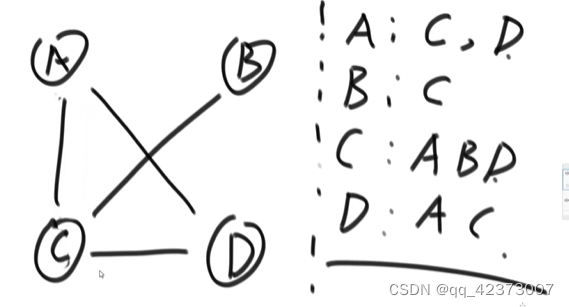
Representation of graphs: adjacency matrix, link table method
The connection table method
can find out how many direct adjacent points there are in the follow-up
1
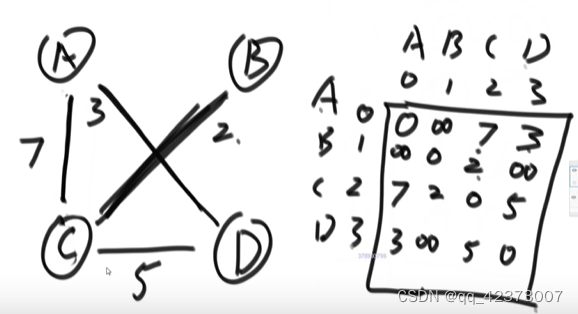
Connecting matrix method, if there are four nodes ABCD, it is represented by 0123 rows and columns, the path from A to A is 0, and there is no path from A to B, which is positive and infinite Advantages: Each edge can be detected Disadvantages: It takes up a lot
of
memory
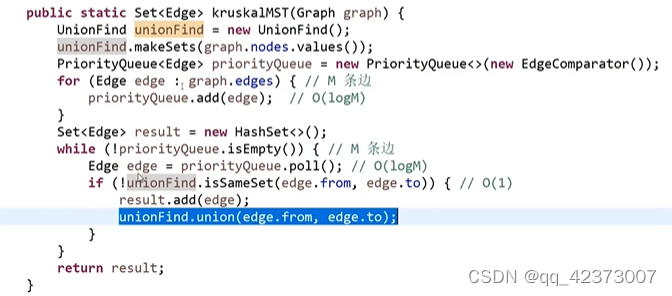
Kruskal's algorithm (minimum spanning tree algorithm), requires an undirected graph
 Prim's algorithm, requiring an undirected graph
Prim's algorithm, requiring an undirected graph
public static class EdgeComparator implements Comparator<Edge>{
@Override
public int compare(Edge o1, Edge o2) {
// TODO 自动生成的方法存根
return o1.weight-o2.weight;//小根堆
}
}
public static Set<Edge> primMST(Graph graph){
//解锁的边进入小根堆
PriorityQueue<Edge> priorityQueue=new PriorityQueue<>(new EdgeComparator());
HashSet<GraphNode> set=new HashSet<>();
Set<Edge> result=new HashSet<>();//依次挑选的边进入result里
for(GraphNode node:graph.graphnodes.values()) {
//随便挑了一个点
//node是开始结点
if(!set.contains(node)) {
set.add(node);
}
for(Edge edge:node.edges) {
//由一个点,解锁所有相邻的边
priorityQueue.add(edge);
}
while(!priorityQueue.isEmpty()) {
Edge edge=priorityQueue.poll();//弹出解锁的边中,最小的边
GraphNode tonode=edge.to;//可能的一个新的点
if(!set.contains(tonode)){
//不含有的时候,就是一个新的点
set.add(tonode);
result.add(edge);
for(Edge nextedge:tonode.edges) {
//再把与tonode相连的边加到优先级队列(小根堆)中去
priorityQueue.add(nextedge);
}
}
}
}
return result;
}

There can be edges with negative weights, but there cannot be rings with negative cumulative sums, and it will keep going
public static HashMap<GraphNode,Integer> dijietesla(GraphNode head){
//从head出发到所有点的最小距离
//key:从head触发到达key,value:从head出发到达key的最小距离
//如果在表中,没有T的记录,含义是从head出发到T这个节点的距离为正无穷
HashMap<GraphNode,Integer> distanceMap=new HashMap<>();
distanceMap.put(head, 0);
//已经求过距离的节点,存在selectdNodes中,以后再也不碰
HashSet<GraphNode> selectedNodes=new HashSet<>();
GraphNode minNode=getMinDistanceAndUnselectesNode(distanceMap,selectedNodes);
