Article directory
basic concept
Object detection is an important problem in computer vision. Its purpose is to identify a specific object from an image or video sequence and separate it from the background. Object detection tasks include:
- Detect objects in images or video sequences, such as people, vehicles, animals, etc.
- Classify objects, such as dividing people into humans, vehicles, animals, etc.
- Determining the location and size of the object, such as marking the location and size of the object in the image.
Object detection algorithms based on deep learning are mainly divided into two categories:
- The two-stage target detection algorithm
first performs region generation (region proposal, RP) (a pre-selection box that may contain the object to be detected), and then performs sample classification through a convolutional neural network.
Task: Feature Extraction—>Generate RP—>Classification/Location Regression.
Common two-stage target detection algorithms include: R-CNN, SPP-Net, Fast R-CNN, Faster R-CNN, and R-FCN. - The one-stage target detection algorithm
does not use RP, and directly extracts features from the network to predict object classification and location.
Task: Feature Extraction -> Classification/Location Regression.
Common one-stage target detection algorithms include: SSD, YOLOv1, YOLOv2, YOLOv3, and RetinaNet, etc.
Two-Stage Object Detection Algorithm
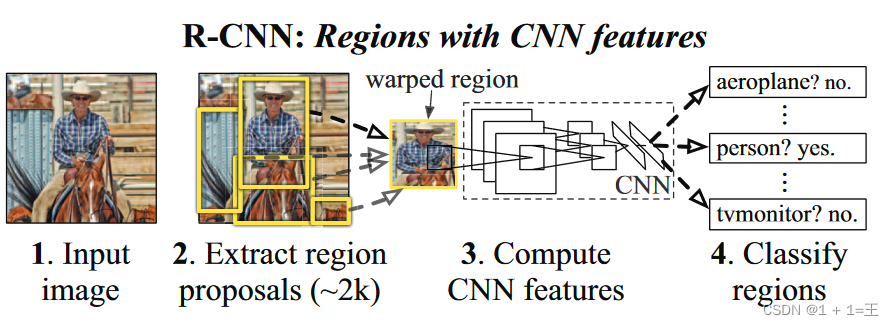
R-CNN
原文链接:Rich feature hierarchies for accurate object detection and semantic segmentation:https://ieeexplore.ieee.org/document/6909475

There are two main innovations in RCNN:
- Use CNN (ConvNet) to calculate feature vectors for region proposals. From experience-driven features to data-driven features (CNN), improve the ability of features to represent samples.
- The method of supervised pre-training under large samples and small-sample fine-tuning is used to solve the problems of difficult training or even over-fitting of small samples.
In the original text, RCNN only needs four steps:
- pre-trained model. Choose a pretrained neural network (eg AlexNet, VGG).
- Retrain fully connected layers. Retrain the last fully connected layer with the object to be detected.
- Extract proposals and compute CNN features. Use the Selective Search algorithm to extract all proposals (about 2000
images), adjust (resize/warp) them to a fixed size to meet the CNN input requirements (because of the limitation of the fully connected layer), and then save the feature map to the local disk. - Train SVMs. SVMs are trained using feature maps to classify objects and backgrounds.
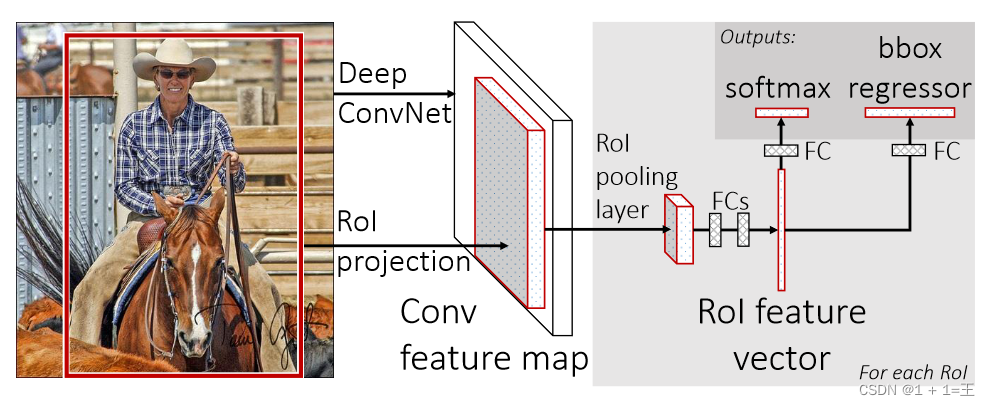
Fast R-CNN
Original link: Fast R-CNN: https://arxiv.org/pdf/1506.01497.pdf

