I was very envious of friends who could draw since I was a child. They can draw the thoughts in their hearts, and my highest level of portraits is old man Ding. But after I came into contact with Stable Diffusion, I felt like I was reborn, and I gave myself a new label of "can draw".
 Old Man Ding's Evolutionary Journey
Old Man Ding's Evolutionary Journey
Stable Diffusion is a "text-to-image" artificial intelligence model and the only AI drawing tool that is open source and can be deployed on a home computer (with low hardware requirements). With Stable Diffusion, you can generate images in seconds on a 6GB VRAM graphics card, 16GB RAM or CPU-only computer, with no pre- or post-processing required.
To experience AI drawing, you can use the online tools Hugging Faceopen in new window , DreamStudioopen in new window or Baidu Wenxinopen in new window . But compared to local deployment, Hugging Face needs to queue up, and it takes about 5 minutes to generate a picture; DreamStudio can generate 200 pictures for free, and then you need to pay for it; Baidu Wenxin can generate pictures in Chinese, but it is still in beta stage and has not been officially released. commercial. In addition, the picture adjustment functions of these online tools are relatively limited, and pictures cannot be generated in batches, and are only suitable for testing and experience.
If you need to generate a large number of AI pictures, you can deploy Stable Diffusion WebUI Dockeropen in new window to your home computer through Docker Desktop, so as to realize free AI text painting and get rid of the limitations of online tools. For Mac users, it is recommended to choose the invoke branch of Stable Diffusion. If an error occurs during deployment, you can refer to the InvokeAI document open in new window for troubleshooting. For M1/M2 Mac users, it is recommended to use the simpler CHARL-Eopen in new window or DiffusionBeeopen in new window .
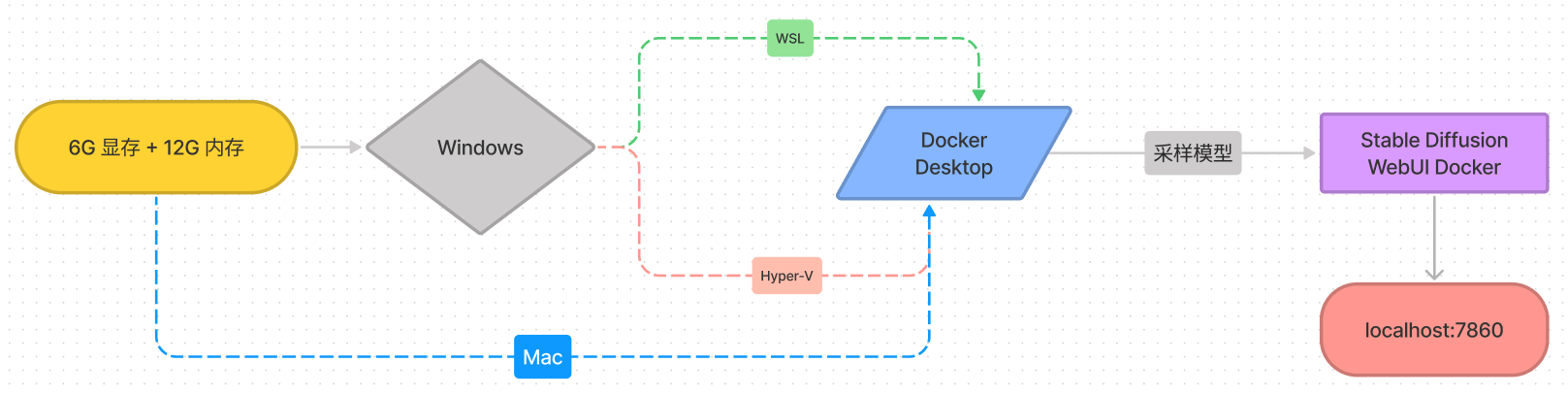 Stable Diffusion Deployment Process
Stable Diffusion Deployment Process
Taking the Windows platform as an example, this article will introduce the Docker environment configuration, Stable Diffusion installation and basic usage in sequence.
# Docker environment configuration
This solution is based on Docker configuration, which essentially creates an isolated file environment in a running Linux system. Therefore, Docker must be deployed on a Linux kernel-based system. [ 1] For Mac users, it can be used without special configuration. For Windows users, if you want to deploy Docker, you need to install a virtual Linux environment, configure WSL or enable Hyper-V . I recommend using Windows Subsystem WSL, which needs to occupy 30G of system disk space.
