This article
This article is based on the big data technology principle and application MOOC of Xiamen University, and recommends students who have enough time to study carefully.
https://www.icourse163.org/course/XMU-1002335004
Big Data Overview
Processing Architecture Hadoop
Distributed file system HDFS
Distributed database HBASE
Introduction
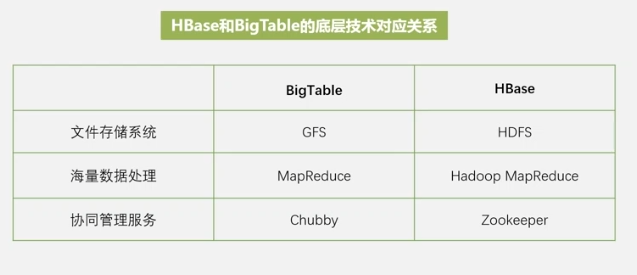
Google previously used BigTable for internal large-scale web search, and HBASE is an open source implementation of BigTable.
HBASE is a distributed database that can be used to store unstructured and semi-structured loose data.
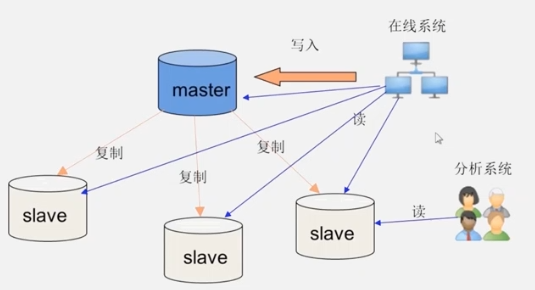
The birth significance of HBASE

Traditional databases, when the amount of data increases, use the "master-slave server" method to optimize, so that the read load is distributed to the slave servers with the same content to achieve performance expansion. However the "write" load cannot be optimized.
Another optimization scheme is
- Sub-library: one library for each business department (cannot be solved fundamentally, and will continue to increase)
- Manually slice and deploy to different servers (troublesome, manual operation, low efficiency)
The difference between HBASE and traditional database

- Data operations: time-consuming operations such as connections are discarded by HBASE
- Data indexing: only simple indexing on row keys is supported
- Data maintenance: old versions are retained, with time stamps, and deleted after expiration.
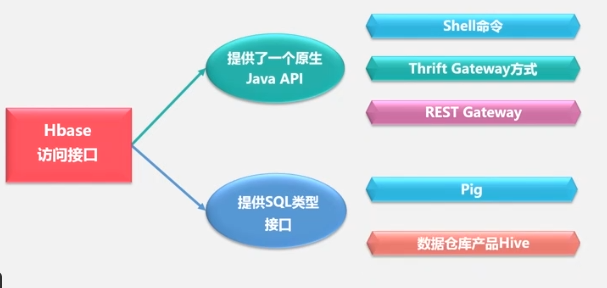
HBASE access interface:
HBASE data model
Sparse multidimensional sorted mapping table
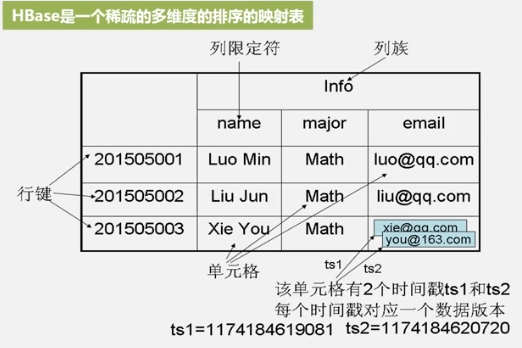
- Through row key + column family + column qualifier + timestamp = a specific data.
- Each value is an uninterpreted Bytes array, which needs to be parsed by the developer.
- A row has a row key and columns.
- The column family supports dynamic expansion, increase and decrease, and supports retention of old versions (HDFS only allows addition, not modification).
- Column qualifiers support dynamic expansion, increase and decrease.
- A cell holds data for multiple timestamps.
