SODA
2022_cite=12_Cheng——Towards large-scale small object detection: Survey and Benchmarks
https://shaunyuan22.github.io/SODA/
Small object detection = small object detection = SOD
-
Datasets:
-
SODA-D: OneDrvie; BaiduNetDisk
-
SODA-A: OneDrvie; BaiduNetDisk
-
-
Codes
The official codes of our benchmark, which mainly includes data preparation and evaluation, are released below.
-
SODA-D Benchmark: SODA-mmdetection
-
SODA-A Benchmark: SODA-mmrotate
The article is only hung on arxiv, and has not been published in conferences or journals.
(1) This paper first reviews the classic small target recognition algorithms in the field of SOD and the development and evolution of SOD technology. (2) Then this article introduces two data sets SODA-A air scene and my SODA-D driving scene that I released for SOD tasks.
What is the current level of research in the field of small target detection?
Even for state-of-the-art detectors, the performance of detecting small objects still lags behind that of normal-sized objects. Taking one of the state-of-the-art detectors DyHeadas an example , DyHeadthe obtained index COCOfor small objects on the test-dev set mAPis only 28.3%, which is significantly behind the results for medium and large objects (50.3% and 57.5%, respectively).
Challenges in SOD tasks
The difficulties in the general task of target detection, of course, the target detection of small targets will also encounter, such as intra-class variations, inaccurate localization, and occluded object detection in target detection. Of course, these are not the key points in SOD tasks, the key point is the unique challenges of SOD
scarcity,
(1)Scarcity for large-scale dataset tailored for Small Object Detection
(1) There are still not many large-scale data sets dedicated to small target detection, and they are relatively scarce-this paper discloses two large-scale data sets dedicated to SOD, so you don't have to worry about this problem, it has been solved .
Some data sets tailored for small target detection that have been proposed by the academic community include the following, (1) SODand TinyPerson. However, because the scale of their data sets is too small, it cannot meet the needs of the CNN model for the amount of data. (The amount of data is too small, and there is not enough parameter fitting, so the model trained in this way has poor generalization ability and is useless)
Some public datasets contain more small objects, such as WiderFace, , andSeaPerson . DOTAUnfortunately,
[1] These data sets are either designed for two-category detection tasks (face detection - face detection is a face or not a face or pedestrian detection is a pedestrian or not a pedestrian), usually following a relatively certain pattern ( The recognition model only needs to judge whether the small target is elliptical in shape like a human head, and the upper part of the ellipse on the pattern is a little dark brown; for pedestrian recognition, it only needs to judge whether the shape of the object looks like a distorted large character. Such a small target feature extraction The machine cannot learn any valuable features, just judge directly according to the shape).
[2] or where tiny objects are only distributed in a few categories. For example, in the DOTA dataset, most of the small targets are small vehicles. Objects of other categories simply do not have objects of smaller size. Then the model cannot learn a variety of features to judge the category of this small target, but will directly associate the size with the corresponding category. For example, if you brought a small target, I don’t need to extract it from the picture of the small target. For any feature, I directly judge that this small target is a small vehicle, so the accuracy rate is high, but our small target extractor did not learn any valuable features, that is to say, our small target detection feature extractor is in Training on this dataset failed.
In a nutshell, we hope to train a practical data set with the following characteristics. We hope that the number of small targets in the data set should be as large as possible, and they should be relatively evenly distributed in multiple categories. In this way, we can evaluate the SOD algorithm score on multiple categories, and optimize this score, and finally enable the trained small target recognition model to extract diverse features of various categories, and then achieve better performance in multiple categories. Nice assortment.
Features of the dataset collected by the authors
SODA-D - Driving Scenario. It includes 24,000 high-quality traffic maps and 270,000 instances in 9 categories . This data set is a fusion of two data sets, one is MVDthe public data set, and the other is the data set collected by the author himself. The MVD dataset is a dataset dedicated to pixel-level understanding of street scenes. The dataset collected by the authors themselves was filmed with in-vehicle cameras and mobile phones. Then the author carefully selected the pictures in the two fused data sets, and only selected pictures of driving scenes with high quality and many small targets.
SODA-A - Air flight scene. It includes 2.5K high-resolution aerial images and annotates 800,000 instances across 9 categories . This picture is a high-resolution image extracted by the author from the software Google Earth
This dataset is the first attempt at large-scale benchmarking in academia. The above two data sets are tailor-made for multi-category SOD (specifically for the scene of small objects, a lot of special operations have been done on the labeling; the selection of pictures is also specially selected for the smaller objects, the size very few large targets) a large number of annotated instances.
At the same time, the author tested the most mainstream small target detection methods in the current academic circle on the two data sets proposed by the author, and evaluated the performance of these SOD algorithms.
The feature extractor for small target recognition, the extracted features are of low quality , for the following three reasons
(2) Information loss caused by sub-sampling Information loss caused by downsampling
- Downsampling causes information loss - In the backbone backbone network, this feature extractor uses downsampling. The original intention of this downsampling is to
-
Objects with relatively large sizes : It is appropriate to use downsampling in the feature extractor. For objects with large sizes, their information is sufficient, and the loss of this information loss will not bring about a significant decrease in the accuracy of their recognition. At the same time, in the process of downsampling, some high-dimensional features of pictures can be extracted, which brings information gain, so adding downsampling to the feature extractor will improve the accuracy of recognition.
-
Objects with relatively small sizes : Downsampling will bring the following negative effects. In the process of downsampling, the size of the feature map becomes smaller, that is, the spatial resolution of the feature map is reduced (the original small picture becomes more blurred). Before downsampling, the small target itself has a small area on the photo, and after downsampling, the size becomes even smaller. The object size of a small object is relatively small, the number of pixels itself is less than that of a large object, and the information transmitted is naturally less. Some information, which was originally a small number, was further lost in the process of downsampling. The less information, the lower the recognition score
(3) Noisy feature representation noise feature representation
A lot of noise itself : Small objects usually have low-resolution and low-quality appearance, so it is difficult tolearn feature representations of small object images for feature extraction by distinguishing their distorted structures .
