Article Directory
1. Propose a task
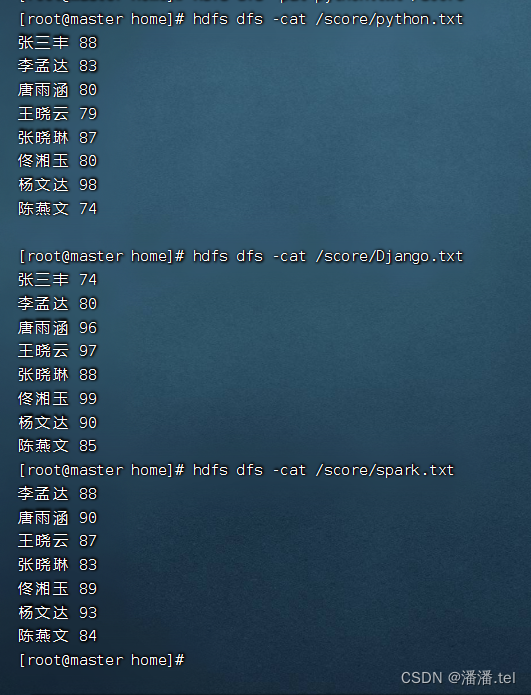
Spark score table-spark.txt
张三丰 94
李孟达 88
唐雨涵 90
王晓云 87
张晓琳 83
佟湘玉 89
杨文达 93
陈燕文 84
Python score table-Python.txt
张三丰 88
李孟达 83
唐雨涵 80
王晓云 79
张晓琳 87
佟湘玉 80
杨文达 98
陈燕文 74
Django score table - Django.txt
张三丰 74
李孟达 80
唐雨涵 96
王晓云 97
张晓琳 88
佟湘玉 99
杨文达 90
陈燕文 85
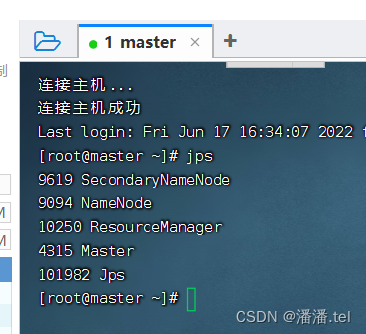
Preparatory work: start the cluster and Spark