if(minNode!=null) {
int distance=distanceMap.get(minNode);
for(Edge edge:minNode.edges) {
GraphNode toNode=edge.to;
if(!distanceMap.containsKey(toNode)) {
distanceMap.put(toNode, distance+edge.weight);
}
distanceMap.put(toNode, Math.min(distanceMap.get(toNode), //从源节点出发到toNode之前的最短路径
distance+edge.weight));//从当前结点往外跳到达toNode找到的一条新路径
}
selectedNodes.add(minNode);//锁定
minNode=getMinDistanceAndUnselectesNode(distanceMap,selectedNodes);
}
return distanceMap;
}
//黑盒,从distanceMap中选择不在选中节点集合selectedNodes里 距离最小的结点和距离
public static GraphNode getMinDistanceAndUnselectesNode(HashMap<GraphNode, Integer> distanceMap,
HashSet<GraphNode> selectedNodes) {
// TODO 自动生成的方法存根
GraphNode minNode=null;
int minDistance=Integer.MAX_VALUE;
for(Entry<GraphNode, Integer> entry :distanceMap.entrySet()) {
//获取每一条记录
GraphNode node=entry.getKey();
int distance=entry.getValue();
if(!selectedNodes.contains(node)&&distance<minDistance) {
//点要是没锁定的,如果距离变得更小了
minNode=node;
minDistance=distance;
}
}
return minNode;
}

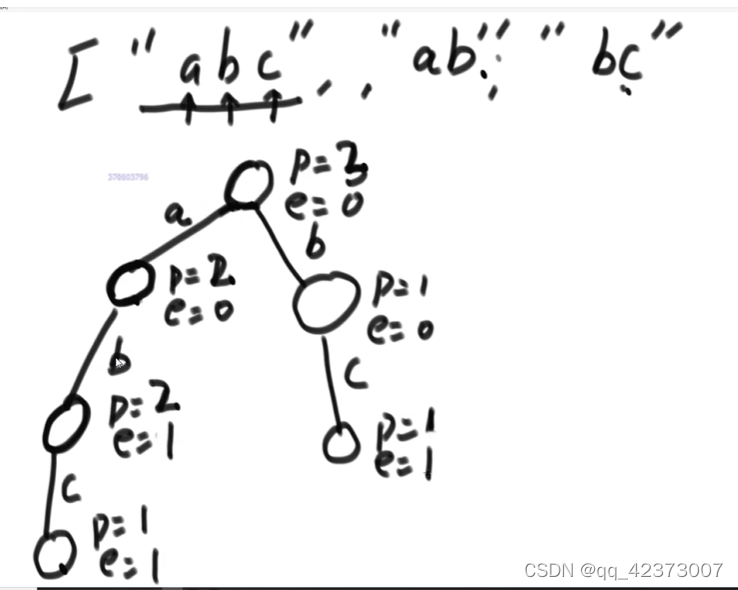
Build a prefix tree, p value ++ along the way, when e reaches the last node ++,
public class QianZhuiTree {
public static class TrieNode{
public int pass;//通过这个节点的次数
public int end;//以这个节点结尾的次数
public TrieNode[] nexts;//HashMap<Char,Node> nexts;
public TrieNode() {
pass=0;
end=0;
//nexts[0]==null,没有走向‘a’的路;nexts[0]!=null,有走向‘a’
//nexts[1]==null,没有走向‘b’的路;nexts[25]==null,没有走向‘z’的路
nexts=new TrieNode[26];
}
}
public static class Trie{
private TrieNode root;
public Trie() {
root=new TrieNode();
}
public void insert(String word) {
if(word==null) {
return;
}
char[] chs=word.toCharArray();
TrieNode node=root;
node.pass++;
int index=0;
for(int i=0;i<chs.length;i++) {
//从左向右遍历字符
index=chs[i]-'a';//由字符决定走那条路
if(node.nexts[index]==null) {
node.nexts[index]=new TrieNode();//如果该结点不存在,则建立结点
}
node=node.nexts[index];//如果已经存在,就移动到这个节点,并把该结点的pass值++
node.pass++;
}
node.end++;//最后一个字符的end++
}
//word这个单词之前加入过几次
public int search(String word) {
if(word==null) {
return 0;
}
char[] chs=word.toCharArray();
TrieNode node=root;
int index=0;
for(int i=0;i<chs.length;i++) {
index=chs[i]-'a';//根据当前字符决定index要走那条路