The surrounding things introduce some noise : the regional features of small objects are easily polluted by the background and other instances , further introducing noise to the learned feature representation.
The extracted features are of low quality, and a lot of noise is mixed in. Naturally, garbage in, garbage out, the final performance can be good!
(4) Low tolerance for bounding box perturbation (disturbance) low tolerance for disturbance of the recognition box
This challenge is mainly aimed at the definition step in the recognition process, and has nothing to do with the classification step.
Localization, as one of the main tasks in detection, is formulated as a regression problem in most detection paradigms.
The positioning branch is designed to output the bounding box offset or the target size (what does the previous one refer to? You said or, which one is it?), usually the intersection ratio union (IoU) is used to evaluate the accuracy. (You tell me how you use IoU to evaluate, write the evaluation process below and how to do it, you can check it, and write below) However, it is more difficult to locate small targets than large ones.
A slight deviation (by 6 pixels along the diagonal direction) of the object's predicted box leads to a significant drop in IoU (by 67.5%). Meanwhile, larger variance (say, 12 pixels) further exacerbates the situation, and the IoU drops to 8.7% for small objects. That is, small objects are less tolerant to bounding box perturbations than larger objects, exacerbating the learning of the regression branch.
The small target itself is small, and the same amount of concession is made, but the loss of I accounts for a larger proportion of U in the size of the small target. Why because the base is small. It is equivalent to the same numerator (an absolute amount of the offset/error of the same recognition frame), the smaller the denominator (the smaller the object size), the more precision is lost
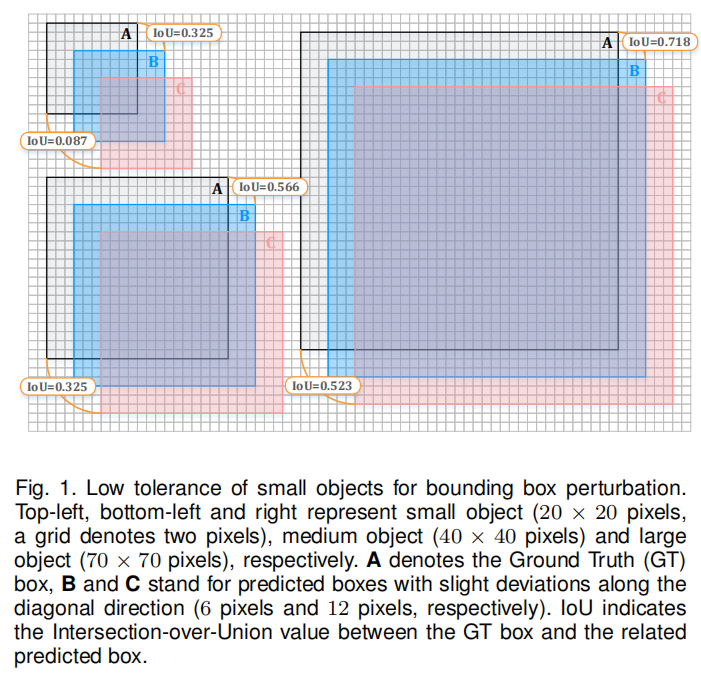
What does the picture above mean, let me explain
In the grid below, one grid represents 2 pixels, and the size of the small target in the upper left corner is 20×20 pixels. The size of the medium target in the lower left corner is 40×40 pixels, and the size of the large target on the right is 70×70 pixels
The targets of these three sizes are all composed of a black frame, a blue square shadow and a red square shadow. The black box indicates Ground Truth, and the B box and the C box are both predicted boxes. It's just that frame B is shifted 6 pixels to the right and down compared to frame A, and then frame C is shifted 6 pixels to the right and down on the basis of frame B.
Note that here is a control variable. The three targets move in the same direction twice, and the moving pixel values are the same as 6 pixels. The only difference between the three and a half targets is their size. Here we will investigate, how much will the classification error increase after the recognition frame is cheaper than the same number of pixel values for objects of different sizes? The classification error here is roughly represented by (1-IoU). The reason I said this is that since IoU represents the part of positioning, isn't 1-IoU the part of the wrong classification?
| IoU |
||
| 6 pixels lower right |
12 pixels lower right |
|
| big |
0.718 |
0.523 |
| middle |
0.566 |
0.325 |
| Small |
0.325 |
0.087 |
| Lost accuracy due to recognition frame offset (1-IoU) |
||
| 6 pixels lower right |
12 pixels lower right |
|
| big |
0.282 |
0.477 |
| middle |
0.434 |
0.675 |
| Small |
0.675 |
0.913 |
The recognition box is offset by 6 pixels to the bottom right, and the accuracy of large object loss is 28.2%. Medium-sized objects lose more accuracy, 43.4% (1.54 times the loss of large objects). The accuracy loss for small targets is even greater at 67.5% (2.39 times that of the largest targets)
If you shift more pixels to the bottom right, then small objects still lose more precision than large objects
The recognition frame is shifted to the bottom right by 12 pixels, and the accuracy loss of large objects is 47.7%; the accuracy loss of medium objects is more than that of large objects, which is 67.5%; the accuracy loss of small objects is more than that of medium objects, which is 91.3%
In order to solve the above three problems, in order to solve these three problems, the solutions proposed by the academic community can be summarized into six categories: 数据操作方法, 尺度感知方法, 特征融合方法, 超分辨率方法, 上下文建模方法and 其他方法.
-1-Data Manipulation
(The effect is not good) - the default will be used
Problem address : Micro-sized objects only account for a very small part of the current dataset , and large-sized objects dominate the entire dataset. This has led to the fact that in the process of training the model, the model focuses on improving the recognition accuracy of large-size samples, and the task of small-size object recognition has not been effectively and fully trained. Naturally, the performance of small-size sample recognition is better than that of large-size samples. Much worse. This phenomenon is called Data imbalance at the target scale level.