# install WSL
Enter the command in the administrator PowerShell wsl --install, after which the terminal will install Ubuntu by default. The system download time is long, be careful not to shut down. [ 2] After installing Ubuntu, follow the prompts to set the Ubuntu account and password.
#Enable Hyper-V
Open a PowerShell console as an administrator and enter commands Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All. [ 3] After restarting the computer, Hyper-V will be turned on.
# Linux paths (Windows)
Configuring WebUI Docker is going into a Linux environment, so Windows users need to convert their paths to Linux paths. Mac and Linux users can ignore this step.
Assuming the container is located at D:\Desktop\stable-diffusion-webui-docker:
- To change the disk symbol to lowercase, convert to
d:\Desktop\stable-diffusion-webui-docker - Add
/mnt/prefix to convert to/mnt/d:\Desktop\stable-diffusion-webui-docker. Because the Windows local disk is mounted under the Linux mnt directory. \Replace the backslash with/. Finally get the Linux path/mnt/d:/Desktop/stable-diffusion-webui-docker.
#Placement Stable Diffusion
#Install Docker Desktop
Choose Docker Desktopopen in new window version by platform, click Add Extensions on the left after installation, it is recommended to install the Disk usage extension, which will facilitate the management of Docker storage space.
Notice
There is a bug in Docker Desktop 4.17.1 that may cause Attaching to webui-docker-auto-1an error to . It is recommended to upgrade Docker Desktop 4.18.0 or downgrade to an earlier version.
#Download WebUI Docker
Download the Stable Diffusion WebUI Docker configuration package open in new window or Alibaba Cloud disk aggregation version open in new window (updated regularly), and then decompress it to the specified path. The aggregated version includes related dependencies and models, so the file size is larger. If you need to update the Stable Diffusion WebUI Docker, you can follow the steps above to rebuild the container.
#Branch introduction
Currently, Stable Diffusion has four branches: sygil, auto, auto-cpu and invoke. If you need to change the branch, you can modify docker compose --profile [ui] up --buildin [ui]and replace it with the desired image name. The original hlkybranch has been renamed sygil, lsteinand the branch has been renamed invoke.
- sygil : The interface is intuitive, the highest resolution is 1024x1024, and the image build command is
docker compose --profile sygil up --build. - auto (recommended): set the most abundant modules, display the painting process, support random insertion of artists, parameter reading and negative description, the highest resolution is 2048x2048 (higher resolution requires higher video memory), and the mirror image build command is
docker compose --profile auto up --build. By default, more than 6GB of video memory is used. If your video card memory is low,--medvramchange--lowvram. A card users pay attention to modify the graphics card settings open in new window . - auto-cpu : The only branch that does not depend on the graphics card. If you do not have a graphics card that meets the requirements, you can use the CPU mode, and the memory configuration must meet the requirements of 16G or more. The command to build the image is
docker compose --profile auto-cpu up --build. - invoke : The cli side is very mature, the WebUI side has fewer parameters, and can automatically read picture records. It is suitable for novices and Mac users without advanced needs. The image build command is
docker compose --profile invoke up --build.
#Build Stable Diffusion
After starting Docker Desktop, open the WSL (Ubuntu) or Mac terminal, and enter the path switching command cd /mnt/d/Desktop/stable-diffusion-webui-docker(the path is the Stable Diffusion WebUI Docker decompression file directory). Next, enter the following deployment command:
# 自动下载采样模型和依赖包
docker compose --profile download up --build
# 上方命令需要 20 分钟或更长,完成后执行镜像构建命令
docker compose --profile sygil up --build
# auto 是功能最多的分支,可以选择 auto | auto-cpu | invoke | sygil | sygil-sl

After the build is completed, you will be prompted to access in the terminal http://localhost:7860/, and you can use AI to generate pictures on your local computer. [ 4]
#Instructions for use
The following example uses the sygil branch as an example. The theme interface of other branches is slightly different, but there is no fundamental difference in function.
#Start Stable Diffusion
- Open Docker Desktop.
- Select the branch container in Containers and click Start.
- Access in a browser
http://localhost:7860/.
