
Organize | Zheng Liyuan
Listing | CSDN (ID: CSDNnews)
The battle of AI large models started by ChatGPT has been going on for several months around the world, among which the industry is particularly concerned about the game between OpenAI and Google.
Once, Transformer, which was first released in 2017, laid the cornerstone of LLM for Google, and the debut of the chat robot LaMDA in 2021 was even more amazing in the circle. At that time, most people believed that Google, which has been laying out this AI game for many years and has a first-mover advantage, will firmly occupy the throne-unexpectedly, it was the "dark horse" OpenAI that finally took the lead. Instead, Google has become a passive "chaser" from the "big brother" in the field of AI.
So, who will ultimately win this protracted AI war? Is it OpenAI, which seized the opportunity, or Google, which has accumulated a lot of knowledge?
In this regard, an internal Google document leaked by an anonymous person in the Discord group recently gave a third possibility: " We did not win this competition, and neither did OpenAI. While we were still arguing, a third party already Quietly stole our jobs - open source. "
Next, let us take a look at how this Google "internal leak" document analyzes the current trend and development of the global AI war.

We don't have a moat, and neither does OpenAI
We've been following the dynamics of OpenAI, who will cross the next milestone? What will be the next step?
But the uncomfortable truth is that we didn't win this competition, and neither did OpenAI. While we were still arguing, a third party had quietly robbed us of our jobs.
Of course, I am referring to open source. In short, they are outrunning us. What we consider to be "major open issues" is solved today and people are using it. Just to name a few:
▶ LLMs on phones: People run base models on Pixel 6 at 5 tokens/sec.
▶ Scalable Personalized AI: You can fine-tune the personalized AI at night with your laptop.
▶ Responsible release: This problem is not "solved", but "avoided". The entire Internet is full of artistic model sites without any restrictions, and the text is not far away.
▶ Multimodality: The current multimodal ScienceQA SOTA training time is 1 hour.
While our model is still slightly better in terms of quality, the gap is shrinking surprisingly. The open source model is faster, more customizable, more private, and more capable. They did with $100 and 13B parameters what we couldn't do with $10 million and 540B parameters. And they only need weeks to complete the task, not months. This has profound implications for us:
▶ We have no secret formula. We would most like to learn and collaborate from others other than Google, and we should prioritize enabling third-party integrations.
▶ People won't pay for a restricted model when free, unlimited alternatives are comparable in quality. We should consider where our added value is.
▶ Huge models are slowing us down. In the long run, the best models are those that can be improved iteratively quickly. Now that we know what is possible within the parameters of 20B, small variations should no longer be considered an afterthought.
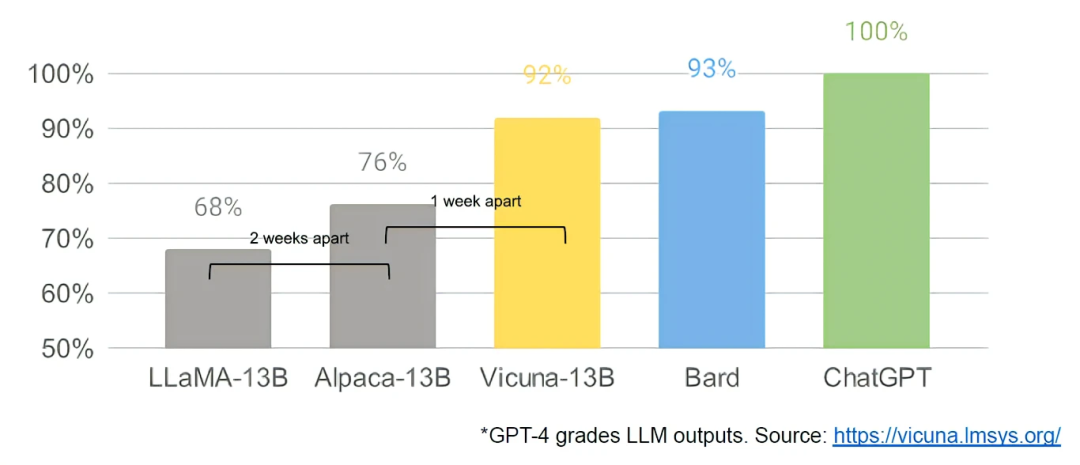