Fast R-CNN has the following innovations:
- Only perform feature extraction on the entire image once, avoiding redundant feature extraction in R-CNN
- Replace the max pooling layer of the last layer with the RoI pooling layer, introduce the suggestion frame data at the same time, and extract the corresponding suggestion frame features
- At the end of the Fast R-CNN network, different parallel fully connected layers are used, which can output classification results and window regression results at the same time, realizing end-t o-end multi-task training [except for suggestion box extraction], and does not require additional
features Storage space [The features in R-CNN need to be kept locally for
training by SVM and Bounding-box regression] - SVD is used to decompose the parallel fully connected layer at the end of the Fast R-CNN network to reduce computational complexity and speed up detection.
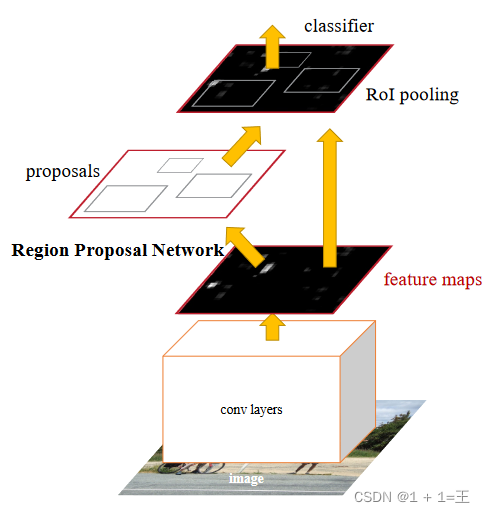
Faster R-CNN
Original text: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks: https://arxiv.org/pdf/1506.01497.pdf

The detection steps of Faster R-CNN are as follows:
- Input: Input a picture with a size of M×N into the Faster-RCNN network for resize operation, and process the size of the picture to H×W to meet the requirements of the model.
- Data preprocessing: First, input the image with the size of M×N into the Faster-RCNN network for resize operation, and process the size of the image to H×W to meet the requirements of the model. Then, the image is input to the RoI Pooling layer for feature size transformation, and the image is input to the Classifier for classification.
- Region extraction: Region extraction is performed on the input image to obtain the feature map of each object.
- RPN: Input the obtained feature map into RPN to get the predicted probability of each object.
- Classifier: The final probability is obtained through the fully connected layer, the category is calculated, and the bounding box regression is performed again to obtain the final precise position of the detection frame.
- Output: According to the position of the detection frame, calculate the precise position of the target in the picture, and output the category of the target.
Through the above steps, the precise position of the target in the picture can be obtained, so as to realize target detection.
FPN
论文原文:Feature Pyramid Networks for Object Detection:https://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf

The FPN network is directly modified on the Faster R-CNN single network, and the feature map of each resolution is introduced into the feature map that is scaled twice by the latter resolution to perform element-wise addition. Through such a connection, the feature maps used for each layer of prediction are fused with features of different resolutions and different semantic strengths, and the fused feature maps of different resolutions are used to detect objects of corresponding resolutions. This ensures that each layer has appropriate resolution and strong semantic features. At the same time, since this method only adds additional cross-layer connections on the basis of the original network, it hardly increases additional time and calculation in practical applications.
Mask R-CNN
Original paper: Mask R-CNN: https://arxiv.org/pdf/1703.06870.pdf

Mask R-CNN is an intuitive extension of Faster R-CNN. The backbone of the network has RPN converted to ResNet's feature pyramid network (FPN), and a branch is added to predict each region of interest (RoI). Segmentation masks for , parallel to existing branches for classification and bounding box regression. The mask branch is a small FCN applied to each RoI to predict the segmentation mask in a pixel-to-top pixel fashion. However, Faster RCNN is not designed for pixel-to-pixel alignment between network input and output. This is most evident in how RoIPool [18, 12], the de facto core operation for processing instances, performs coarse spatial quantization for feature extraction. To address this misalignment, the network uses a simple, quantization-free layer called RoI Align, which faithfully preserves precise spatial positions. FPN construction features include bottom-up (bottom-up), top-down (top-down) and the same layer connection three processes, the bottom-up process is essentially the forward propagation process of the convolutional network.
One-Stage Object Detection Algorithm
SSD
Original paper: SSD: Single Shot MultiBox Detector: https://arxiv.org/pdf/1512.02325.pdf