if(node.nexts[index]==null) {
//这种情况就是我树上有“abc”,但是要查询的是"abcdef",
//这个时候node走完了,字符还没走完,这说明”abcdef“这个字符出现0次
return 0;
}
node=node.nexts[index];
}
return node.end;
}
//所有加入的字符中,有几个是以pre这个字符串作为前缀的
public int prefixNumber(String pre) {
if(pre==null) {
return 0;
}
char[] chs=pre.toCharArray();
TrieNode node=root;
int index=0;
for(int i=0;i<chs.length;i++) {
index=chs[i]-'a';
if(node.nexts[index]==null) {
//如果结点结束了,字符串还没结束,说明有0个
return 0;
}
node=node.nexts[index];
}
return node.pass;如果字符串结束了,结点还没结束,那么最后结点的pass值就是结果
}
public void delete(String word) {
//艳茹跟着走,p---,e值--
if(search(word)!=0) {
//确定树中之前加入过word,才删除
char[] chs=word.toCharArray();
TrieNode node=root;
node.pass--;//一上来node的pass值就--
int index=0;
for(int i=0;i<chs.length;i++) {
index=chs[i]-'a';
if(--node.nexts[index].pass==0) {
//当前结点的下级结点的pass值已经是0了,
//java c++ 要遍历到底去析构
//直接把下级结点标空,然后return
node.nexts[index]=null;
return;
}
node=node.nexts[index];//如果当前结点的下级结点的pass不是0,就继续找下级结点,让他的pass值--
}
node.end--;//记得把end值--
}
}
}
}
Greedy algorithm


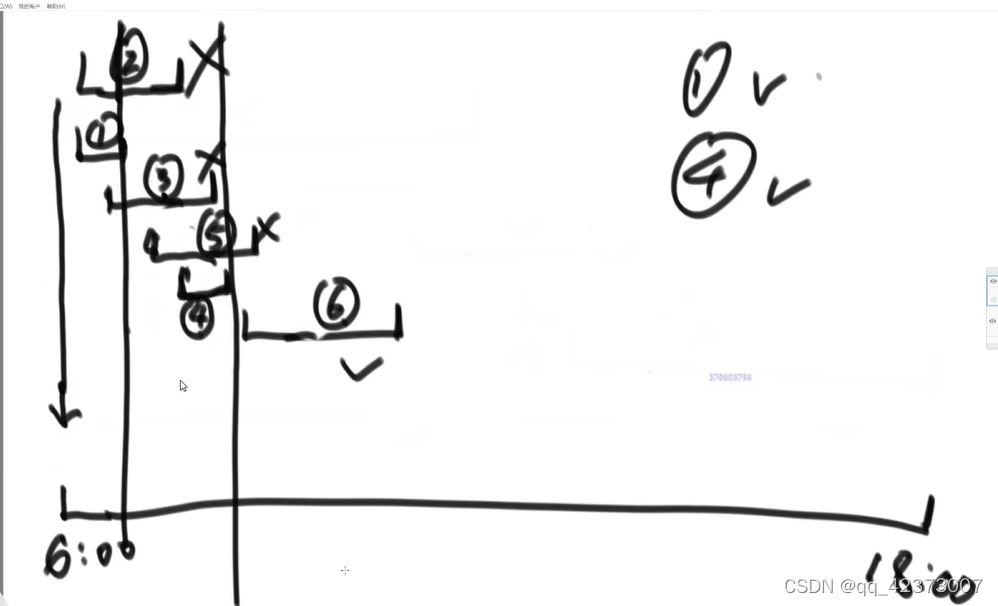 topic 7 code
topic 7 code
public class TanXin {
public static class Program{
public int start;
public int end;//每个项目都有一个开始时间和结束时间
public Program(int start,int end){
this.start=start;
this.end=end;
}
}
public static class ProgramComparator implements Comparator<Program>{
@Override
public int compare(Program p0, Program p1) {
// TODO 自动生成的方法存根
return p0.end-p1.end;
}
}
public static int bestArrange(Program[] programs,int timePoint) {
//timePoint指目前来到的时间点
Arrays.sort(programs, new ProgramComparator());//以项目对象中的结束时间来排序
int result=0;
//从左往右一次遍历所有的会议
for(int i=0;i<programs.length;i++) {
if(timePoint<=programs[i].start) {
//当前来到的时间点有没有早于选中会议的开始时间
result++;//如果早于,安排的会议++
timePoint=programs[i].end;//然后时间点来到这个会议结束的时候
}
}
return result;
}
public static void main(String[] args) {
Program p1=new Program(7,11);
Program p2=new Program(7,10);
Program p3=new Program(9,14);
Program p4=new Program(11,16);
Program p5=new Program(12,16);
Program p6=new Program(16,18);
Program[] programs= {
p1,p2,p3,p4,p5,p6};
int res=bestArrange(programs,6);
System.out.println(res);
}
}
Use a logarithm to verify whether the greedy algorithm is right.
