crawling results
5.1.2 Chinese word segmentation system test results
The Chinese word segmentation system test is also relatively simple, without complex business logic, the results are basically in the order of threads, and the execution path is unique. The following figure shows the white box test results of the Chinese word segmentation system. The first is a screenshot of the test corpus, as shown in Figure 5-2 shown.

Figure 5-2 Original Chinese word segmentation
The final word segmentation results are as follows. At present, it is very difficult to improve the word segmentation results. It is necessary to increase the accuracy of the thesaurus. The white box test results are shown in Figure 5-3:

Figure 5-3 Chinese word segmentation results
5.1.3 Chinese article similarity matching system test results
The similarity calculation method of Chinese articles uses the cosine theorem to calculate the cosine value of the angle between the word frequency vectors of the Chinese words corresponding to the two articles. After a large number of experiments, it is found that the accuracy rate is still very high. The test results are shown in Figure 5 -4 shown.

Figure 5-4 Cosine law similarity matching
It can be seen that the news "National Special Plan Causes Parents of Jiangsu and Hubei to Concern about the Ministry of Education's Response" and "Sending Students to the Central and Western Regions Reduced Entrance Examination by Tens of Thousands? Hubei and Jiangsu Respond Overnight" are both related to the college entrance examination, a perfect match When we come together, we can’t rule out some extreme situations that lead to incorrect matching results. This will continue to be studied to improve the accuracy rate.
5.1.4 Similar News Trend Display System Test Results
The display of similar news uses JfreeChart as the test object of the white box test. The test results are shown in the figure below, which accurately shows the attention trend of each piece of news, as shown in Figure 5-5.

Figure 5-5 JfreeChart test chart
5.2 Black box testing
Black-box testing is just the opposite of white-box testing. As you can see from the name, one black and one white, white-box testers are familiar with the contents of the box, while black-box testers are completely ignorant of the contents of the box. Black-box testing is mainly for the function realization of the program, such as checking whether the program has a certain function, without caring about the logic design of the program at all. That is to say, the whole black-box test focuses on the functional integrity of the software system, without considering issues such as bugs in program logic.
5.2.1 Test results of crawler system
As mentioned above, the logic of this crawler system is relatively simple, and the white box test results are consistent with the black box test results, as shown in Figure 5-6.
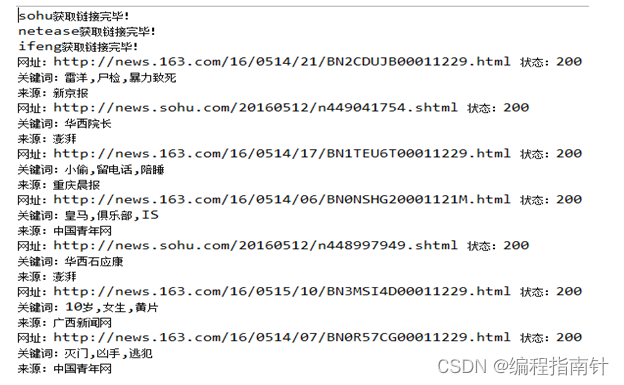
Figure 5-6 Black box test of crawler system
5.2.2 Chinese article similarity matching system test results
Overall, the results of the black-box test are quite satisfactory. Similarly, there are still some flaws, which is where the challenges and fun of programming lie. The results of the black-box test are shown in Figure 5-7.

Figure 5-7 Chinese matching black box test
5.2.3 Similar News Trend Display System Test Results
The black box test is similar to the news trend display system to test the effect of Echarts in order to distinguish it from the white box test JfreeChart. The test results are shown in Figure 5-8.

Figure 5-8 Black box test news ranking
Click on the relevant news above to display the trend development graph of a single news, as shown in Figure 5-9.

Figure 5-9 echarts black box test