Unlike the previous R-CNN series, SSD is a one-stage method. SSD uses the VGG16 network as a feature extractor, replaces the subsequent fully connected layer with a convolutional layer, and then adds a custom convolutional layer, and directly uses convolution for detection at the end. A priori frames with different scaling ratios and different aspect ratios are set on multiple feature maps to fuse multi-scale feature maps for detection. The front large-scale feature maps can capture the information of small objects, while the rear small-scale features The graph can capture the information of large objects, thereby improving the accuracy of detection and the accuracy of localization.
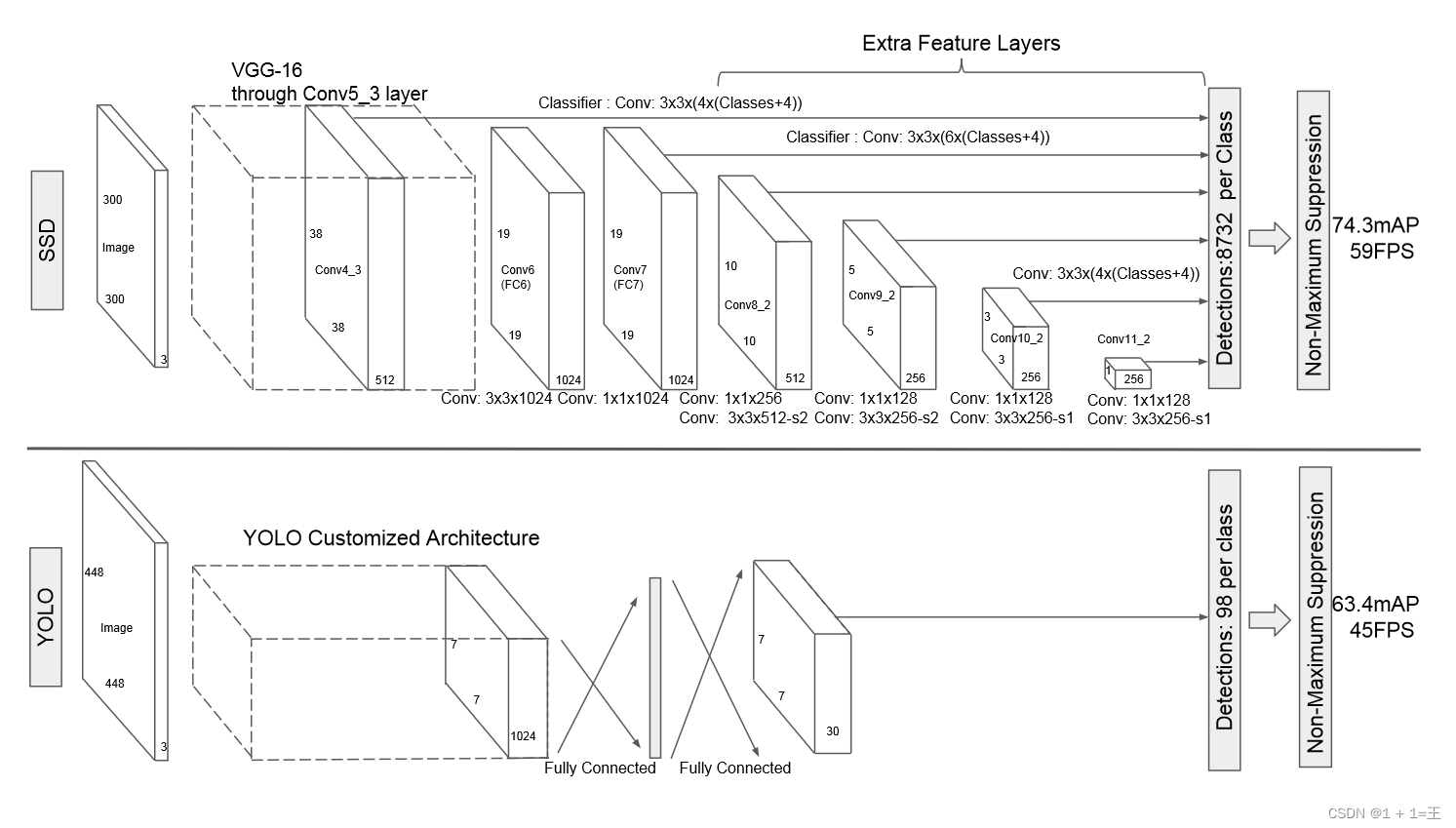
YOLOv1
Original article: You Only Look Once: Unified, Real-Time Object Detection: https://arxiv.org/pdf/1506.02640.pdf

