Main points:
- R-CNN can be said to be the pioneering work of using deep learning for target detection.
One R-CNN algorithm
R-CNN can be said to be the pioneering work of using deep learning for target detection. The author Ross Girshick has won the PAS C A L V O C target detection competition many times , and led the team to win the Lifetime Achievement Award in 2010 .
The RCNN algorithm process can be divided into 4 steps:
- One image generates 1K~2K candidate regions (using the Selective Search method)
- For each candidate region, use a deep network to extract features
- The features are sent to the SVM classifier of each class to determine whether it belongs to the class
- Use the regressor to fine-tune the position of the candidate frame
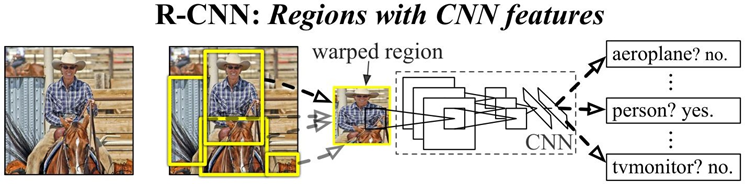
1.1 Generation of candidate regions
Use the Selective Search algorithm to obtain some original regions through image segmentation , and then use some merging strategies to merge these regions to obtain a hierarchical region structure, and these structures contain possible objects.
The Selective Search algorithm is an image segmentation algorithm based on object detection, which can divide the image into multiple regions, each of which has similar texture, color and other characteristics. This algorithm can be used in computer vision tasks such as object recognition and detection.
The core idea of the Selective Search algorithm is to generate a larger area by continuously merging similar small blocks. Specifically, it first divides the image into many small blocks, then calculates the similarity between these small blocks, and merges the small blocks with high similarity into a larger superpixel. This process is repeated many times until the entire image is divided into several superpixels.
In the Selective Search algorithm, the calculation of similarity can use a variety of methods, such as color histogram, edge density, texture and so on. In addition, in order to improve the efficiency of the algorithm, Selective Search can also use fast image segmentation techniques, such as Felzenszwalb and Huttenlocher algorithms.
Ultimately, the Selective Search algorithm generates a superpixel image, where each superpixel represents an image region with similar characteristics. This superpixel image can be used as input to computer vision algorithms such as object detection and recognition, increasing their accuracy and efficiency.

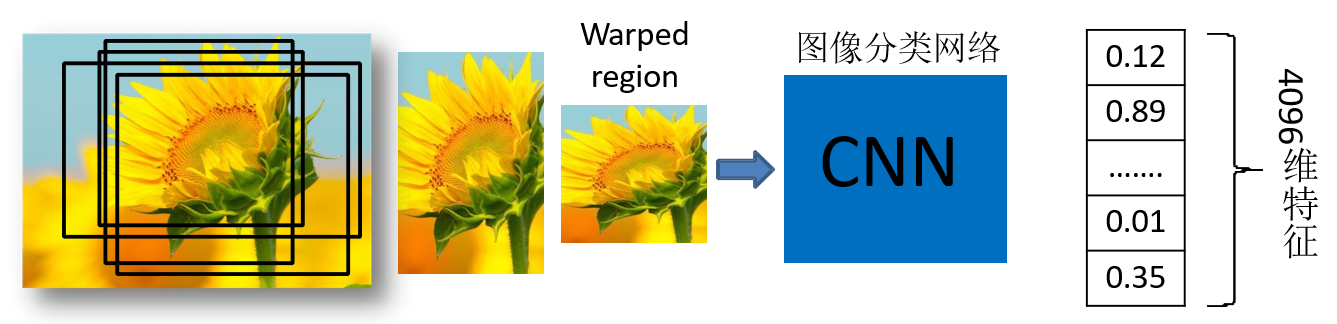
1.2 For each candidate area, use a deep network to extract features
Scale the 2000 candidate areas to 227x227pixel , and then input the candidate areas into the pre-trained AlexNet CNN network to obtain 4096-dimensional features to obtain a 2000 × 4096- dimensional matrix .
1.3 The features are sent to the SVM classifier of each category to determine the category
Multiply the 2000×4096-dimensional feature with the weight matrix 4096×20 composed of 20 SVMs to obtain a 2000×20-dimensional matrix indicating that each suggestion box is a score of a certain target category. Each column in the above 2000×20-dimensional matrix, that is, each category, is subjected to non-maximum value suppression to remove overlapping suggestion boxes, and some suggestion boxes with the highest scores in this column, that is, in this category, are obtained.
Multiply the 2000 × 4096 feature matrix with the weight matrix 4096 × 20 composed of 20 SVMs to obtain a 2000 × 20 probability matrix, and each row represents the probability that a suggestion box belongs to each target category. Each column in the above 2000 × 20- dimensional matrix, that is, each category, is subjected to non-maximum value suppression to remove overlapping suggestion boxes, and some suggestion boxes with the highest scores in this column, that is, in this category, are obtained .
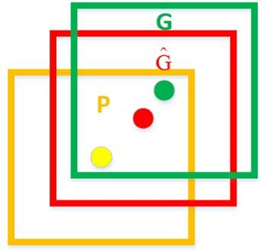
IoU (Intersection over Union) display (A∩B)/(A∪B)

1.4 Use the regressor to fine-tune the position of the candidate frame
R - CNN framework

1.5 Problems in R- C NN
-
The test speed is slow : it takes about 53s (CPU) to test a picture . It takes about 2 seconds to extract the candidate frame with the Selective Search algorithm . There is a large amount of overlap between the candidate frames in an image , and the feature extraction operation is redundant .
-
Slow training speed : the process is extremely cumbersome
-
Large space required for training : For SVM and bbox regression training, features need to be extracted from each target candidate box in each image and written to disk. For very deep networks such as VGG16 , features extracted from 5k images on the VOC07 training set require hundreds of GB of storage .