Locating a data requires 4 keys

Data Conceptual View
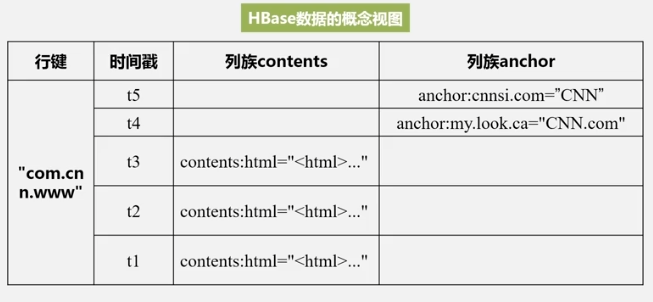
contents is the column family, html is the column qualifier, and the quotation marks are the values. You can see that the 4 keys determine a data, and it is sparse, which is why it is called a sparse multi-dimensional sorted mapping table.
Data Physical Storage View

It can be seen that HBASE is columnar storage. The advantage of columnar storage is that when fetching data, a certain attribute is usually extracted for analysis. For example, only the student’s grades are needed but not other column information such as address, hometown, etc., row-based storage needs to fetch a row and then extract some data , each line is scanned, which is equivalent to traversing all of them.
In addition, the data types of a column of data are generally related, and column storage can bring a high data compression rate.
How to choose a storage method?
If the application is mainly based on analysis, column storage is used.
If there are many transactional operations, use row storage.
The realization principle of HBASE
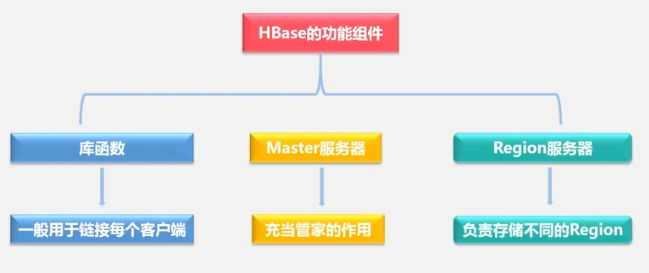
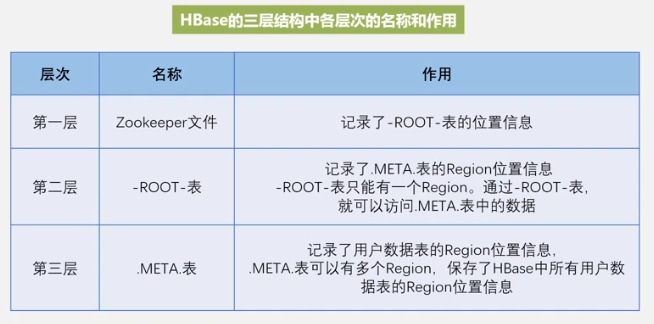
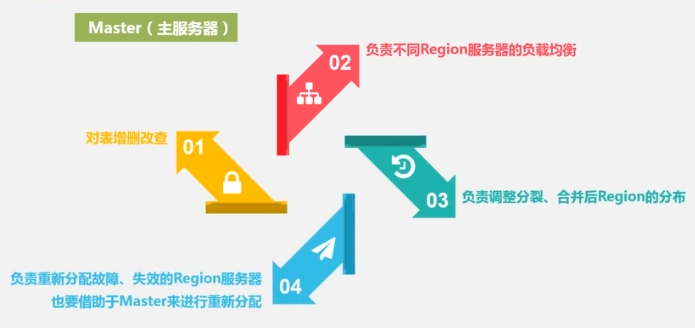
The master server is responsible for:
- Partition information maintenance and management
- Region server list maintenance
- Which Region servers are working and which are being maintained.
- Assign the region server to which the table Region is assigned.