YOLO v1 is a single-stage target detection method. It does not need to generate a priori frame like the two-stage target detection method of Faster R-CNN. The Yolo algorithm uses a separate CNN model for end-to-end target detection. The entire YOLO target detection pipeline is shown in the figure below: first, the input image is resized to 448x448, then sent to the CNN network, and finally the network prediction result is processed to obtain the detected target. YOLO is a new target detection method, which is characterized by fast detection and high accuracy. The authors view the object detection task as a regression problem of object region prediction and class prediction. The method employs a single neural network to directly predict item boundaries and category probabilities, enabling end-to-end item detection.

YOLOv2
Original paper: YOLO9000: Better, Faster, Stronger: https://arxiv.org/pdf/1612.08242.pdf

The comparison between YOLOv2 and YOLOv1 is shown in the figure below:

YOLOv3
Original paper: YOLOv3: An Incremental Improvement: https://pjreddie.com/media/files/papers/YOLOv3.pdf
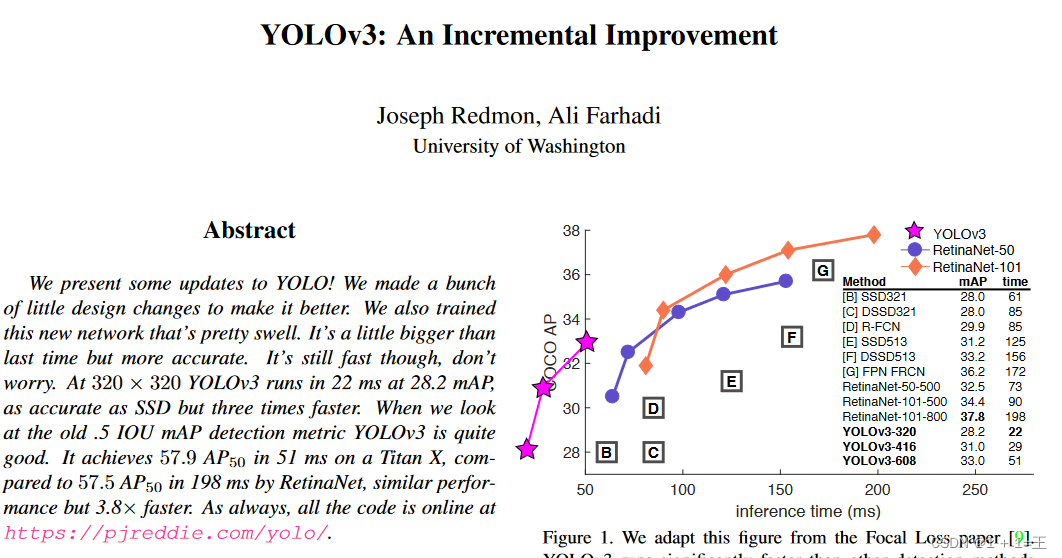
YOLOv3 is an improved YOLO algorithm. Compared with YOLOv2, it has made a compromise between accuracy and speed to achieve better results.
- Improved model structure: YOLOv3 introduces a new module - SPP (Sample Point Proposal) module to improve the accuracy of YOLOv3. The SPP module combines the SSD module of YOLOv2 and the backbone module of YOLOv3, which improves the classification accuracy of YOLOv3. At the same time, the number of residual blocks in the backbone module of YOLOv3 is reduced from 512 in YOLOv2 to 256, which further improves the accuracy of YOLOv3.
- Improved classifier: YOLOv3 has improved the classifier, which uses the weak classifier of YOLOv2 to improve the accuracy of classification. The weak classifier of YOLOv3 only uses a part of the image in each batch to predict through the weak classifier, while YOLOv3+SSD uses the predictive ability of SSD to improve the accuracy of classification.
- Improved prediction box generation: YOLOv3 has also improved in prediction box generation. It uses a separate neural network to divide the image into multiple regions and predict the bounding box and the probability of each region. Compared with YOLOv2, YOLOv3's prediction box generation speed is faster, and the accuracy of the bounding box is also improved.
- Improved parameter adjustment of the weak classifier: YOLOv3 has adjusted the parameters of the weak classifier so that it can perform better on pictures of different sizes. For example, YOLOv3 uses a single large pool layer to replace the three small pool layers in YOLOv2, thereby reducing the number of parameters of the weak classifier and further improving the accuracy of positioning.
Common Datasets for Object Detection
-
PASCAL VOC
PASCAL VOC (The Pascal VOC Challenge) is a computer vision challenge funded by the European Union to promote the development and application of computer vision technology. The challenge has been held since 2005, and the content of the competition is different every year. From the initial classification, to the gradual addition of detection, segmentation, human body layout, action recognition, etc., the capacity and types of data sets are also increasing. and improve. -
MS COCO
MS COCO (Microsoft Common Objects in Context) is a target detection dataset developed by Microsoft Corporation, which originated from the Microsoft COCO dataset funded by Microsoft in 2014. COCO is a data set with a very high industry status and a very large scale, which is used for target detection, segmentation, image description and other scenarios. Features include: Object segmentation: object-level segmentation; Recognition in context: context recognition; Superpixel stuff segmentation: superpixel segmentation; 330K images (>200K labeled): 3.3 million images (over 200,000 labeled images); 1.5 million object instances: 1.5 million object instances; 5 captions per image: each image has 5 descriptions. The MS COCO dataset contains 91 categories of pictures, and the number of pictures in each category is between 500,000 and 2 million. For the target detection task, the 80 classes in the COCO dataset are completely sufficient. -