Solution : The most direct solution to this problem is to increase the number of small-sized targets in the training set , which can encourage the detector to better optimize the recognition performance of small-sized targets by increasing positive samples.
Limitation : The difference in the data size of the data set and the different degree of balance of the object size of the sample in the data set will lead to different improvements and degrees of improvement brought by this functional method on different data sets , inconsistent performance improvement between datasets of different volumes. In other words, your method may improve performance a lot on some datasets (the scale of the sample object is extremely unbalanced), but if you switch to another dataset (the scale of the sample object itself is quite balanced), the performance improvement is very limited. . In general, the transferability of this method is not very good. How much you can improve the accuracy of your model using this method depends largely on the data set you are using. The performance gain obtained by the manipulation-based methods is dataset-dependent
-1.1-Oversampling-based augmentation strategy
Enhancement strategy based on oversampling
Kisantaladopted an enhancement strategy by duplicating a small object and pasting the copied small object at different locations in the same image with random transformations .
RRNetIntroduced an adaptive augmentation strategy AdaResamplingcalled , which follows the same philosophy as Kisantal. Its main improvement is that in the sample process, (1) use the "prior segmentation map" (I don't know what it is? Leave it alone) to determine the most suitable position to paste valid positions. (2) We will make a scale transformation on the size of the pasted object. For example, there are fewer small targets in this picture, so we will reduce the size of the pasted object, so that the small size of the target will be smaller. More, the sample becomes balanced. On the contrary, when pasting the pasted object, increase the size. The advantage of this is that it can further weaken the sample imbalance of the target scale size
Yolov4In , a new data augmentation strategy is proposed Mosaicto augment raw data, which stitches multiple (eg 4) images into a new sample. Since the original image is usually downscaled to a smaller size, this operation improves the number of small objects in practice.
-1.2-Automatic augmentation scheme
Methods following this paradigm explore the optimal combination of several predefined augmentation strategies . Zoph et al. believe that off-the-shelf augmentation techniques borrowed from classification tasks make little contribution to detection, so they model the augmentation process as a discrete optimization problem and find the best combination of preset augmentation operations .
To this end, an efficient search technique based on reinforcement learning is utilized to explore optimal parameters . However, searching in such a large search space is computationally expensive. To mitigate this, Cubuk et al. jointly optimize ( ??? ) all operations using only a single distortion magnitude, while keeping the probability parameters consistent.
-2-Scale-aware methods split according to the size of the target
Both multi-level representations and specific training schemes strive for consistent performance gains for both small and medium-sized objects . However, the divide-and-conquer paradigm of mapping objects of different sizes to corresponding scale levels may confuse the detector (is it mapped to the same scale?), since a single layer is not informative enough to make accurate predictions ( huh?? Where is the monolayer? Predict what?). On the other hand, custom mechanisms for facilitating multi-scale training often introduce extra computation , hindering end-to-end optimization.
-2.1-Multi-scale detection in a divide-and-conquer fashion分而治之
Introduction : Use the target detector corresponding to the scale to identify the features at different depths or levels of different depths and levels. Divide and conquer, objects with extremely small size are recognized by special "very small" target detectors; objects with a small scale are recognized by special "small" target detectors. The task of recognition is divided into subtasks of multiple scales, and each object detector is responsible for one scale.
HyperNetPut forward such an assumption: RoIthe information of the region of interest ( ,Regin of Interest) is distributed on all layers of the backbone network. Since it is distributed in many places, the RoI information requires you to organize it well. Based on this assumption, in order to integrate and capture the RoI information distributed in various places on the backbone, the author connects the "coarse-to-fine" feature features of concatenate and compress, and finally integrates a Hyper Feature. This Hyper Feature retains some information about the reasoning and judgment of the target, Hyper Features retains the reasoning of small objects. (What does it have to do with small targets??)
Yang makes full use of scale-dependent pooling (SDP) to select the appropriate feature layer proper feature layer for subsequent small target pooling operation for subsequent pooling operation.
MS-CNNIn different intermediate layers at different intermediate layers, generate candidate area recommendations generates object proposals, each of which focuses on the objects within certain scale ranges , each of which focuses on thee objects within certain scale ranges, so that the small target The receptive field reaches the optimal enabling the optimal receptive field for small objects. .
Liu invented Single Shot MultiBox Detector( SSD) to detect small objects on high-resolution feature maps. (What is SSD, it is written in the terminology explanation) The SSD algorithm combines the prediction of multiple feature maps with different resolution sizes, which is beneficial to deal with multi-scale targets.
DSFD(Dual Shot Face Detector) The task of this algorithm is to recognize faces of different sizes to detect the faces of various scales. This model uses a two-shot detector. two-shot detector (should be translated into a dual-branch network, the author also calls the model a dual shot detector, the entire network is serialized by two sub-networks, one sub-network is called a shot, and together they are called two shot or dual shot) The connected by feature enhancement module is used to connect the shots . DSFD is composed of parallel double-prediction branches. Both branches are used for prediction in the training phase, while only the second branch (feature enhancement branch) is used in the test phase. Why use dual branches? The author mentioned that the first prediction branch can be regarded as a kind of auxiliary supervision, which makes the features more suitable for face detection (personal understanding: the first branch can be regarded as a feature constraint).
https://blog.csdn.net/silence2015/article/details/106268010/
—————After here, I haven’t read the original English text of the paper———————
YOLOv3Multi-scale prediction is performed by adding parallel branches , where high-resolution features are responsible for small objects . Construct multi-level feature pyramids to detect objects.M2Det
Furthermore, combining scale detectors for multi-scale detection has been extensively explored. Li et al. build parallel sub-networks in which small sub-networks are specially learned to detect small pedestrians . SSHMultiple face detectors are trained, and each face detector uses face pictures of a certain scale range for training. For example, this detector trains a face with a length and width of 20 pixels, and another detector trains a face with a length and width of 10 pixels. Detector. These detectors are put together to form a multi-scale detector, which is used to deal with face datasets with greatly varying scales.