- load balancing
The Region server is responsible for:
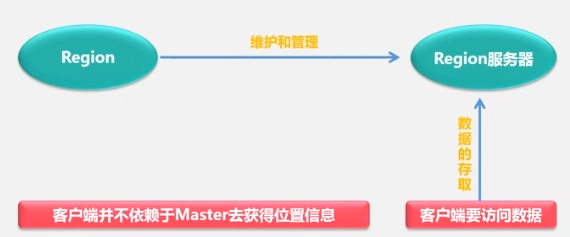
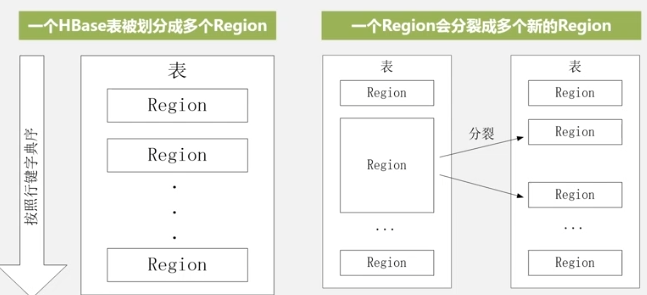
When a table is first created, there is only one Region. When a certain Region of a certain table is too large, it is quickly split, and the data first points to the original address. After the merge is completed, a new file is generated and then points to the new address. Different Regions may be on different Region Servers, but the same Region must be on the same Region Server.
Region positioning

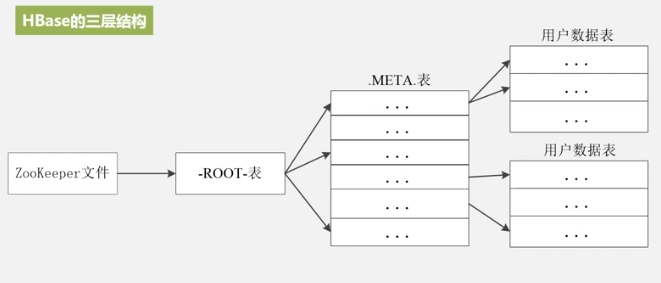
That is, visit the ZooKeeper server to know where the Root table is,
check the Root table to know where the Meta table is stored,
and then check the Meta table to know where the data table is stored.
This is a three-tier structure.
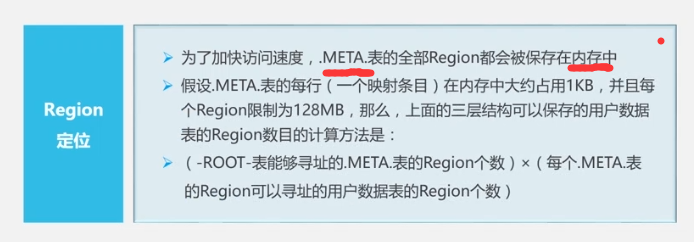
In order to speed up the addressing, the client will cache the location information. At the same time, if the cache invalidation problem occurs, the addressing will be repeated at the third layer.
HBASE operating mechanism
HBASE system architecture
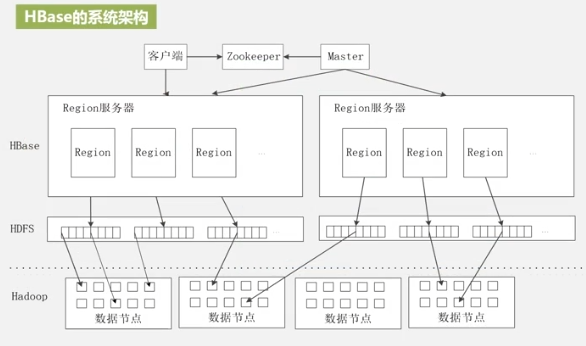
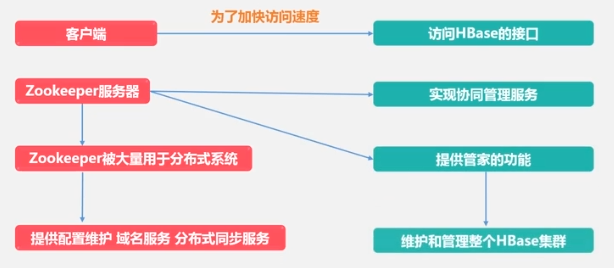
ZooKeeper guarantees that only one main server (Master) is currently running (there may be multiple standbys).
Working principle of Region server
Responsible for the storage and management of user data.