Google Open Image
Open Images is an open source image dataset released by Google, and the latest V7 version will be released in October 2022. This version of the dataset contains more than 9 million images, all labeled with categories. -
ImageNet
ImageNet is an open dataset composed of contributions from many researchers and universities to study various types of image classification tasks. It contains many types of images, such as flowers, animals, buildings, etc., each type of image has its own subset, which is used to train and test various models. The ImageNet dataset was initiated in 2009 by Professor Li Feifei and others. After years of development, it has now become one of the important platforms for researching image classification.
Annotation tools for object detection
-
LabelImg
LabelImg is an open source image labeling tool. Labels can be used for classification and object detection. It is written in Python and uses Qt as its graphical interface. It is simple and easy to use. Annotations are saved as XML files in PASCAL VOC format, which is the format used by ImageNet. Additionally, it supports the COCO dataset format.
Before installing LabelImg, you need to download and install the precompiled binary library. It can be installed with the following command:
pip install labelimg-i https://pypi.tuna.tsinghua.edu.cn/simple -
Labelme
Labelme is an image labeling tool developed by MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL). People can use this tool to create customized labeling tasks or perform image labeling. The source code of the project is open source. -
Labelbox
Labelbox is an online labeling tool that can help users label and annotate objects in pictures, and save the labeling results as files in xml, txt or json format. Users can download and install the latest version of Labelbox by visiting the official website of Labelbox, then open Labelbox, select the image file to be labeled, and then select the label type (such as VOC label, YOLO label and createML label, etc.), and finally click the "label" button The marking operation can be completed. Labelbox also provides a picture preview function, which can preview the picture effect after labeling before labeling. In addition, Labelbox also provides some other functions, such as setting the version number of the label file, adjusting the save path of the label file, etc. -
RectLabel
Rect Label is an online free image annotation tool, labels can be used for object detection, segmentation and classification. Features or features:
Available components: rectangular box, polygon, cubic Bezier curve, line and point, brush, superpixel
can only mark the whole image without drawing
can use brush and superpixel
export to YOLO, KIT TI, COCO JSON and CSV formats
Read and write in PASCAL VOC XML format
Automatically label images with Core ML models
Convert video to image frames
- CVAT
CVAT (Chinese Visual Assisted Text Annotation Tool) is a text annotation tool based on computer vision and natural language processing technology. It can quickly and accurately mark the text information in the image, helping users to quickly and accurately parse and analyze the image.
The main functions of CVAT include:
Automatic labeling: supports batch labeling, and can automatically label multiple objects in a picture.
Real-time annotation: The image can be annotated in real time, and the annotation result will be displayed in the annotation box above the image in real time.
Multi-label annotation: Multi-label annotation can be performed on objects in the image, and each label can correspond to one or more objects.
Image analysis: Image analysis can be performed on the annotation results, such as detecting targets, segmenting images, etc.
Visualization of annotation results: The annotation results can be displayed visually in the form of images, texts, numbers, etc., which is convenient for users to view and analyze.
CVAT can be widely used in image processing, natural language processing, text annotation and other fields to help users solve problems quickly and accurately.