TridentNetA parallel multi-branch architecture is constructed, where each branch has the best receptive field for objects of different scales . Inspired by the great success of region-level feature aggregationPANet in , Zhang et al. concatenate multiple deep (Region of Interest) pooled features with global features to obtain more robust and discriminative representations for small objects. A cascade query strategy is designed (what is this? It doesn't matter, just forget it) , which avoids redundant calculation of low-level features and makes it possible to efficiently detect small targets on high-resolution feature maps.RoIQueryDet
-2.2-Tailored training schemes Customized training
Based on the consensus that multi-scale training and testing can improve the performance of detectors , methods following this roadmap aim to develop customized data preparation strategies during training . Based on the general multi-scale training scheme, Singh et al. design a novel training paradigm, scale normalization ( SNIP) of the image pyramid, which only adopts the instances whose resolution falls into the scale range required for training, and the rest are taken by Simply ignore. With this setting, small objects can be handled within the most reasonable range without affecting the detection performance for medium and large objects .
Later, Sniper suggested sampling from multi-scale image pyramids for efficient training. Najibi et al. proposed a coarse-to-fine pipeline to detect small objects . Considering that the collaboration between data preparation and model optimization has not been fully explored in previous methods, Chen et al. design a feedback-driven training paradigm to dynamically guide data preparation and further balance the training loss for small objects . Yu et al. introduced a statistics-based matching strategy to achieve scale consistency .
-3-Feature-fusion methods
Deep CNN architectures produce hierarchical feature maps of different spatial resolutions, where low-level features describe finer details and more localization cues , while high-level features capture richer semantic information . Due to the presence (use) of subsampling layers (which should be downsampling modules), the responses of small objects may disappear in deeper layers. Another solution is to exploit shallow features to detect small objects . Although good for localization, early feature maps are susceptible to variations in illumination, deformation, and object pose, making the classification task more challenging. To overcome this dilemma, the more popular method is to use feature fusion to integrate features from different layers or branches to obtain better feature representations for small objects .
-3.1-Top-down information interaction Top-down information interaction
Inspired by the pyramid structure used in the era of handcrafted features, FPNworks such as et al. construct a top-down path to strengthen the interaction between shallow and deep layers , enabling high-resolution representations to simultaneously have rich semantic information and refinement for small objects. Localization . Shrivastava et al. introduce top-down modulation ( TDM) networks, where top-down modules learn the semantics or context that should be preserved , and lateral modules transform low-level features for subsequent fusion.
Lin et al. propose a feature pyramid network ( FPN), where features with high-resolution but low-level semantics are aggregated with features with low-resolution but high-level semantics . This simple yet effective design has become an important part of feature extractors.
To alleviate the lack of localization in the one-way pyramid architecture, the feature hierarchy is enrichedPANet by two-way paths , and deeper features are enhanced by accurate localization signals.
Zand et al DarkNet-53. skip-connectionbuilt on and DarkNet-RI(that is, these two techniques combined) to generate high-level semantic feature maps at different scales .
-3.2-Refined feature fusion Refined feature fusion
Despite the success of top-down information interaction, basic interaction design is not perfect due to the inability of basic upsampling and fusion to handle the inherent scale inconsistency. Observing this, the following methods aim to refine the features at different stages from the backbone in an appropriate way (what are features at different stages from the backbone?), or optimize the fusion process by dynamically controlling the information flow between different layers .PANet
Wu et al. proposed the use of deconvolution to enlarge the feature map , StairNetwhich learning-based up-samplingcan achieve kernel-based up-samplingfiner features than other pyramids and allow information from different pyramids to spread more efficiently.
Introduced by Liu et al IPG-Net., a set of images of different resolutions obtained by the image pyramid is input into the designed transformation module , and shallow features are extracted to supplement spatial information and details.IPG
Gong et al. designed a statistically based fusion factor to control the information flow in adjacent layers . Note that gradient inconsistencies encountered in methods FPNbased degrade the representational power of low-level features
SSPNet Highlight scale-specific features at different layers , and exploit the relationship of adjacent layers in L to achieve proper feature sharing .FPN
Feature fusion methods can bridge the spatial and semantic gap between lower pyramid levels and higher levels . However, due to the scale-based pyramid assignment strategy, small objects are usually assigned to the lowest pyramid feature (highest spatial resolution) in the current detection paradigm , which creates computational burden and redundant representation in practice . Furthermore, the information flow within the network is not always conducive to the representation of small objects . The authors' goal is not only to endow low-level features with more semantics, but also to prevent the raw responses of small objects from being swamped by deeper signals .
-4-Super-resolution methods make small targets clear through super-resolution technology
A straightforward way to enrich the information of small objects is to increase the resolution of the input image through bilinear interpolation and super-resolution networks . However, interpolation-based methods, as a local operation, often fail to capture global understanding and suffer from mosaic effects . This situation can get worse for objects of extremely limited size.
Furthermore, the authors hope that the manipulation can recover the distorted structure of small objects , rather than simply amplifying their blurry appearance. To this end, some attempted methods super-resolve input images or features by borrowing off-the-shelf techniques from the super-resolution field. Most of these methods employ generative adversarial networks ( GANs ) to compute high-quality representations that are beneficial for small object detection , while others opt for parametric upsampling operations to enlarge features .upscaling
Constrained upsampling - using
Interpolation --- very vague
TransConv uppooling
-4.1-Learning-based upscaling
Blindly increasing the scale of the input image will lead to performance saturation and non-negligible computational cost in the feature extraction stage . To overcome this difficulty, methods along this line prefer to super-resolution feature maps. They usually utilize learning-based upsampling operations to improve the resolution of feature maps and enrich the structures . On SSDtop of , DSSDa deconvolution operation is employed to obtain high-resolution features specialized for small object detection. Zhou et al. and Deng et al . explored subpixel convolutions for efficient upsampling.