A Region server cluster has 10-1000 Region servers
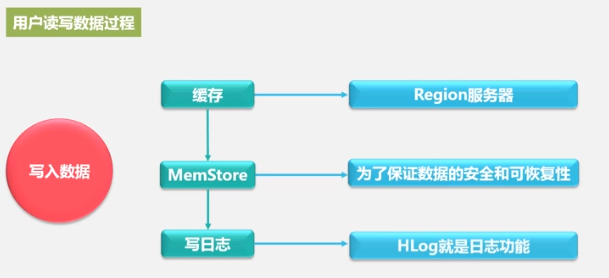
. A Store represents a column family. The Store is first written to MemStore, and then periodically written to StoreFile. StoreFile is the storage format of HDFS and uses HFile for storage.
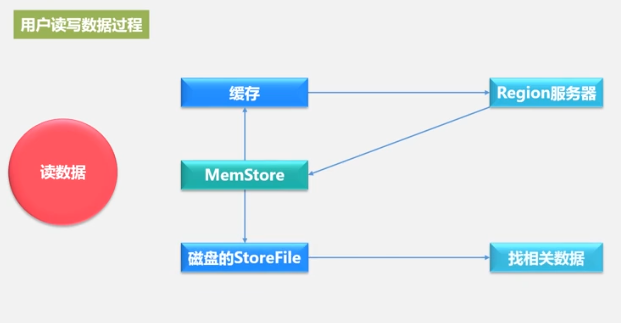
Working principle of store
Store is the column family. Review the physical storage of the column family:
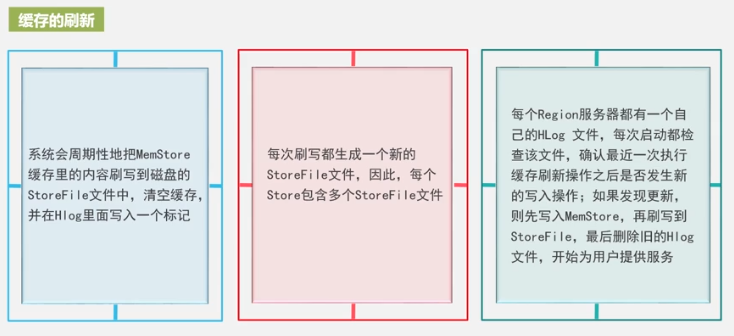
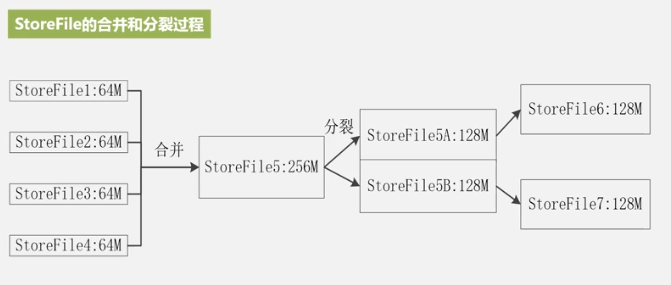
A new storeFile is generated every time. There are too many files, and the traversal is slow, so they are merged, and the files are large, so they are split. This is the reason for the merging and splitting of StoreFiles, as well as the merging and splitting of Regions.
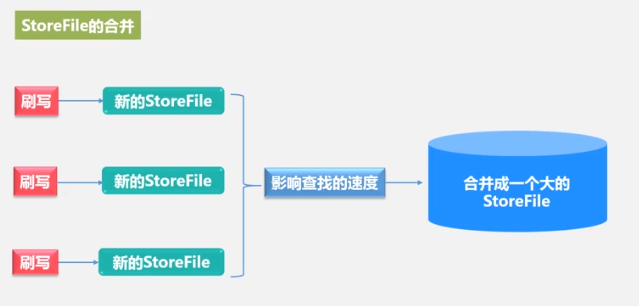
Merging consumes a lot of resources, and it is generally merged when the number of StoreFile files is higher than a certain threshold.