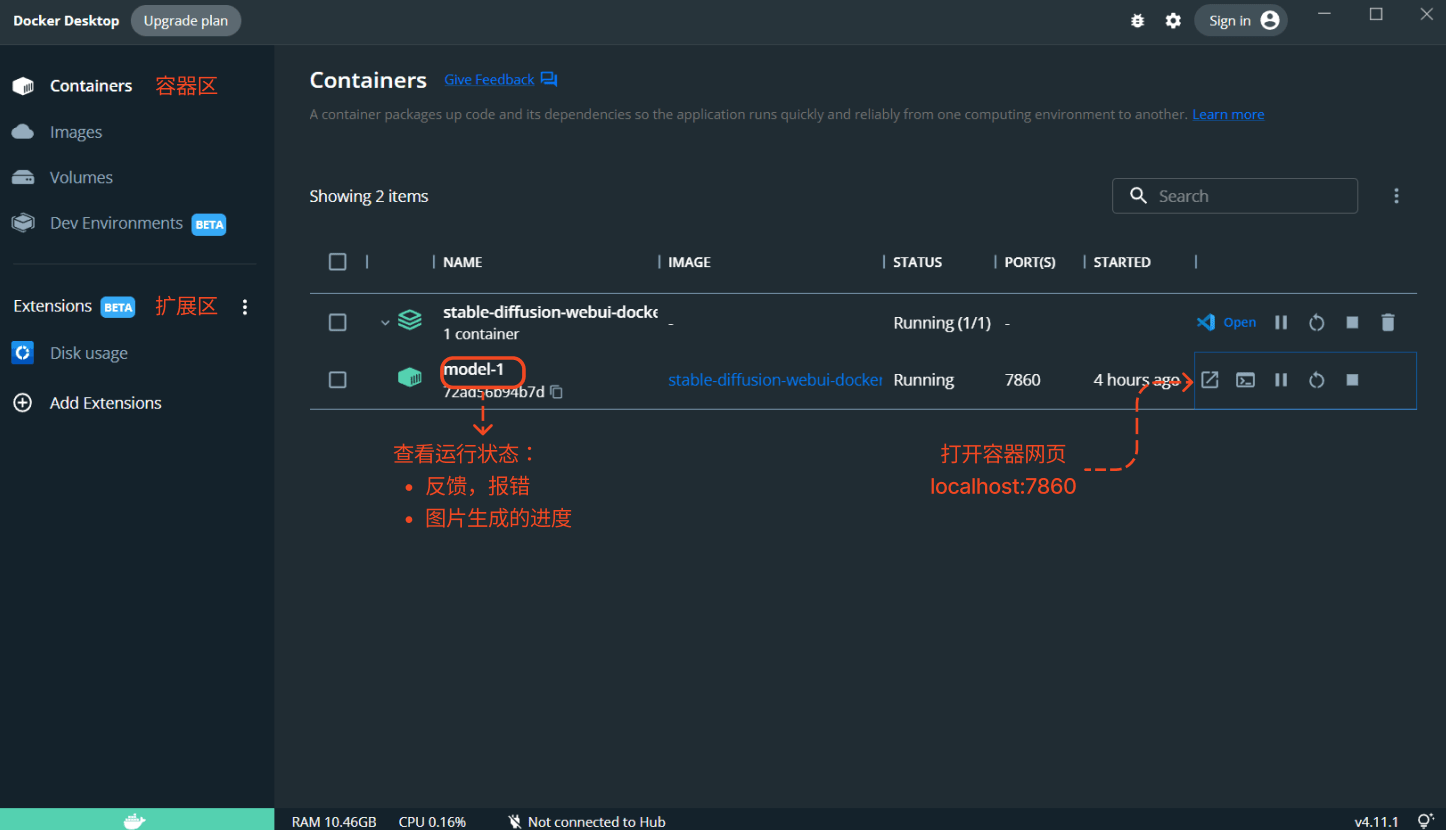 Docker Desktop interface
Docker Desktop interface
#Text-to-Image
Text-to-Image is a method for Stable Diffusion to generate images based on text descriptions. For the types of paintings that advocate spatial structure, such as landscapes and creative paintings, it is recommended to use vertical or horizontal pictures. For portrait paintings, it is recommended to use a 1:1 square image, otherwise multiple faces may be superimposed. The resolution of the generated image is limited, and you can use Upscale to enlarge the resulting image.