-4.2-GAN-based super-resolution frameworks.
Goodfellow et al. proposed that GANs generate visually realistic data by following a two-player minimax game between the generator and the discriminator. Unsurprisingly, this capability has inspired researchers to explore this powerful paradigm for generating high-quality representations of small objects . However, directly performing super-resolution on the entire image will increase the burden of feature extractors in terms of training and inference .
To mitigate this overhead, MTGAN use the Generator Network Parser patch . Bai et al. extended this paradigm to the task of face detection, and Na et al. applied super-resolution methods to small proposals for better performance. Although super-resolution object patches can partially reconstruct the blurry appearance of small objects , this scheme ignores contextual cues that play an important role in network prediction . To address this problem, Li et al. designed to mine and exploit the intrinsic correlation between small-scale and large-scale objects , where the generator learns to map weak representations of small objects to super-resolution representations to fool the discriminator . To go a step further, Noh et al. introduced direct supervision to the super-resolution procedure .RoIPerceptualGAN
Due to the limited size, the signal of small objects is inevitably lost after feature extraction , making the subsequent RoI pooling operation almost impossible to compute the structural representation. By mining the intrinsic correlation between small-scale objects and large-scale objects, the super-resolution framework allows to partially recover detailed representations of small objects . However, both learning-based upscaling methods and GAN-based methods must maintain a balance between heavy computation and overall performance . Furthermore, GAN-based methods tend to create false textures and artifacts, which negatively affect detection . Worse, the existence of super-resolution architectures complicates end-to-end optimization .
-5-Context-modeling methods
Humans can effectively exploit the relationship between environment and objects or between objects to facilitate object and scene recognition . This prior knowledge capturing semantic or spatial associations is called context context , which transfers evidence or clues beyond the target region . Contextual information is not only crucial in the human visual system, but also in scene understanding tasks such as object recognition, semantic segmentation, and instance segmentation . Interestingly, information context can sometimes provide more decision support than the target itself , especially when it involves identifying objects with poor viewing quality. To this end, several approaches exploit contextual cues to enhance the detection of small objects.
Chen et al. adopted a representation of contextual regions containing proposed patches for subsequent recognition . Hu et al. study how to efficiently encode out-of-object regions and model local contextual information in a scale-invariant manner to detect tiny faces. PyramidBoxTake advantage of contextual cues to find small, blurry faces that are indistinguishable from the background (determining that the blurry blob is a human face). The intrinsic correlation of objects in an image can likewise be viewed as context . Re- detect objects with low confidenceFS-SSD using implicit spatial context information, i.e., the distance between intra-class instances and between-class instances (ah? What do you mean?). Assuming that the original W will destroy the structure of small objects , a context-aware W is introduced to maintain contextual information . Global contextual features are computed through 2 4-way structures to better detect small and heavily occluded objects .RoI 池化操作SINetRoI 池化层IONetIRNN
From the perspective of information theory, the more types of features considered, the more likely it is to obtain higher detection accuracy . Inspired by the consensus, contextual priming has been extensively studied to generate more discriminative features, especially for small objects with insufficient cues , leading to precise recognition.
Limitation : Unfortunately, either overall context modeling or local context priming confuses which regions should be encoded as context . In other words, current context modeling mechanisms determine context regions heuristically and empirically, which cannot guarantee that the constructed representations are sufficiently interpretable for detection.
-6-Others
Attention-based methods
Humans can quickly focus and distinguish objects through a series of partial glimpses of the entire scene, while ignoring those unnecessary parts , and this amazing ability in our perceptual system is often called the visual attention mechanism. It plays a vital role. Not surprisingly, this powerful mechanism has been extensively studied in the previous literature and shows great potential in many vision domains. By assigning different weights to different parts of the feature map, attention modeling indeed emphasizes valuable regions while suppressing those that are dispensable . Naturally, one can deploy this superior scheme to highlight small objects in images that tend to be dominated by background and noise patterns.
Pang et al. employ global attention blocks to suppress false detections and efficiently detect small objects in large-scale remote sensing images. An oriented object detectorSCRDet is designed , where pixel attention and channel attention are trained in a supervised manner to highlight small object regions while removing the distraction . Using the proposed extended detector , the features of different pyramids are balanced , and the learning of small objects in complex situations is enhanced . FBR-Netlevel-based attentionanchor-freeFCOS
Localization-driven optimization
Localization, as one of the main tasks in detection, is formulated as a regression problem in most detection paradigms. However, the regression objective adopted cannot be reconciled with the evaluation metric (i.e., IoU) . And this optimization inconsistency can hurt the performance of the detector, especially on tiny objects . With this in mind, there are several approaches aimed at equipping local branches with IoU awareness or seeking appropriate metrics.
TinaFace A branch was added to , resulting in a simple but powerful baseline for small face detection. Observing that the IoU metric changes drastically due to slight shifts of tiny object prediction boxes, Xu et al. proposed a new metric, , to alleviate this situation. Also, normalized distance is introduced to optimize the locality metric .RetinaNetDIoUDot DistanceNWD Wasserstein
Density analysis guided detection
Small objects in high-resolution images are often distributed unevenly and sparsely, and general sub-detection schemes consume too much computation on these empty blocks, resulting in low inference efficiency. Can we filter out those non-target regions, thereby reducing useless operations to improve detection? The answer is yes! Efforts in this field break down the common pipeline chain for processing high-resolution images by first abstracting out regions containing objects and then performing detection on these regions. Yang et al. propose a cluster detection network ( ClusDet), which makes fullchips use of the semantic and spatial information between objects to generate clusters and then detect them. Following this paradigm, both Duan et al. and Li et al. utilize pixel- level supervision for density estimation , obtaining more accurate density maps that can well characterize the distribution of objects .