what happened
In early March, the open source community got their first truly capable base model - Meta's LLaMA was accidentally leaked. It has no command or dialogue adjustments, and no RLHF. Still, the community immediately understood the significance of what they got.
Huge innovations followed, with only a few days between major advances (see timeline for full details). In just under a month, variants with instruction tuning, quantification, quality improvement, human evaluation, multimodality, and RLHF have emerged, many of which build on each other.
Most importantly, they solve scaling problems to the extent that anyone can experiment. Many new ideas come from ordinary people, and the threshold for training and experimentation has dropped from the total output of major research institutions to one person, one night, and a powerful laptop.

why we could have foreseen this
In many ways, this shouldn't come as a surprise to anyone. The current renaissance of open-source LLMs is on the heels of a renaissance in image generation. These parallels have not been overlooked by the community, with many calling it LLM's "Stable Diffusion moment."
In both cases, low-cost public participation was achieved thanks to a massively reduced price mechanism called Low-Rank Adaptation (LoRA), combined with major breakthroughs in scale (potential diffusion in image synthesis and Chinchilla in LLMs ). In both cases, obtaining a sufficiently high-quality model launched a series of ideas and iterations from individuals and institutions around the world. In both cases, this quickly surpassed the larger companies.
These contributions were pivotal in the field of image generation, taking Stable Diffusion on a different path from Dall-E, allowing it to have an open model, leading to product integration, marketing, user interface and innovation, all of which are Dall-E No.
The effect is predictable: cultural influence quickly takes hold, and OpenAI solutions become increasingly irrelevant. Whether the same thing will happen with LLM remains to be seen, but the broad structural elements are the same.

what did we miss
The innovations that open source has succeeded in recent years directly address problems we are still grappling with. Paying more attention to what they do might help avoid reinventing the wheel.
LoRA is a very powerful technology and we should pay more attention to it.
LoRA works by representing model updates as a low-rank decomposition, which reduces the size of the update matrix by a factor of thousands, minimizing model fine-tuning cost and time. Being able to personalize language models in a few hours on consumer-grade hardware has important implications when it comes to integrating new and diverse knowledge in real-time. Although this technology directly impacts our most ambitious projects, it is underused internally at Google.

Retraining a model from scratch is a tough road
Part of the reason LoRA is so effective is that it is stackable like other forms of fine-tuning. For example, improvements such as instruction fine-tuning can be applied and leveraged when other contributors add dialogue, reasoning, or tool usage. While individual fine-tuning levels are lower, their sum does not, allowing full-level updates of the model to accumulate over time.
This means that, as newer and better datasets and tasks become available, the model can be kept updated cheaply without paying the full cost of running it.
In contrast, training a huge model from scratch discards not only the pre-training content, but also the iterative improvements that have already been made. In the open-source world, these improvements don't take long to take hold, making full retraining prohibitively expensive.
We should think carefully about whether each new application or idea really requires a whole new model. If there are indeed major architectural improvements that make direct re-use of model weights difficult, then investing in more aggressive forms of refinement will allow us to preserve as much of the previous generation's capabilities as possible.

If we can iterate on small models faster, then big models won't be more advantageous in the long run
LoRA updates are very cheap (~$100) for the most popular model sizes, which means that almost anyone with an idea can generate and distribute one. Training for less than a day is normal, and at this rate it doesn't take long for the cumulative effect of all these fine-tuning to overcome the size disadvantage to begin with. In fact, in terms of engineer time, these models improve far faster than our largest variants can, and the best models are already essentially indistinguishable from ChatGPT. Focusing on maintaining some of the largest models in the world can actually put us at a disadvantage.

Data quality is more important than data size
Many projects save time by training on small, highly filtered datasets. This shows that the data scaling law has some flexibility. These datasets were built using synthetic methods (such as filtering out the best responses from existing models), and were sourced from other projects, neither of which was dominant at Google. Fortunately, these high-quality datasets are open source and thus freely available.

Competing directly with open source is a losing proposition
These recent developments have direct, immediate implications for our business strategy. Who pays for Google products when there is a free, high-quality, unlimited-use alternative?
And we shouldn't expect to be able to catch up. The reason why the modern Internet runs on open source is that open source has some important advantages that we cannot replicate.