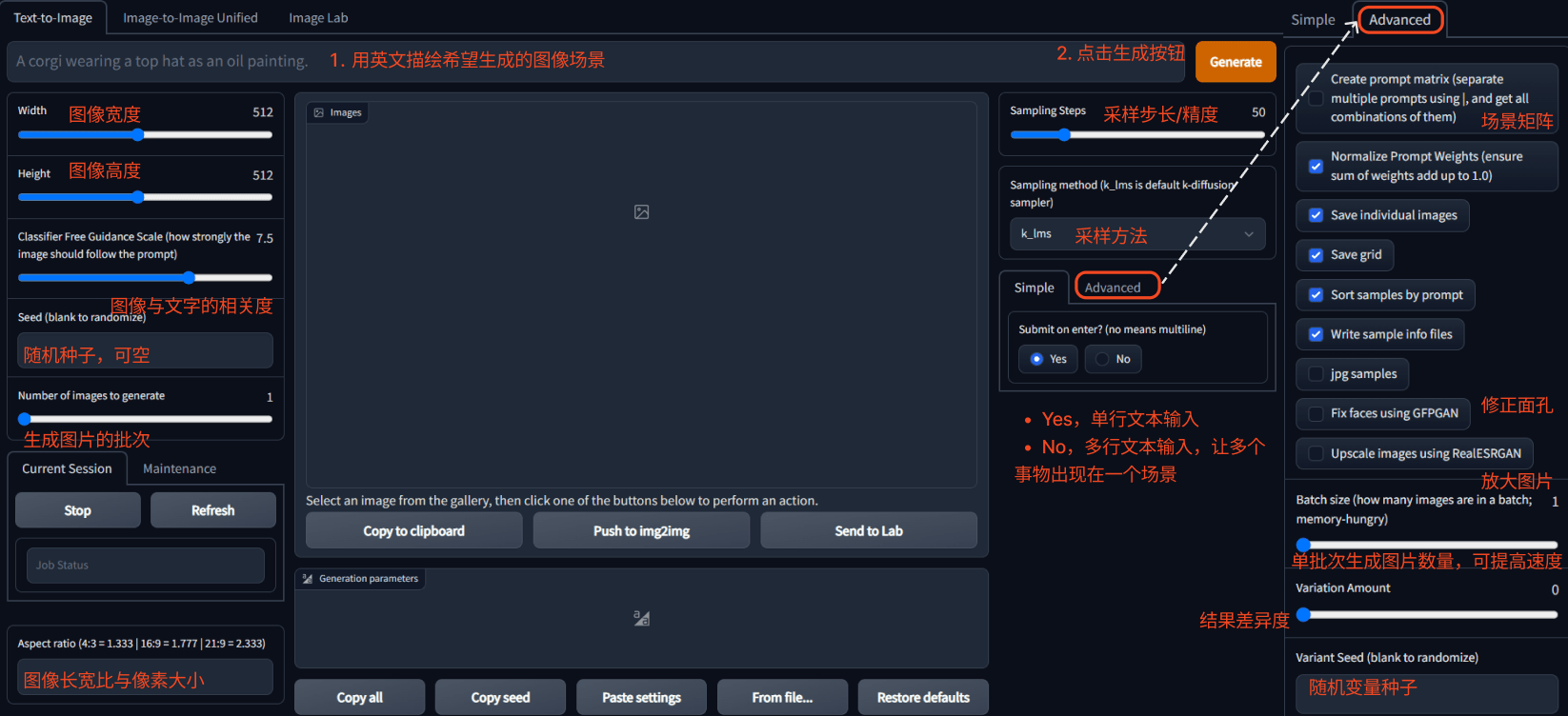 Text-to-Image interface
Text-to-Image interface
The Simple mode is used by default. If you want to use more functions, you can click the Advanced button on the right to enter the advanced options. In the advanced options, you can use a variety of advanced features such as scene matrix, face repair and resolution upscaling.
#Image-to-Image
Image-to-Image is to generate relevant images based on text descriptions and input source images. If the input source image is Text-to-Image, sketch or structural drawing, this mode can fully fill the image details. However, if the input source image is a photo with sufficient details, the generated result will be quite different from the original image. In addition, you can limit the area to generate images, which is very suitable for image modification.