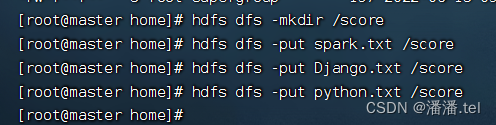
Create a new /score directory on HDFS

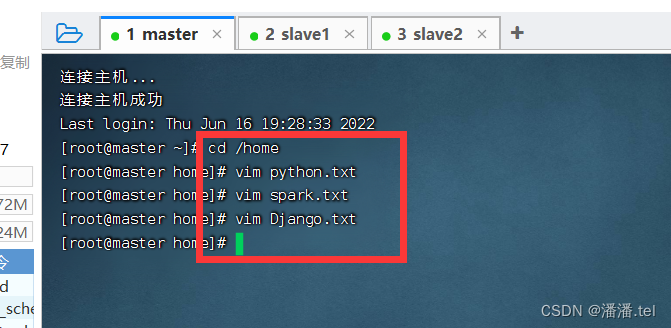
Create three grade files on the master virtual machine
Upload the three score files to the /score directory of HDFS
View the content of the three score files
2. Complete the task
(1) Create a new Maven project
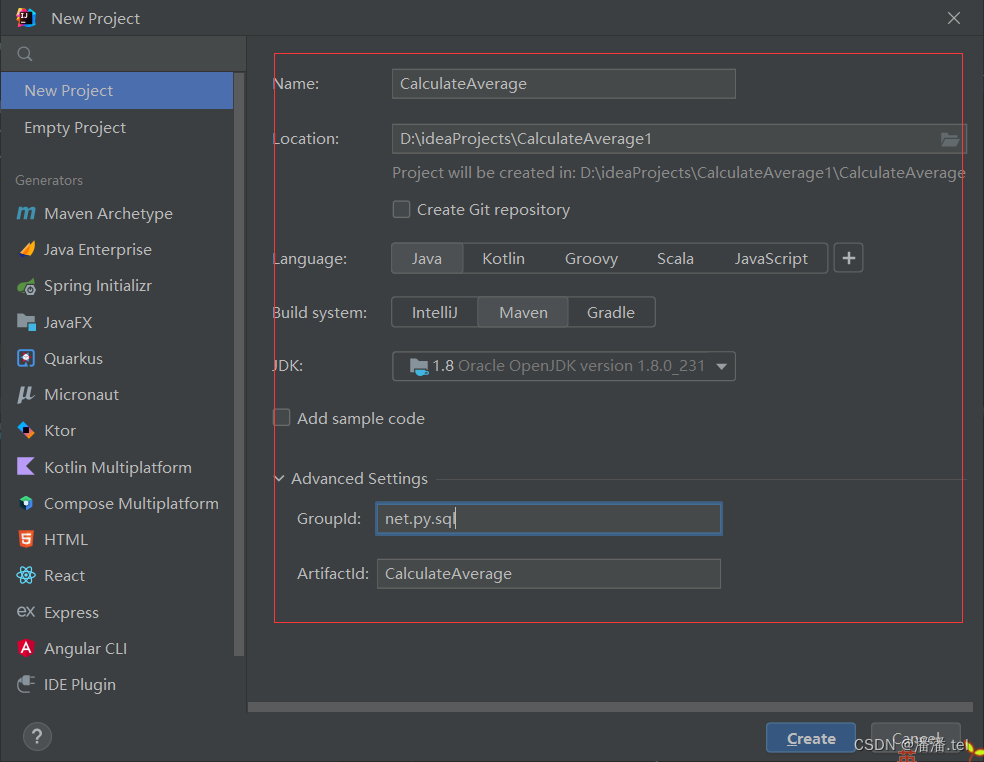
Change the Java directory to Scala
