The operation of the search system, in simple terms, finds the answer from the database after processing the user's search words. Now we only talk about the search system of intelligent question and answer. The system needs to store data in the early stage, and then read the data when the user searches. , so it is divided into two parts.
1. Data storage
The data needs to be stored in the graph database,
1.1. To build a map, it is necessary to define the entity categories and the relationship between entities to be extracted based on unstructured data and project requirements. For example, according to the user's question method, what answer do you want to query, and define the entity category and relationship according to the answer content.
1.2, model extraction, after constructing the entity, then extract information from unstructured text, I use the information extraction framework uie in paddleNLP,
It is necessary to label the model training set according to the entity labeling specification first, then train the entity extraction model, and then extract the unstructured document data, and store the extracted entities in the graph database and ES according to the graph standard format.
Specific practical steps reference link: link
2. Data reading
Next, use the intelligent question answering system in paddleNLP directly to build
a brief introduction to the intelligent question answering system. The question answering system is an advanced form of information retrieval system. It understands the questions entered by the user, then finds the answer from the knowledge base, and directly feeds back to user.
Using the question answering system in paddleNLP, you only need to simply process your own data and connect to the intelligent question answering system.
For specific operation steps and common problems, please refer to the document link between me: link
I directly use the post of the intelligent question answering system end, and replace it with its own ES library,
the intelligent question answering system in paddleNLP preset question answering system model (recall model, sorting model, reading comprehension model),
semantic retrieval system
1. Scenario overview
Retrieval system users can quickly find relevant documents in massive data by inputting the search term Query, which includes a semantic retrieval system. It can accurately capture the real intention behind the user's Query and use it to search, so as to accurately return the matching results to the user, find the vector representation of the text through the most advanced semantic indexing model, index them in the high-latitude space, and measure the query The degree of similarity between vectors and indexed articles can solve the defects caused by keyword indexing.
2. Functional Architecture
Semantic indexing can better represent semantic information. The key to the semantic retrieval system is to use semantics instead of keywords to recall similar results more accurately and extensively. The overall introduction is as follows: the left side is the recall link
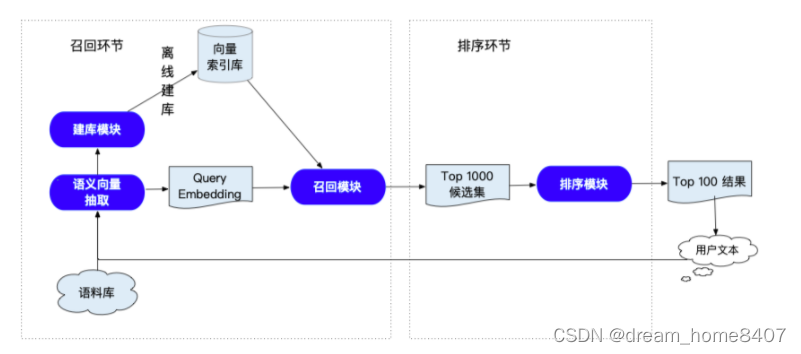
, The core is the semantic vector extraction module, the right side is the sorting link, and the core is the sorting model. The recall link requires the user to build a vector index library through his own corpus. After the user initiates a query, he can retrieve the vector with the highest similarity, and then find the vector
. The text corresponding to the vector, the sorting link mainly reorders the recalled text,
recall module
The recall module needs to quickly recall candidate data from tens of millions of data. First, it needs to extract the embedding of the text in the corpus, and then use all vector engines such as Milvus to implement efficient ANN, so as to realize the candidate set recall. ) fast (millisecond-level) screening of TopK Doc that has a high correlation with the household query word Query in the candidate text, and the
ANN in the vector search engine is used for efficient approximate nearest neighbor search (Approximate Nearest Neighbor Search). In large-scale datasets, iterating through each data point to find the nearest neighbors is very time-consuming. ANN utilizes the parallelism and distributed representation of neural networks to accelerate the process of nearest neighbor search by constructing an efficient index structure.
ANN can adopt a variety of structures and algorithms, such as k-nearest neighbor tree (kd tree), ball tree (ball tree), hash table (hashing), locality-sensitive hashing (LSH), etc. Based on different principles and data structures, these methods aim to quickly identify the closest data point to the query vector without the need for a global search of the entire dataset.
milvus
Sorting module
The sorting model will perform pairwise matching calculation for each Query and Doc on the basis of the TopK Doc results screened out by the recall model. The sorting model is more accurate, and the sorting module is based on a pre-training model ERNIE, which trains Pair-
wise The semantic matching model, the basic idea is to construct document pairs for samples, compare them pairwise, and learn the order from the comparison.