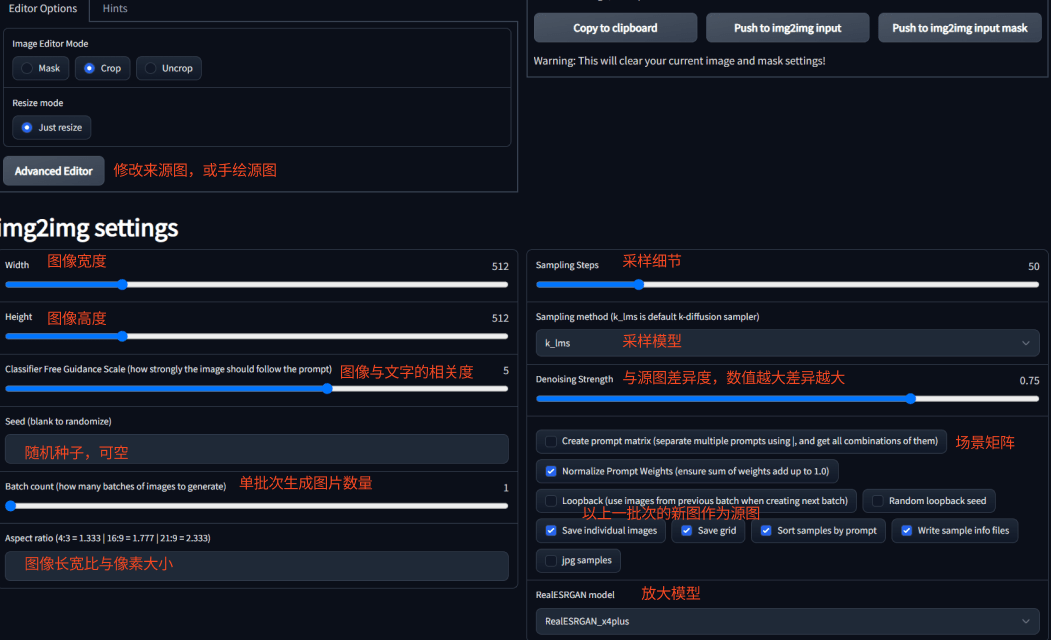 Image-to-Image interface
Image-to-Image interface
CLIP interrogator generates text descriptions from images. Denoising Strength refers to the degree of difference from the original image, and it is recommended to set it between 0.75-0.9. To denoise the picture, set the Denoising Strength to 0.5 or below. The Denoising Strength in the picture below is only 0.44, and the overall picture structure and elements have not changed, but you can see the result.
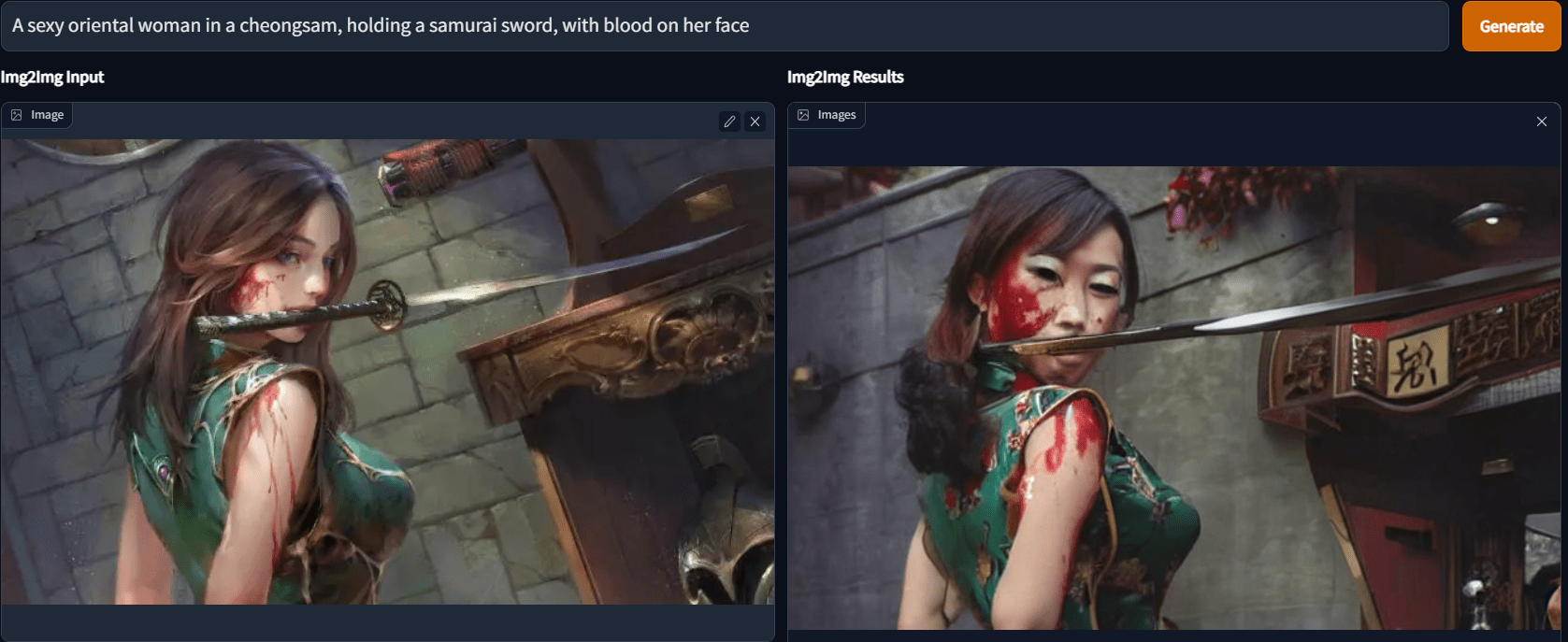 Super magic change picture
Super magic change picture
Image-to-Image can also be used to remove, replace or repair images, and even use the source image as part of the resulting image, extending the painting with Stable Diffusion.
#Image Lab
Image Lab has the functions of correcting faces and enlarging image resolution in batches.
Fix Faces uses the GFPGAN model to improve the faces in the picture, and the Effect strength slider can control the strength of the effect. But don't report too high expectations for the actual effect. Fix Faces is turned on on the right side of the picture below, which can only be said to barely have facial features.
 A woman flying in the air laughing
A woman flying in the air laughing
Upscale can enlarge the image resolution through four models: RealESRGAN, GoBIG, Latent Diffusion Super Resolution and GoLatent. Among them, RealESRGAN has two modes, normal mode and cartoon mode, you can choose according to your needs. Enlarging the image mainly consumes CPU and memory resources.
#parameter explanation
#Classifier Free Guidance
The default value for Classifier Free Guidance (CFG) is 7. The lower the number, the more creative freedom and the less relevant the model is to the prompt. The CFG parameter does not affect the required VRAM or build time.