We need them more than they need us
Keeping our technology secret has always been a shaky proposition. Google researchers often leave for other companies, so we can assume they know everything we know, and will continue to know as long as this channel remains.
However, conducting cutting-edge research in the field of LLMs at low cost makes it more difficult to maintain a technological competitive advantage. Research institutions around the world build on each other's work and explore the solution space in a breadth-first manner far beyond our own capabilities. We can try to cling to our own secrets when external innovations undercut their value, or try to learn from each other.

Individuals are not subject to license restrictions like companies
Most of this innovation is based on the model weights leaked by Meta. While that will inevitably change as truly open models get better, the thing is, they don't have to wait. Legal protections for "personal use" and the impracticality of prosecuting individuals mean that individuals can acquire these technologies while the iron is hot.

Being your own customer means you understand the use case
When looking at the models people have created in the field of image generation, there is a lot of creativity emerging, from animation generators to HDR landscapes. These models are used and created by those deeply immersed in their particular subgenre, endowing them with a depth of knowledge and empathy beyond our reach.

Owning the Ecosystem: Making Open Source Work for Us
Paradoxically, the only clear winner in all of this is Meta. Because the leaked model is theirs, they're effectively getting free labor worth a fortune around the world. Since most open source innovation happens on top of their architecture, there's nothing stopping them from incorporating it directly into products.
The value of having an ecosystem is self-evident, and Google itself has successfully used this model in its open source products such as Chrome and Android. By owning the platforms on which innovation happens, Google solidifies itself as a thought leader and direction setter, and earns the ability to shape narratives of thought beyond its own.
The tighter we control the model, the more attractive open alternatives will be. Both Google and OpenAI have adopted a defensive release model to maintain tight control over how their models are used. But this control is illusory, and anyone who wants to use LLMs for unsanctioned purposes can simply pick and choose from freely available models.
Google should be an open source community leader, taking the lead when working with the broad conversation, not ignoring it. This might mean taking uncomfortable steps like publishing model weights for small ULM variants. This necessarily means giving up some control over our models, but such compromises are unavoidable, and we cannot hope to both drive and control innovation.

Conclusion: How about OpenAI?
Given OpenAI's current closed policy, all this talk of open source feels unfair. If they don't share, why should we? But the fact is that we are already sharing everything with senior fellows in the midst of a steady loss of senior fellows. There is no point in secrecy until we stop this trend.
Ultimately, OpenAI doesn't matter. They have made the same mistakes we have made in their stance relative to open source, and their ability to maintain an advantage must be called into question. Unless they change their stance, open source alternatives will eventually overtake them. At least on this point, we can preemptively.

Netizen: Google doesn’t have a moat, so maybe OpenAI doesn’t either
The above is most of the content of Google's internal leaked documents. The statement that "open source will be the ultimate winner" in the article quickly aroused heated discussions on the Internet, and most people did not agree with it.
▶ “The part that resonates with me is that working with the open source community might make a model improve faster. But I would say that users will go to whose model is the best, and the winning strategy is to have your model in Iterating faster, better and more consistently in quality, and open source doesn't always win here.
So I think there's a revelation: open source will win in areas where the users are usually software developers, because they can make improvements to the products they use. And closed source will win in other areas. "
▶ "So, having enough scale to permanently provide free/low-cost computing is a moat, but Google doesn't have a moat, and neither does OpenAI: the main reason ChatGPT is all the rage is because it's free and has no restrictions , but currently Google is not."
▶ "The barriers to entry for ordinary people into ChatGPT are low, while the barriers to using open source alternatives are high. At the same time, OpenAI is different from Google, ChatGPT is their only product, the focus of all, so OpenAI can still improve very quickly.
Also, now that AI == ChatGPT for most consumers, OpenAI now has the best market share, which means that there is the most user feedback to improve their products, and they can iterate at a fast pace. "
So, what do you think of this Google internal leaked document statement?
Reference link:
https://www.semianalysis.com/p/google-we-have-no-moat-and-neither?continueFlag=bd4fddecd5a8db3ad9503af53320e97c
https://news.ycombinator.com/item?id=35813322&p=2