How HLog works
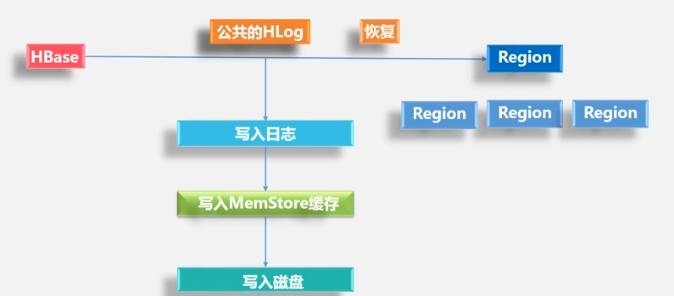
Write to the log first, and then write to the MemStore.
A Region server has multiple Regions, one HLog, and one HLog to ensure high write performance.
HLog Application Solution
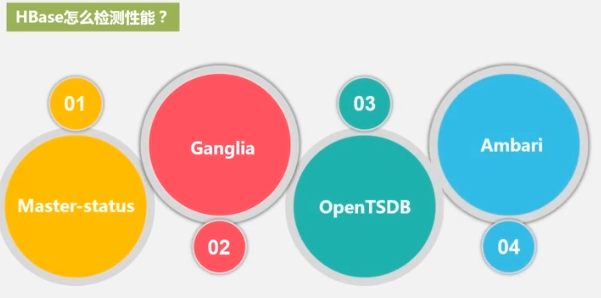
performance optimization
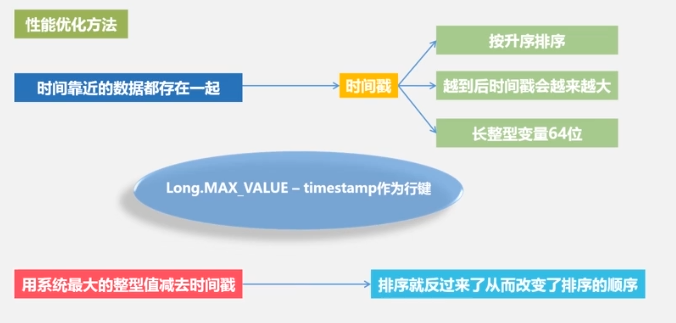
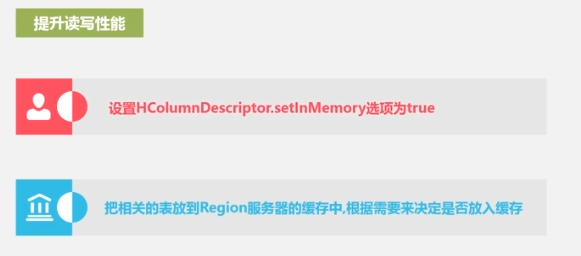

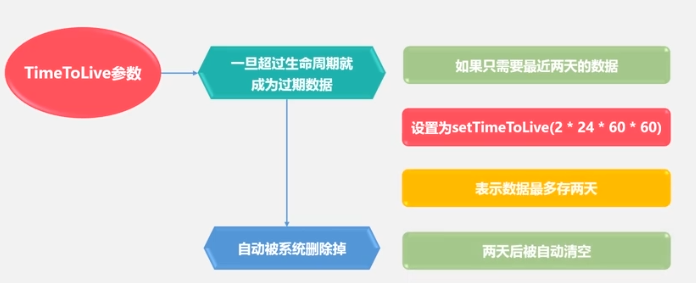
performance testing
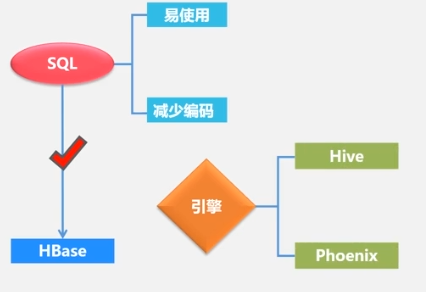
You can use SQL statements to query data on HBase.
