Paper Address
Code Address: No
Paper Name: MobileVOS: Real-Time Video Object Segmentation Contrastive Learning meets Knowledge Distillation
Summary
This paper studies the problem of semi-supervised video object segmentation on resource-constrained devices such as mobile phones. We model the problem as a distillation task, through which we show that small spatiotemporal memory networks with limited memory can achieve results comparable to state-of-the-art, but at a fraction of the computational overhead (per frame 32 ms). Specifically, we provide a theoretically grounded framework that unifies knowledge distillation with supervised contrastive representation learning . These models can jointly benefit from pixel-level contrastive learning and distillation from pre-trained teachers . We validate this loss by achieving competitive J&F on the standard DAVIS and YouTube benchmarks, where it runs 5x faster with 32x fewer parameters.
introduction
Background : Memory-based methods are popular in semi-supervised video segmentation tasks, but memory networks often have a trade-off between memory usage and accuracy. At the same time, there is no method in the literature that can execute in real time on mobile phones and preserve the latest results.
Our approach : This paper focuses on memory-based networks and sets out to bridge the gap between infinite and finite memory networks, which is achieved through knowledge distillation.
(1) This paper proposes a pixel-wise representation distillation loss that aims to transfer structural information from a large, infinite memory teacher to a smaller, limited memory student.
(2) A simple boundary-aware sampling strategy is used, which improves training convergence
(3) This paper provides a natural generalization to achieve a supervised pixel-level contrastive representation objective.
(4) Using ground truth labels as another venue for structural information, we use hyperparameters to interpolate between representation distillation loss and contrastive learning loss as a unified loss .
Contribute :
(1) This paper combines knowledge distillation and supervised contrastive learning to design a new representation-based loss , which bridges the gap between large infinite memory models and small limited memory models. Furthermore, this paper demonstrates that a simple boundary-aware pixel sampling strategy can further improve the results and model convergence.
(2) Using this unified loss, this paper demonstrates that a general network design can achieve results comparable to state-of-the-art network designs, while running up to 5 times faster and with up to 32 times fewer parameters than before.
(3) Without complex architecture or memory design changes, the loss proposed in this paper can unlock real-time performance (30FPS+) on mobile devices (Samsung Galaxy S22) while maintaining competitive performance with state-of-the-art.
method
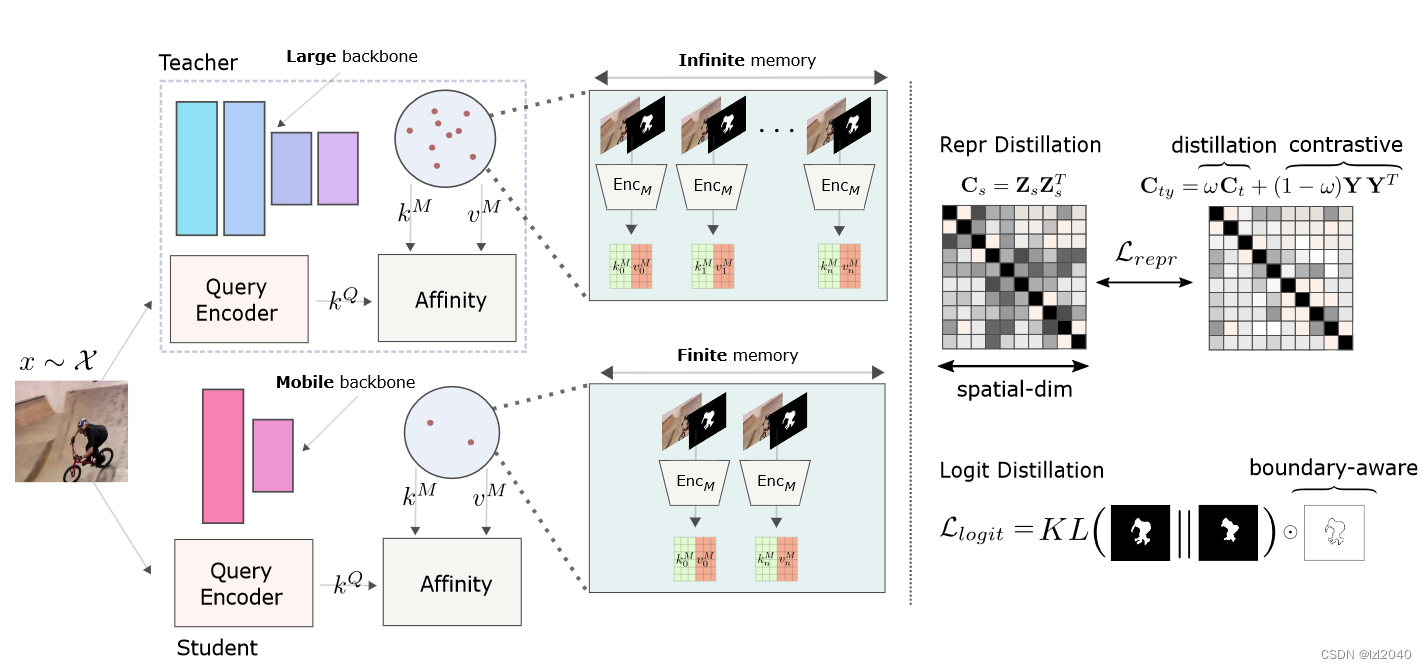
Explanation: The teacher model utilizes unlimited memory, while the student model only retains the memory of the image and mask of the previous and first frame. Since the teacher has more memory, the task of distillation is to learn consistent features across multiple frames . An auxiliary goal of contrastive representation learning is to encourage discriminative pixel-level features near object boundaries .
Representation Distillation
This paper uses the obtained representation before the last fully connected layer, and a large amount of structural information that is conducive to knowledge transfer may be lost earlier.
Specifically, this paper proposes a pixel-wise representation distillation loss that can transfer structural information between these two models. In order to extract structural information, we propose to construct correlation matrices: Cs, Ct, whose dimensions are all HW*HW, respectively from the student model and the teacher model, and these two matrices can capture the relationship between all pixel pairs . The formula is as follows:

where Zs, ZT denote the representation obtained by the L2 normalized student model and teacher model of d dimension provided before the final pointwise convolution and upsampling layer .
Inspired by [1], the resulting final loss function is as follows: the

two components of this loss can be interpreted as a regularization term, and a correlation alignment between the two models, while the log2 operator is used here to improve the Robustness to spurious correlations . It is equivalent to maximizing the pixel-level mutual information between student and teacher representations.
The distillation loss function is: (this is actually a special case of the above loss, which will be described later)

where H2 and I2 are based on matrix estimators, which are similar to Renyi entropy and 2nd-order mutual information. References: [2]
This is through Derived, more can be seen in the appendix of the paper.
Unification with contrastive learning
Problem : The effectiveness of knowledge distillation depends on the relative capability gap of the student and teacher models. As the capability gap narrows, the size of this training regime becomes small .
Existing conclusions : Using self-supervision as an auxiliary task can improve conventional distillation
Solution : (1) First construct another target tube incidence matrix:
![]()
where Y is the spatially downsampled, one-hot encoded label containing 2 categories (object and background).
(2) Couple the two target correlation matrices to provide a method for interpolation between the two training modes:

where Cty can be substituted into the above Lrepr loss function.
When considering the representation Z and w=0, the Lrepr loss function becomes supervised contrastive learning:

where Sim is the cosine similarity between two independent pixels in the representation, and Pi is the set of positive indices for the ith pixel.
Discussion on w:

When w=0, it degenerates into a supervised contrastive loss; when w=1, it degenerates into a distillation loss. Not saying equal, just equivalent.
Boundary-aware sampling
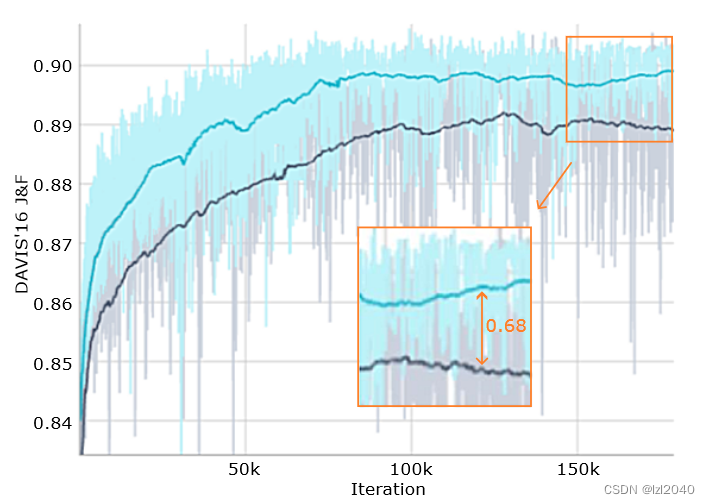
Existing problems : (1) Most of the prediction errors occur on the boundary of the object. The figure below shows the verification accuracy of the two models trained with random pixel and boundary pixel sampling strategies, and black is randomly sampled.
(2) The calculation of constructing the correlation matrix for all pixels is too large
Solution : Propose to sample only pixels near the object boundary.
Benefits : This sampling strategy restricts the distillation gradient to only flow through pixels that cause downstream prediction errors , while also making the formula more computationally efficient; this modification can improve the overall convergence of the model.
Logit distillation
An additional KL divergence term is introduced in the logit space between the two models:

pS, pT are the probabilities predicted by the student and teacher models respectively, parameterized with a temperature term τ to soften (τ > 1) or sharpen ( τ<1) for both predictions. The only difference from traditional logit distillation is that this paper only uses pixels around or near object boundaries.
The final loss is:

The pseudocode is:

experiment
related settings
For all experiments, we train the student as a teacher with an additional linear embedding layer and use a pretrained STCN [3] .
The student model has made some modifications to STCN: the value encoder is replaced by MobileNetV2, and the query encoder is replaced by ResNet18; at the same time, the ASPP module is used before the decoder; we choose a fixed memory queue length of 2, and when the queue is full, follow First in first out principle.
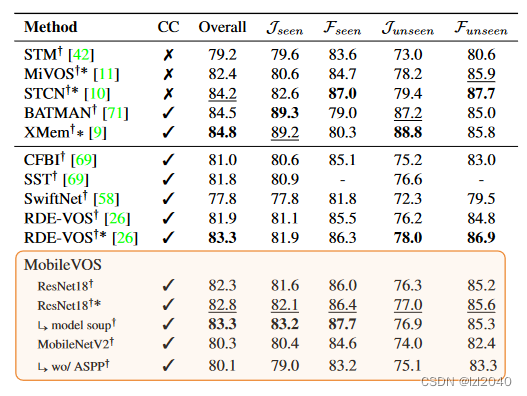
Experimental results
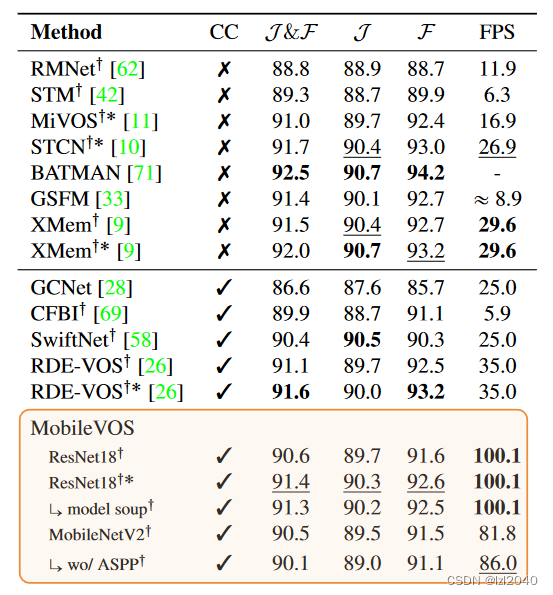
On DAVIS2016, the best model is only 0.3 J&F lower than STCN and 0.2 J&F lower than RDE-VOS, but runs 4x and 3x faster than them . It's really fast, reaching 100FPS, and the accuracy hasn't dropped much.
On DAVIS2017, our model is only slightly worse than the STCN teacher model by 0.3 J&F. However, this paper is nearly 5x and 4x faster than STCN and RDE-VOS .
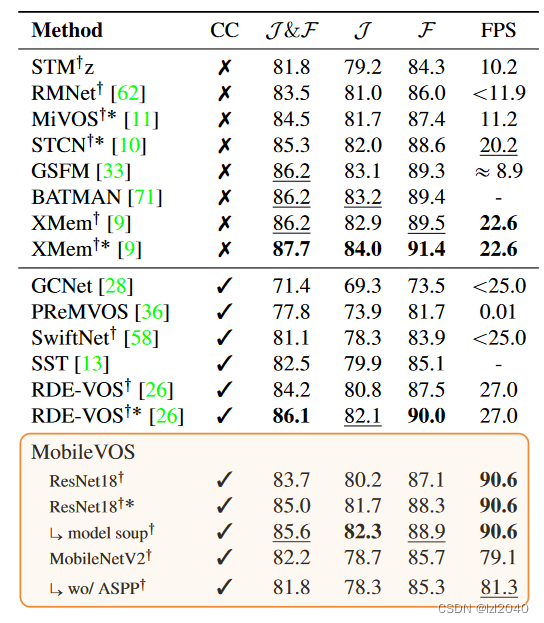
At YouTube2019, our method outperforms RDE-VOS without BL30K pre-training and is competitive with it. Instead of RDE-VOS training different loss weights for YouTube evaluation to avoid overfitting on unseen classes, we show predictions using the same set of weights as for DAVIS evaluation.
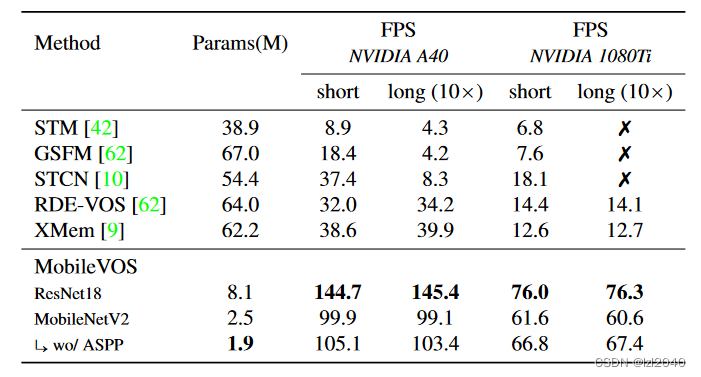
In terms of model size and inference speed, the MobileVOS model in this paper is significantly smaller, while maintaining constant low latency in short and long videos:
in conclusion
In this work, we propose a simple loss that combines knowledge distillation and contrastive learning . By applying this loss in the context of semi-supervised video object segmentation, we achieve results that compete with the state-of-the-art results at a fraction of the computational cost and model size . These models are compact enough to fit on standard mobile devices while preserving real-time latency.
references
[1]Roy Miles, Adrian Lopez Rodriguez, and Krystian Mikolajczyk. Information Theoretic Representation Distillation. BMVC, 2022. 3, 13
[2]Luis G. Sanchez Giraldo and Jose C. Principe. Information theoretic learning with infinitely divisible kernels. ICLR, 2013. 3
[3]Ho Kei Cheng, Yu-Wing Tai, and Chi-Keung Tang. Rethinking space-time networks with improved memory coverage for efficient video object segmentation. NeurIPS. 1, 2, 5, 6, 7, 12