How to decide who to choose first and then who to choose: make a full array and try violently (the written test will definitely fail, and the time will be stuck)
123
Prove that the greedy algorithm is correct from the beginning to the end
. Given an array with strings in it, what you have to do is to concatenate these strings, but make their lexicographical order the smallest. Sorting and splicing
according to their respective lexicographical order , this strategy is wrong, because for ["ae", "bc", "ck"], the row is ae<bc<ck, and the splicing is "aebcck", but for ["ba", "b" ], b<ba, after splicing is "bba", but there is still a minimum "bab"
that needs to define an effective comparison strategy, not all comparison strategies are valid

public class ZiDianXu {
public static class MyComparator implements Comparator<String>{
@Override
public int compare(String a, String b) {
// TODO 自动生成的方法存根
return (a+b).compareTo(b+a);//字典序升序的方式
}
}
public static String lowestString(String[] strs) {
if(strs==null||strs.length==0) {
return "";
}
Arrays.sort(strs,new MyComparator());
String res="";
for(int i=0;i<strs.length;i++) {
res+=strs[i];
}
return res;
}
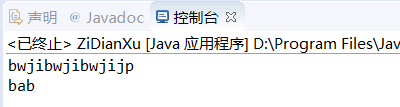
public static void main(String[] args) {
String[] strs1= {
"jibw","ji","jp","bw","jibw"};
System.out.println(lowestString(strs1));//bwjibwjibwjijp
String[] strs2= {
"ba","b"};
System.out.println(lowestString(strs2));//bab
}
}
According to the test results,
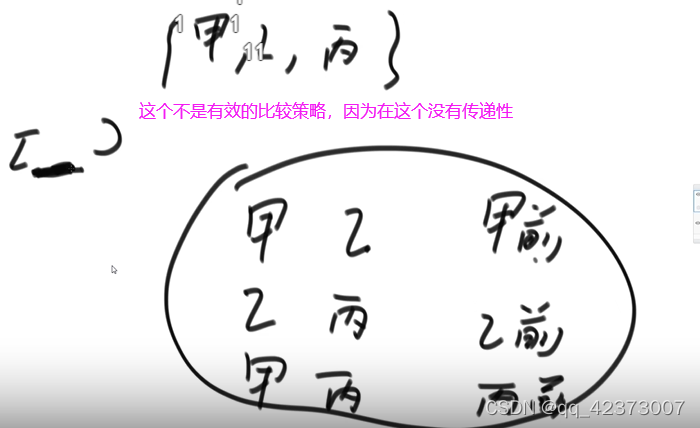 it is only effective if A and B meet A before discharge, B and C meet B and before A and C meet A and release
it is only effective if A and B meet A before discharge, B and C meet B and before A and C meet A and release

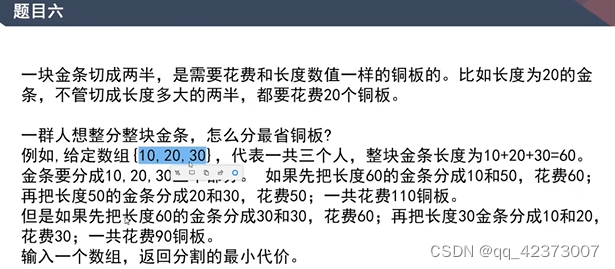
/*感觉代码有问题,MinheapComparator没用上*/
public class LessMoneySplitGold {
public static class MinheapComparator implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
// TODO 自动生成的方法存根
return o1-o2;
}
}
public static int lessMoney(int[] arr) {
PriorityQueue<Integer> pq=new PriorityQueue<>();
for(int i=0;i<arr.length;i++) {
pq.add(arr[i]);
}
int sum=0;
int cur=0;
while(pq.size()>1) {
cur=pq.poll()+pq.poll();
sum+=cur;
pq.add(cur);
}
return sum;
}
}