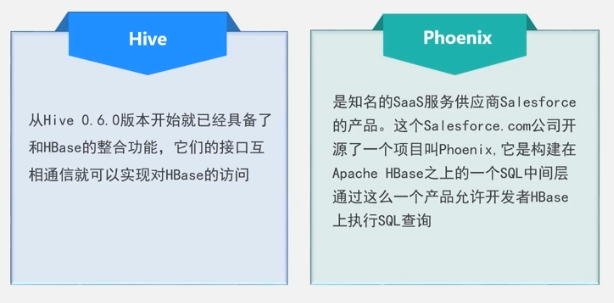
Secondary index:
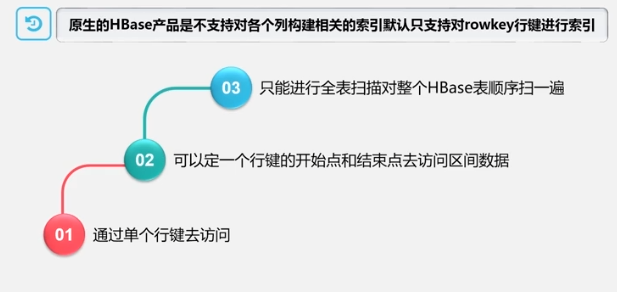
index through the index table (insert the index at the same time when inserting data, insert twice, and performance will decrease)
operate
http://dblab.xmu.edu.cn/blog/2442-2/
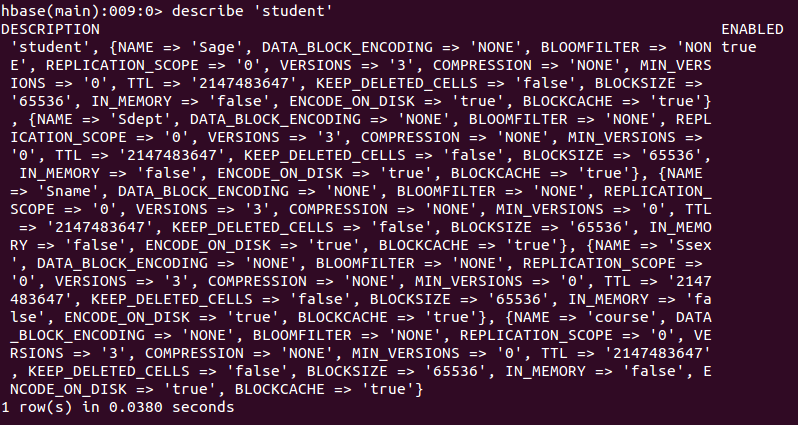
Use the create command to create a table in HBase, as follows:
create 'student','Sname','Ssex','Sage','Sdept','course'

At this point, a "student" table is created with attributes: Sname, Ssex, Sage, Sdept, course. Because there will be a system default attribute in the HBase table as the row key, there is no need to create it yourself, and the default is the first data after the table name in the put command operation. After the "student" table is created, you can run the describe command to view the basic information of the "student" table.
When adding data, HBase will automatically add a timestamp to the added data, so when you need to modify the data, just add the data directly, and HBase will generate a new version to complete the "change" operation, the old version remains Reserved, the system will regularly recycle garbage data, leaving only the latest versions, and the number of saved versions can be specified when creating the table.
- adding data
put 'student','95001','Sname','LiYing'
That is, a row of data whose student ID is 95001 and whose name is LiYing is added to the student table, and its row key is 95001.
put 'student','95001','course:math','80'
That is, a data is added to the math column of the course column family under row 95001.
- delete data
delete 'student','95001','Ssex'
That is, all data in the Ssex column under row 95001 in the student table is deleted.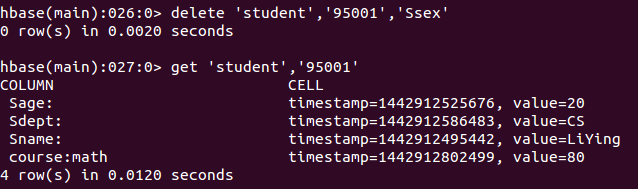
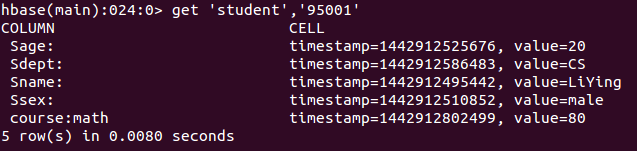
- view data
get 'student','95001'
The screenshot of the command execution is as follows, and the returned data is the row '95001' of the 'student' table.