Evaluation Index
Model effect index
1. The index used in the recall stage of semantic retrieval is Recall@K, which indicates the overlap rate of the topk results before prediction and the real top k related results in the corpus, and measures the recall rate of the retrieval system. 2
. The index used in the sorting stage is AUC, which reflects the classifier’s ability to sort samples. If the samples are completely randomly classified, then AUC should be close to 0.5. The more likely the classifier is to rank the real positive samples in front, the greater the AUC value , the better the classification performance.
model training
(1) Construct an unlabeled data set for Domain-adaptive Pretraining using the query, title, keywords, and abstract fields of the literature; (2) Construct an unlabeled data set using the three fields of query, title, and
keywords , to conduct unsupervised recall training SimCSE;
(3) Use the query, title, keywords of the literature to construct a data set with positive labels, excluding negative label samples, and train based on the In-batch Negatives strategy; (4). Sorting stage
, Use user clicks (as positive samples) and non-clicked (as negative samples) data to construct a training set for the sorting stage and perform fine-tuning training.

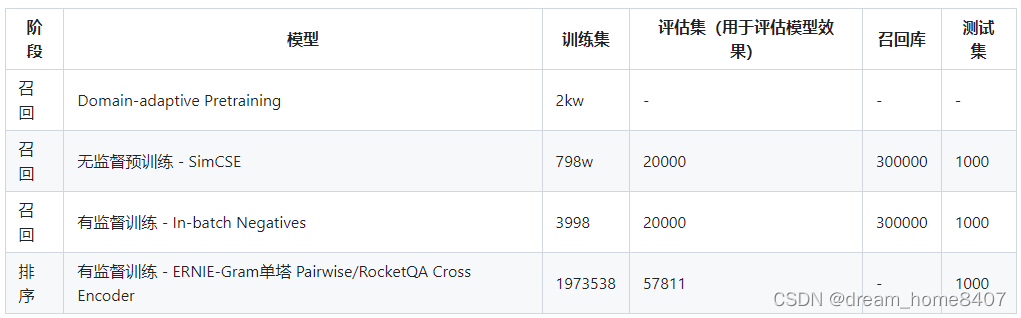
The first stage uses Domain-adaptive pretrain, which uses pre-training, which is a technology used in natural language processing to optimize the performance of pre-trained models in specific fields. The training model adapts to the target field. The following is a detailed explanation of the process.
1. Pre-training, first use ERNIE, BERT or GPT, and use unsupervised learning to perform pre-training on a large-scale general corpus. During the training process, the model predicts the mask in the text. Code words or sentences to learn general-purpose language representation. This step is to provide the model with powerful language understanding capabilities. 2.
Collect data in a specific field, in order to adapt the model to
a specific field. The model is further fine-tuned, the model parameters are updated through specific domain goals or tasks, and the weight of the model is adjusted through backpropagation and gradient descent. The model uses domain-specific data to adapt to the target domain by optimizing the domain-specific task objective function.
4. Transfer learning, after fine-tuning in a specific domain, the adapted model can be used for downstream tasks in the target domain.
domain_adaptive_pretraining/
|—— scripts
|—— run_pretrain_static.sh # 静态图与训练bash脚本
├── ernie_static_to_dynamic.py # 静态图转动态图
├── run_pretrain_static.py # ernie1.0静态图预训练
├── args.py # 预训练的参数配置文件
└── data_tools # 预训练数据处理文件目录
SimCSE (Similarity Classification and Sentence Embedding) is a method for learning sentence representation and measuring sentence similarity. The goal of SimCSE is to make similar sentences closer in the embedding space by encoding the input sentences, thus facilitating similarity measurement and semantic matching tasks.
The core idea of SimCSE is to use the self-comparison loss (Contrastive Loss) to train the model. Specific steps are as follows:
Sentence encoding: Use a pre-trained language model (such as BERT) to encode the input sentence to obtain the representation vector of the sentence.
Comparative sample generation: For each input sentence, a positive sample and several negative samples are randomly selected. A positive sample is another sentence that is semantically similar to the input sentence, while a negative sample is a sentence that is not semantically similar to the input sentence.