- CFG 2-6: While creative, may not meet the cue.
- CFG 7-10: Applicable to most situations, these tips are both creative and instructive.
- CFG 10-15: Use when you are sure the prompt is good enough and specific enough.
- CFG 16-20: Not recommended unless the prompt is very detailed. This may affect consistency and quality.
#Step
The default value of Step (sampling step size/precision) is 50. Stable Diffusion starts creating an image with a canvas full of noise and progressively denoises it towards the final output. The Step parameter controls the number of these denoising steps. Usually, the higher the better. For starters, it is recommended to use the default values. The Step parameter does not affect the required VRAM, but changes in the Step value will be proportional to the time to generate the image.
#Seed
The default value of Seed is -1, representing a random value. Seed is the number that controls the initial noise. When other parameters are fixed, the generated image will be different each time. This is the role of the seed. You can get the same result if you keep the prompt, seed and all other parameters the same. If a Seed produces a high-quality image, save that Seed and apply it to other images to maintain the high quality.
#Sampler
The Sampling method/Diffusion Sampler is a method used to denoise the image during image generation. Since different diffusion samplers calculate the next step of the image differently, they require different durations and steps to produce a usable image. DDIM is recommended for beginners as it is fast and usually takes only 10 steps to generate a good image, so it is easy and fast to experiment and improve.