Other issues
Some experimental strategies employ interesting techniques from other fields to better detect small objects. Arguing that traditional annotation approaches can introduce bias and ambiguity , Song et al. propose a novel topological annotation for pedestrians that allows more precise localization on small-scale instances using the proposed somatic topological line localization (TLL) . Similar to super-resolution methods, Wu et al. employ the proposed simulated loss to bridge the gap between the regional representations of small pedestrians and large pedestrians . Inspired by the memory process of the human visual understanding mechanism, Kim et al. designed a new framework for small-scale pedestrian detection based on memory learning.
What model is used for evaluation
AP (Average Precision) for evaluation indicators
The mmdetection package used by the code uses the mmdetection package used by the code, and the mmrotate package is also used
https://github.com/open-mmlab/mmrotate
SDOA-D
SDOA-A

Mainly look at the following codes, whether they can be used in my thesis
Does the model used in the following two data sets appear in mmdetection and mmrotate?
SDOA-D mmdetection
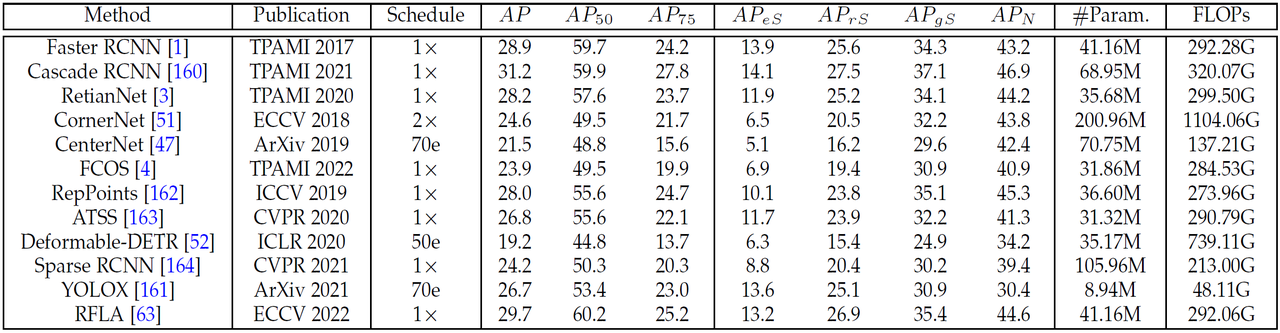
有的:Faster RCNN、Cascade RCNN、RetinaNet、CornerNet、CenterNet、FCOS、RepPoints、ATSS、Deformable-DETR、Sparse RCNN、YOLOX
No: RFLA
SDOA-A mmrotate
有的:Rotated Faster RCNN;Rotated RetinaNet;RoI Transformer;Gliding Vertex;Oriented RCNN;S2A-Net;Oriented RepPoints;
None: DODet; DHRec
Go to the config files of the two repos to see if there is any provision for which model to call? —— sodaa-benchmarks.andsodaa-benchmarks
SDOA-D, file location: https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/sodad-benchmarks, in addition to RFLA this code has
SDOA-A, file location: https://github.com/shaunyuan22/SODA-mmrotate/tree/main/configs/sodaa-benchmarks, except DODet; DHRec, all have
-
Faster RCNN——[1]:S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” TPAMI,vol. 39, no. 6, pp. 1137–1149, 20
——faster- rcnn is a classic of the two-stage detection algorithm
——It feels like RCNN has made some changes to make the real-time performance better
——It is not designed for small target recognition, it is a general target recognition model
——There are https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/faster_rcnn in mmdetection
-
Cascade RCNN——[160] J. Han, J. Ding, J. Li, and G.-S. Xia, “Align deep features for oriented object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
——It is not designed for small target recognition, it is a general target recognition model
——There are https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/cascade_rcnn in mmdetection
-
RetinaNet——[3]T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for ´ dense object detection,” TPAMI, vol. 42, no. 2, pp. 318–327, 2020.
——It is a one-stage network, and it is the first time that a one-stage network surpasses a two-stage network
——The problem solved in this article is dense object detection. The meaning of dense here is not the recognition of extremely small target targets in dense scenarios. Dense refers to the number of sampled image regions (or the number of anchors/number of proposals) Many, the general quantity can reach ~100k
—— There is https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/retinanet in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
-
CornerNet——[51]H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” in ECCV, 2018, pp. 734–750
——It is not designed for small target recognition, it is a general target recognition model
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/cornernet in mmdetection
-
CenterNet——[47]X. Zhou, D. Wang, and P. Krahenb ¨ uhl, “Objects as points,” ¨ arXiv preprint arXiv:1904.07850, 2019.
——anchor-free target detection network
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/centernet in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
-
FCOS——[4]Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: A simple and strong anchor-free object detector,” TPAMI, vol. 44, no. 4, pp. 1922–1933, 2022.
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/fcos in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
It is one of the commonly used anchor-free target detection algorithms
-
RepPoints——[162]Z. Yang, S. Liu, H. Hu, L. Wang, and S. Lin, “Reppoints: Point set representation for object detection,” in ICCV, 2019, pp. 9656–9665.
——an anchor-free network
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/reppoints in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
-
ATSS——[163]S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li, “Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection,” in CVPR, 2020, pp. 9759–9768.
——It is not designed for small target recognition, it is a general target recognition model
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/atss in mmdetection
-
Deformable-DETR——[52]X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”in ICLR, 2020
——DETR is considered to be a representative method of Transformer application in target detection. This article mainly uses the idea of variable convolution on DETR.
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/deformable_detr in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
-
Sparse RCNN——[164]P. Sun et al., “Sparse r-cnn: End-to-end object detection with learnable proposals,” in CVPR, 2021, pp. 14 449–14 458.
——Sparse R-CNN abandons dense concepts such as anchor boxes or reference points, and starts directly from a sparse set of learnable proposals without NMS post-processing. The entire network is extremely clean and concise, which can be regarded as a new detection paradigm. Sparse framework, end-to-end object detection
——There are https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/sparse_rcnn in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
-
YOLOX——[161]Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,” arXiv preprint arXiv:2107.08430, 2021.