Contrastive Loss Computation: Computes the similarity score of the input sentence to the positive samples and compares it with the similarity score of the input sentence to the negative samples. Commonly used similarity measures include cosine similarity and inner product. The contrastive loss trains the model by maximizing the similarity score of the input sentence to the positive samples and minimizing the similarity score of the input sentence to the negative samples.
Training and Optimization: Use the backpropagation algorithm and gradient descent optimizer to update the model parameters so that the contrastive loss is as small as possible.
After the SimCSE training is completed, the trained sentence encoding model can be used to calculate the similarity score between any two sentences. This can be applied to a variety of natural language processing tasks, such as sentence similarity determination, question-answer matching, information retrieval, etc.
The advantage of SimCSE is that it can perform self-supervised learning without labeling data, and learn sentence representation through comparison loss, thus overcoming the limitation of requiring a large amount of labeled data in traditional supervised learning methods. At the same time, SimCSE is trained on large-scale unlabeled data, which can learn more general and rich sentence representations.
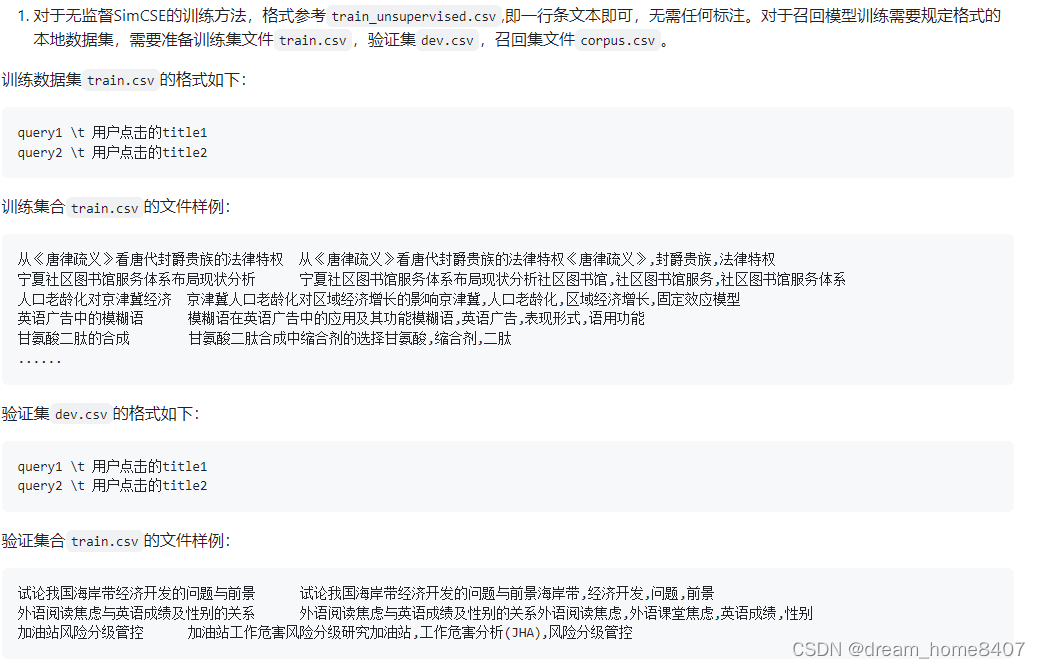
In-batch Negatives
link
If you want to train and access your own trained model, you can refer to Neural Search for recall and sorting model training. For the answer extraction model, please refer to machine_reading_comprehension for training tutorials. For the recall and sorting model access process, refer to Neural Search access for semantic retrieval. The process is enough. To read and understand the model, you only need to replace the model name with the path of your model when loading the model.
link: link
code analysis
Initialize Retriever Ranker Reader & Pipelines
1 Retriever
First, we need to initialize a Retriever. The function of Retriever is to extract vectors. The actual use is DensePassageRetriever. DensePassageRetriever uses two encoder models, one of which is used to encode query text, and the other Encode the passage text, and compare the two vectors of query and passage in the retrieval phase after encoding.
2 Ranker
Ranker reorders the passages retrieved by the retriever, forms a pair through query and passage, inputs it to the model for scoring, and then reorders the passages according to the scored values. ErnieRanker is used here.
3 Reader
The role of Reader is to scan the text sorted by Ranker, and then extract the best K answers. This project uses ErnieReader, which uses the Ernie-Gram model, and fine-tunes it on the dureader dataset. in the extraction of answer fragments.
link: link