#text description image
Stable Diffusion uses English text content to describe scenes or objects to determine what will appear in the generated image. Text description is a key factor in determining the quality of image generation. [ 5]
Example: A beautiful painting {画作种类} of a singular lighthouse, shining its light across a tumultuous sea of blood {画面描述} by greg rutkowski and thomas kinkade {画家/画风}, Trending on artstation {参考平台}, yellow color scheme {配色}. [ 6]
Describing images requires multiple descriptions, so I developed an open source tool, IMGPromptopen in new window , in order to generate image prompt words.
# General description
- The object and subject of the input image, such as a panda, a warrior with a sword, do not describe actions, emotions and events ; [ 7]
- Type of image : a painting (a painting of + raw prompt) or a photograph (a photograph of + raw prompt), or Watercolor (watercolor), Oil Paint (oil painting), Comic (manga), Digital Art (digital art) , Illustration, realistic painting, photorealistic, Portrait photogram, Low Poly, 3D Item Rende, sculpture, etc. Image types can be superimposed.
- Painter/painting style : It is recommended to mix the styles of multiple painters, for example
Studio Ghibli, Van Gogh, Monet, or describe the type of style, for examplevery coherent symmetrical artwork, set the structure of the work to "coherent and symmetrical". - Hue : yellow color scheme means that the main color of the whole picture is yellow.
- Reference platform : Trending on ArtStation, can also be replaced by "Facebook", "Pixiv", "Pixbay", etc.

#Characteristic description
In addition to the main body of the picture, other concrete objects and adjectives can be used to fill in the details of the picture. Be specific with your descriptors, telling what you want and its characteristics.
- Secondary elements: Not too many objects, just two or three. If you want to emphasize a certain element, you can add a lot of brackets or exclamation points. For example, the "desert" and "sunset" elements will be given priority
beautiful forest background, desert!!, (((sunset)))in . - Character Traits:
detailed gorgeous face, delicate features, elegant, Googly Eyes, Bone, big tits, silver hair, olive skin, Mini smile; - Specific polish:
insanely detailed and intricate, gorgeous, surrealism, smooth, sharp focus, Painting, Digital Art, Concept Art, Illustration, Artstation, in a symbolic and meaningful style, 8K; - ray description:
Natural Lighting, Studio Lighting, Cinematic Lighting, Crepuscular Rays, X-Ray, Backlight; - Lens angle of view:
Cinematic, Magazine, Golden Hour, F/22, Depth of Field, Side-View, to blur the backgroundBokeh; - Graphics Quality:
professional, award winning, breathtaking, groundbreaking, superb, outstanding, or Unreal EngineUnreal Engine; - Other descriptions: details and textures, how much objects occupy the frame, age, rendering/modeling tools, etc., such as Vivid Colors.
# prompt weight
Assuming you used in the prompt words mountain, the resulting image will most likely have trees. But if you want to generate an image of a mountain without trees, you can use mountain | tree:-10. where tree:-10represents a very negative weight for the tree, so no tree will appear in the generated image. By weighting words, we can also generate more complex images, eg A planet in space:10 | bursting with color red, blue, and purple:4 | aliens:-10 | 4K, high quality. [ 8]
The order of words in the prompt represents their weight, and the higher the front, the greater the weight. If something does not appear in the image, the noun can be placed first.
# Negative Prompt
Negative prompt can be set in the auto/auto-cpu branch to avoid specific elements appearing in the screen.
- Correction of deformities:
disfigured, deformed hands, blurry, grainy, broken, cross-eyed, undead, photoshopped, overexposed, underexposed, lowres, bad anatomy, bad hands, extra digits, fewer digits, bad digit, bad ears, bad eyes, bad face, cropped: -5. - Avoid nudity:
nudity, bare breasts. - Avoid black and white photos:
black and white,monochrome.
# prompt reference
Except for the description of the main body of the screen, other elements are not mandatory. If you're just trying it out simply, enter the subject "apples".
If you don’t know what image to generate, you can use promptoMANIAopen in new window , WEIRD WONDERFUL AI ARTopen in new window to combine descriptions according to the prompts, or refer to the finished images and descriptions shared by others on the AI gallery PromptHeroopen in new window and OpenArtopen in new window ,for example
goddess close-up portrait skull with mohawk, ram skull, skeleton, thorax, x-ray, backbone, jellyfish phoenix head, nautilus, orchid, skull, betta fish, bioluminiscent creatures, intricate artwork by Tooth Wu and wlop and beeple, highly detailed, digital painting, Trending on artstation, very coherent symmetrical artwork, concept art, smooth, sharp focus, illustration, 8k
#Prompt matrix
Prompt matrix is a function of the sygil branch, which can generate multiple related but different pictures according to different conditions, suitable for making video materials. [ 9] At this time, the setting of the batch size will be ignored. If you're interested in converting images to video, try Deforum Stable Diffusion Local Versionopen in new window .
