Article Directory
foreword
Hello everyone, I am Kongkong star. In this article, I will share with you how to recognize text in pictures through Python's pytesseract library.
Relevant versions of the software used in this article:
macOS 11.6.5
Python 3.8.9
pytesseract 0.3.10
Pillow 9.4.0
1. pytesseract
1. What is pytesseract?
Pytesseract is a Python OCR library that recognizes text in images and converts it into text form. Pytesseract is based on Google's Tesseract OCR engine, which has high accuracy and reliability. It can read pictures in various formats, including PNG, JPEG, GIF, etc. Pytesseract can be applied in natural language processing, data mining, OCR recognition and other fields.
2. Install pytesseract
pip install pytesseract
3. Check the version of pytesseract
pip show pytesseract
Name: pytesseract
Version: 0.3.10
Summary: Python-tesseract is a python wrapper for Google’s Tesseract-OCR
Home-page: https://github.com/madmaze/pytesseract
Author: Samuel Hoffstaetter
Author-email: [email protected]
License: Apache License 2.0
Requires: packaging, Pillow
Required-by:
4. Install PIL
The Pillow library is a Python image processing library, which is used by pytesseract to process images.
pip install pillow
5. Check the PIL version
pip show pillow
Name: Pillow
Version: 9.4.0
Summary: Python Imaging Library (Fork)
Home-page: https://python-pillow.org
Author: Alex Clark (PIL Fork Author)
Author-email: [email protected]
License: HPND
Requires:
Required-by: image, imageio, matplotlib, pytesseract, wordcloud
2. Tesseract OCR
1. What is Tesseract OCR?
Tesseract OCR is an open source OCR (Optical Character Recognition, optical character recognition) engine, which can recognize and convert the text content in the image into an editable text format. It was originally developed by HP Labs and is now maintained and updated by Google. Tesseract OCR supports more than 100 languages, including Chinese, English, French, German, etc. It can run on a variety of operating systems, including Windows, Linux, macOS, and more. Tesseract OCR is widely used in digital documents, automated data entry, intelligent search, etc.
2. Install Tesseract OCR
Under macOS:
brew install tesseract
3. Install the Tesseract OCR language pack
Under macOS:
brew install tesseract-lang
3. How to use
1. Import library
import pytesseract
from PIL import Image
2. Open the picture file
img = Image.open("demo.png")
3. Use Tesseract for text recognition
text = pytesseract.image_to_string(img, lang='chi_sim')
4. Output recognition results
print(text)
Left: Original image
Right: Screenshot of recognized text
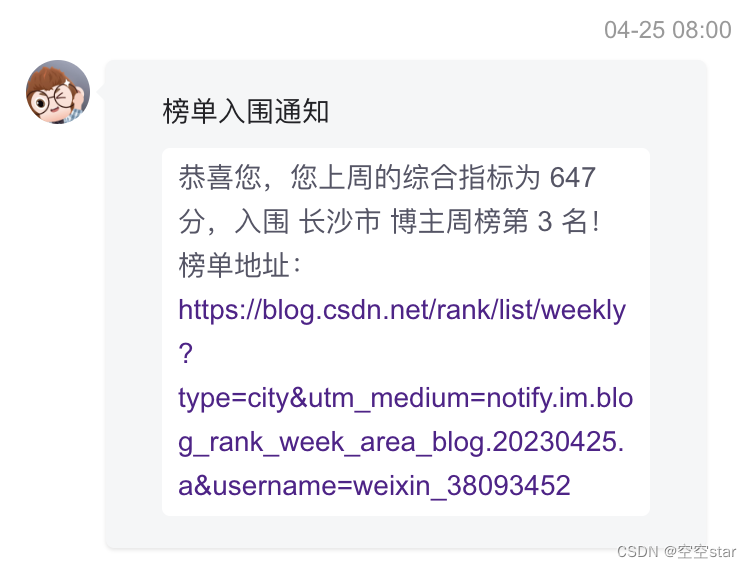

Summarize
image_to_stringis a Python function, which is provided by the tesseract OCR engine. The function of this function is to convert the text in an image into a string, that is, to recognize the text in the image and convert them into a string format that the computer can process. This function can accept images in various formats, such as JPEG, PNG, BMP, etc. Before using this function, you need to ensure that the tesseract OCR engine has been installed.