——YOLOx innovation lies in the use of Decoupled Head, SIMOTA and other methods
—— https://github.com/shaunyuan22/SODA-mmdetection/tree/master/configs/yolox in mmdetection
——It is not designed for small target recognition, it is a general target recognition model
-
RFLA——[63]C. Xu, J. Wang, W. Yang, H. Yu, L. Yu, and G.-S. Xia, “Rfla: Gaussian receptive based label assignment for tiny object detection,”in ECCV, 2022.
——It is not in mmdetection, but the author of the code paper published https://github.com/Chasel-Tsui/mmdet-rfla
——Dedicated to extremely small target detection
SDOA-A mmrotate
The recognized targets are all targets in aerial images. In fact, the size of target images is very small, but whether they belong to SOD or not depends on your standards. It’s hard to say.
-
Rotated Faster RCNN——[1]S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” TPAMI,vol. 39, no. 6, pp. 1137–1149, 2017
- in front
—— There is https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/rotated_faster_rcnn/README.md in mmrotate
-
Rotated RetinaNet——[3]T. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar, “Focal loss for ´dense object detection,” TPAMI, vol. 42, no. 2, pp. 318–327, 2020.
- in front
—— There is https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/rotated_retinanet/README.md in mmrotate
-
RoI Transformer——[169] J. Ding, N. Xue, Y. Long, G.-S. Xia, and Q. Lu, “Learning roi transformer for oriented object detection in aerial images,” in CVPR, 2019, pp. 2844–2853.
—— There is https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/roi_trans/README.md in mmrotate
——Although it is a task done on satellite aerial images, it is not designed for small target recognition, but belongs to a general target recognition model
-
Gliding Vertex——[170] Y. Xu, M. Fu, Q. Wang, Y. Wang, K. Chen, G.-S. Xia, and X. Bai, “Gliding vertex on the horizontal bounding box for multioriented object detection,” TPAMI, vol. 43, no. 4, pp. 1452–1459, 2021.
——It is not designed for small target recognition, it is a general target recognition model
—— There is https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/gliding_vertex/README.md in mmrotate
-
Oriented RCNN——[171]X. Xie, G. Cheng, J. Wang, X. Yao, and J. Han, “Oriented r-cnn for object detection,” in ICCV, 2021, pp. 3520–3529.
——It is not designed for small target recognition, it is a general target recognition model
—— There is https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/oriented_rcnn/README.md in mmrotate
-
S2A-Net——[172] J. Han, J. Ding, J. Li, and G.-S. Xia, “Align deep features for oriented object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
——It is not designed for small target recognition, it is a general target recognition model
—— There is https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/s2anet/README.md in mmrotate
-
DODet——[173]G. Cheng, Y. Yao, S. Li, K. Li, X. Xie, J. Wang, X. Yao, and J. Han, “Dual-aligned oriented detector,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
——It is not designed for small target recognition, it is a general target recognition model
- there is no mmrotate
- (SODA-mmrotate/configs/sodaa-benchmarks/) there is no
-
Oriented RepPoints——[174]W. Li, Y. Chen, K. Hu, and J. Zhu, “Oriented reppoints for aerial object detection,” in CVPR, 2022, pp. 1829–1838.
- is an aerial chart, dedicated to small target identification
—— https://github.com/shaunyuan22/SODA-mmrotate/blob/main/configs/rotated_reppoints/README.md in mmrotate
——It is not designed for small target recognition, it is a general target recognition model
-
DHRec——[175]G. Nie and H. Huang, “Multi-oriented object detection in aerial images with double horizontal rectangles,” TPAMI, pp. 1–13,2022.
——It is not designed for small target recognition, it is a general target recognition model
- there is no mmrotate
- (SODA-mmrotate/configs/sodaa-benchmarks/) there is no
The evaluation models used by these two datasets are completely different, none of the models used by the two datasets are the same, just a few models are variants of some original model
The model used by both models
Faster RCNN: They are all the same paper, D uses the original one, A uses the Rotated one,
RetinaNet (retina): They are all the same paper, D uses the most original one, and A uses Rotated
RepPoints:, not the same paper, D uses the most original, A uses Oriented
RCNN series variants: not the same
Three variants of RCNN are used in D: Faster RCNN[1], Cascade RCNN[160], Sparse RCNN[164]
Two variants of RCNN are used in A: Rotated Faster RCNN[1], Oriented RCNN[171]
(Not finished yet)
It seems that the above picture is different from the model used in the paper - is it different? ——Exactly the same, and the above models are more comprehensive, and this one is more credible
——Go to the github code to find a page that lists all the models included in its code——you find this page first—and then compare the model names in it with the names of these models listed by me, https://github. com/shaunyuan22/SODA-mmdetection/tree/master/configs_——Is it completely consistent, if it is completely consistent, then it is just right———If not, which ones are not? List the names of these models that do not have
——The codes of SODA model A and D must be different because they use different models. This part is the main difference of the code, so it is divided into two github projects. ——You copy and compare the two codes to see which part is different, and finally find the part of each model code, which is also the main difference between the two project codes.
——Finally, you need to confirm whether the dozen or so models used by the author are "mainstream recognition models, not specially designed for small target recognition", or "models specially designed for small target recognition" - check The method is very simple. You get the name of the article cited by each model, and then you go to the interpretation blog of the article to see where the innovation of the blog is. If there is no blog about this article, you go to the original text and see Look at what problem the author designed to solve the model - if it is the latter, the code is of reference significance, if it is the former, it is of little significance for me to complete the task of paper innovation
The code provided by the author, let me introduce it to you
The code for the two datasets is as follows. (1) First of all, the models used by the two data sets must be different, but I have not found the location of the code for the list of the models used. (2) The recognition tool library and package used by the two are also different. Driven uses the mmdetection package, and Aerial uses the mmrotate package (probably because the targets in the aerial map often rotate at various angles, so use this bag)
-
SODA-D Benchmark: SODA-mmdetection
What it says:
——It is based on mmdetection.