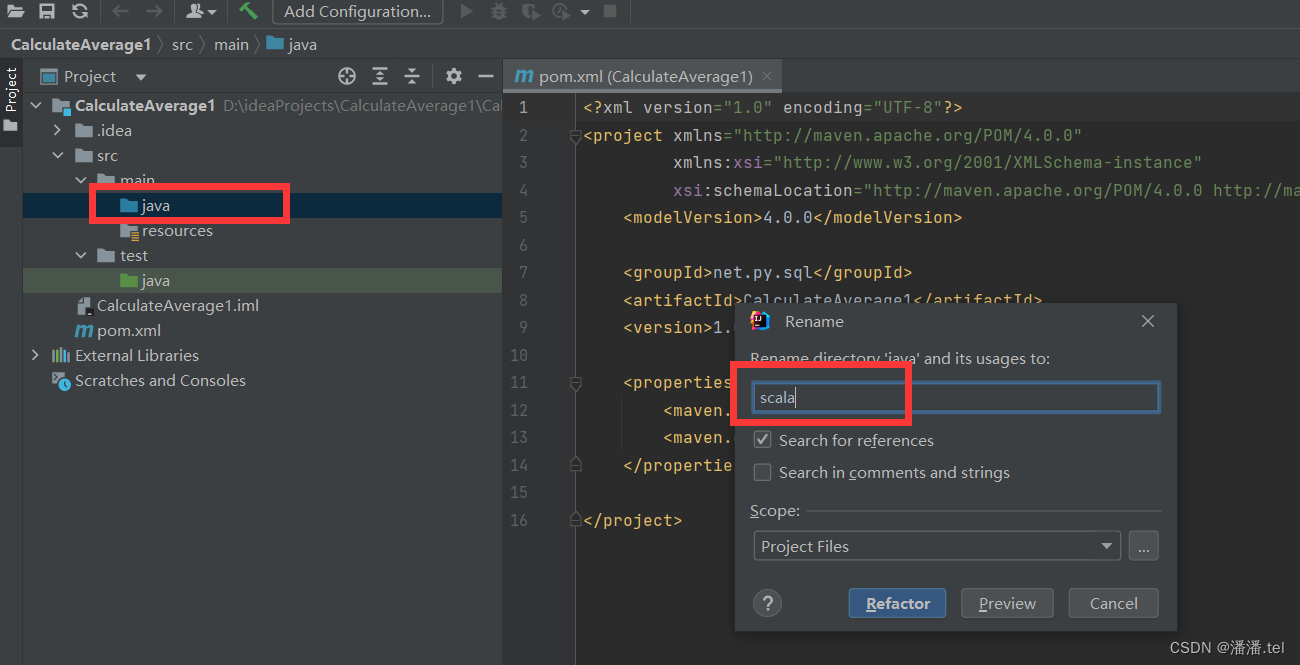
(2) Add related dependencies and build plug-ins
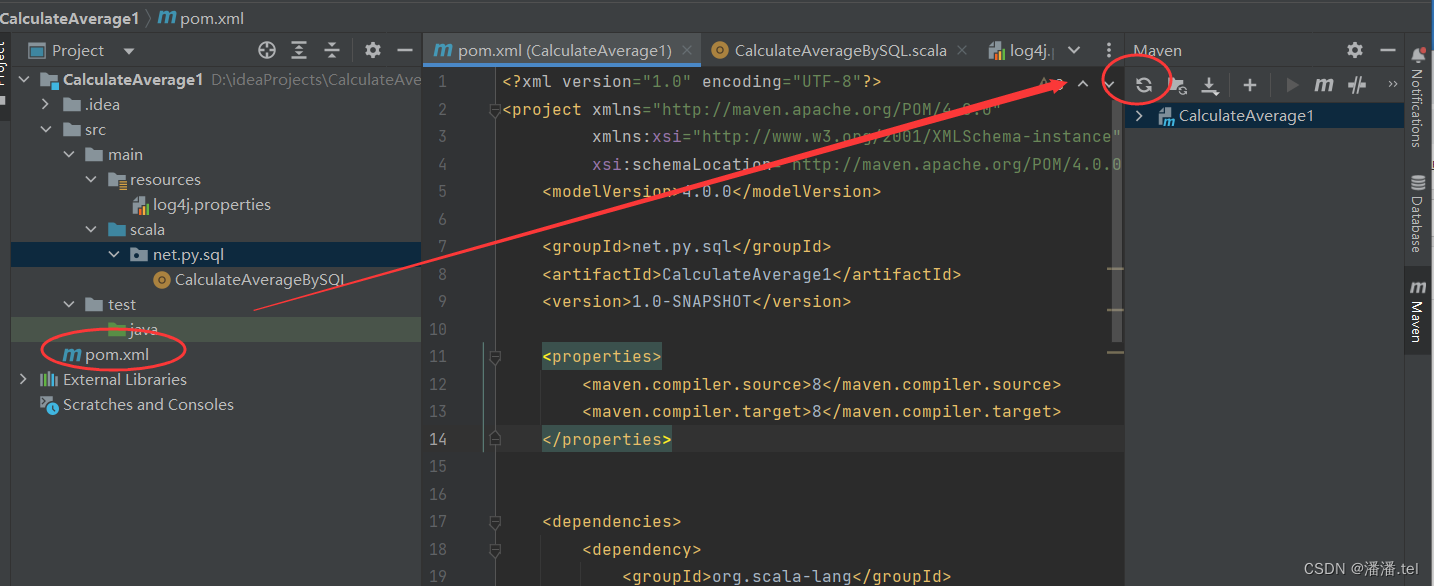
(3) Create a log property file
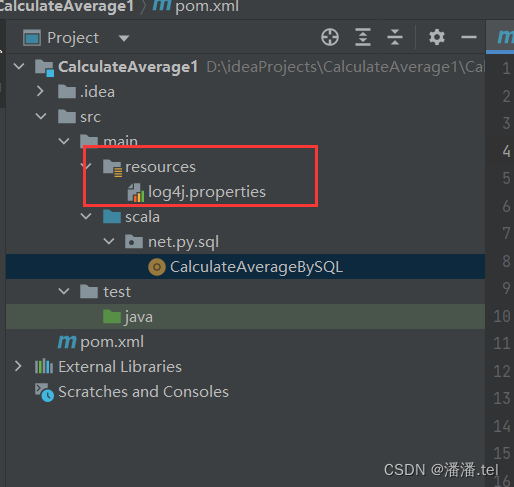
(4) Create a singleton object for calculating the average score
(5) Run the program locally and view the results
1 张三丰 81.33
2 李孟达 88.67
3 唐雨涵 92.67
4 王晓云 85.00
5 张晓琳 86.67
6 佟湘玉 82.33
7 杨文达 82.00
8 陈燕文 94.33