The training words for the above video are A mecha robot in World War II in realistic style|Shoot with another mecha robot|Bombed by planes|Missile drop|broken|Repaired|cinematic lighting. |The scene conditions after the symbols will be arranged and combined. There are 6 scene conditions in the video sample to generate 64 pictures.
In addition, we can specify the location of the scene condition, such as to @(moba|rpg|rts) character (2d|3d) modelindicate (moba|rpg|rts 三选一) character (2d|3d 二选一) modelthat 3*2 pictures will be generated. At the beginning @is the symbol that triggers the position of the specified scene condition and cannot be omitted.
#Textual Inversion
Textual Inversion (text inversion) is a function provided by the auto/auto-cpu branch, which can personally customize the meaning of words in the model. For example, most of the doctors in the public model are white men, but we can input 5 photos of Asian women and associate them with the doctor, and the images of doctors generated by the model after Textual Inversion processing will be mainly Asian women. [ 10]
Textual Inversion customization process:
- Preprocess images: Set the source map directory and output directory.
- Create embedding: Create model properties.
- to be continued.
#faq _
#Docker Desktop failed
An error may be reported when the Docker container is not properly installed/closed Docker Desktop failed to start/stop.
First delete the Docker folder under %AppData%the path , and then enter the following command in PowerShell to close WSL and docker-desktop. Finally, restart Docker Desktop manually.
wsl --shutdown
wsl -l -v
wsl --unregister docker-desktop
wsl -l -v
#Docker Desktop cannot start
Hardware assisted virtualization and data execution protection must be enabled in the BIOSThe error indicates that virtualization is not enabled on the computer.
Press or to enter the BIOS several times during startup, then enable "Intel Virtual Technology" in the settings, and set "SVM Support" to "Enable" for AMD; finally click "F10" to save and exit F2.DEL
# docker command failed
The command 'docker' could not be foundIt means that the current command line is indeed missing the Docker environment, check whether Docker Desktop is started.
#exited with code 137
Generally speaking, exited with code 137it means that there is insufficient memory, and the process is closed when the memory limit is exceeded. It is recommended that the minimum hardware configuration is 16G memory, especially when using auto-cpu mode.
# Port access denied
The Docker container was running normally, but the port access was suddenly denied, showing Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:7860 -> 0.0.0.0:0: listen tcp 0.0.0.0:7860: bind: An attempt was made to access a socket in a way forbidden by its access permissions.
Type in Powershell netsh int ipv4 show excludedportrange protocol=tcpto check if you are in the range of excluded ports, then type reg add HKLM\SYSTEM\CurrentControlSet\Services\hns\State /v EnableExcludedPortRange /d 0 /fto open the port. After the operation is complete, restart the computer to unblock the port. [ 11]
#FileNotFoundError
An error is reported when building the container again FileNotFoundError: [Errno 2] No such file or directory: '/models/model.ckpt', which is caused by the wrong location of the structure. At this point, we need to check whether the architecture command entered through WSL, and whether the Stable Diffusion WebUI Docker decompression path is configured correctly.
# sample model
Sampling models are at the heart of AI painting. 2022.09.10 has supported automatic download of sampling models, the list below is for reference only.
- Stable Diffusion v1.4 (4GB)open in new window , rename the archive file to
model.ckpt. - (Optional) GFPGANv1.4.pth (340MB)open in new window .
- (Optional) RealESRGAN_x4plus.pth (64MB)open in new window and RealESRGAN_x4plus_anime_6B.pth (18MB)open in new window .
- (Optional) LDSR (2GB) open in new window and LDSR configuration open in new window , renamed to
LDSR.ckptandLDSR.yaml.
#last _
Although Stable Diffusion is not yet a productivity tool, it makes design easier and opens up the possibility of AI painting for ordinary people. It is recommended that you experience it yourself and deploy it in practice so that you can have more possibilities.