——The version numbers of the tools used by this repo are as follows: Python 3.8, PyTorch 1.10 and mmdet 2.23.0.
——The corresponding configurations are written in this location sodad-benchmarks((1) first find this location (2) see what is written in it, whether there are any ready-made models called, and whether there are any regulations to use the mmdetection tool to call which ready-made writes good tool)
——Different from the classic data set, there is special preprocessing for pictures, and image split is done before training. The details of how to do the split are written in this location (useless for me)
-
SODA-A Benchmark: SODA-mmrotate
——Based on the package/library of mmrotate
——Python 3.8, PyTorch 1.10 and mmrotate 0.3.0 based on these latter packages
——The corresponding configuration file is placed sodaa-benchmarks. (Wait for you to see, is it listed which models to choose to call?)
The difference between the definitions of tiny and small depends on defined by an area (the area on the picture) threshold or length (the length on the picture) threshold. For example, for the COCO data set, the author of the data set defines an area less than 1024. Small objects of this level
——This reminds me of a problem. When we train this data set, MOT and other pedestrian detection pedistrain detection, as well as pedestrian tracking and video crowd counting data sets, there will be a problem when they are trained together. (1) First of all, some cameras are moving and not static. Some are walking with cameras, and some are shooting from the top of the bus. Everyone has different tracking difficulties (the moving speed of the target is different) (2) The distance between these cameras and the ground The distances are different. Some are taken by a surveillance camera 3 meters above the ground, and some are taken at the same height as a person (about 1.6m above the ground). Then the height from the ground is different, and the average length, width and area of a person are different. The small object threshold applicable to some data sets is not applicable to another video. For example, a small target of 3pix by 3px at an altitude of 3m is considered a small target that is relatively far away, but it may be a small target that is as large as 5px by 5px on another camera that is 1.6m from the ground. I think it is almost impossible to find a set of parameters (for example, 10px is close to the camera, 5px is not far from the camera, 2px is a small target at a long distance), because each shooting angle (1.6m head-up and 3m high-altitude overlooking) , each video shot at a distance from the ground has its own set of parameters.
——I think the most suitable thing is that we shoot video data sets according to a certain height, find suitable parameters on this data set, and then people in the future want to use our model, and he also installs the camera at a distance from the ground and us At the same height, after recording the image, use the model I bought, and use the good distance threshold parameter selection I provided to count people within a few meters. The process of data labeling is time-consuming. You can collect your own data sets when you have time.
Term Explanation
SSD(Single Shot Detector )
A model that is completely opposite to the idea of SSD: detection methods like RCNN, fast RCNN, and faster RCNN all need to obtain candidate regions through some methods , and then use high-quality classifiers to classify these candidate regions. The detection accuracy of this type of method is relatively high , but the calculation overhead is very large , which is not conducive to real-time detection and embedded devices.
The idea of SSD: (1) The two tasks of extracting candidate areas and classifying are integrated into one network . (2) Neither the predefined box (3) nor the candidate area proposal generation network is used to find the target object. Instead (4) through some convolution kernels to calculate the category score and position deviation for the features obtained by the convolutional network. See https://www.bbsmax.com/A/RnJWPBWy5q/ for details; https://blog.csdn.net/qq_36926037/article/details/105678787; https://zhuanlan.zhihu.com/p/39734758
Summarize the principle of SSD in one sentence: discretize the output space of bounding boxes into a series of default boxes (these default boxes are established on each cell position of the feature map, and have different proportions and scales)
A useful feature of SSD for small object detection: combining the prediction of multiple feature maps with different resolutions (sizes), it is beneficial to deal with multi-scale targets.
shot
One-shot learning: (the shot used in this article does not refer to this)
One shot learning means that when a category has a small number of samples in the data set, so small that there is only one picture (data sample) for a category, how do you classify or identify under this condition? This is a small sample learning problem.
Give an example of one-shot learning. For example, if a company has 20 employees, there is only one photo of each employee in the database, and there are 20 photos in total. When checking attendance, you need to scan your face to record attendance. When the amount of data in each category is 1, you need to make a model to identify which one of the twenty employees is the person who swipes his face to check in ( belongs to which category), or is not an employee of this company.
How to solve the specific problem of the one-shot learning mentioned above? First of all, you cannot use a deep learning model with a large number of parameters such as Conv+full connection+softamx CNN (I just don’t use this example here, and it’s good if you use the deep learning model to work later), because of the sample size Too small, it is not enough to fit the model, and it is impossible to get an effective model. what is it now? It's very simple. You design a model for calculating the degree of difference (in turn, the degree of similarity), and calculate the degree of difference one by one between the photo of the person who came to the company to check in and the 20 photos in the database. If the difference is higher than a threshold, it means that the person is not the employee in the database. Below a threshold, it means that this person is this employee. completed the task
MMRotate
What is the function for? To put it simply, when you open the scanning software on your mobile phone, you are going to scan a document or file. At this time, after taking a photo, the scanned image of the entire paper or document is not square, and then can the scanning software help you? You automatically correct, then rotate, so that your scanned document image becomes a saved or printed document.
That's right, this library is for that.
The introduction in professional terms is: In real scenes, the images we see are not all square, such as scanned books and remote sensing images, and the targets to be detected usually have a certain rotation angle. At this time, it is necessary to use the rotating target detection method to accurately locate the target to facilitate subsequent advanced tasks such as identification and analysis. The so-called Rotated Object Detection, also known as Oriented Object Detection, tries to obtain the direction information of the target while detecting the target position. It achieves object detection of rotating rectangles, quadrilaterals, and even arbitrary shapes by redefining the object representation and increasing the number of regression degrees of freedom. Rotating target detection is widely used in face recognition, scene text, remote sensing images, automatic driving, medical images, robot grasping and other fields.