What is graph database Neo4j
The so-called graph database is generally composed of nodes and relationships, neo4j is one of them
It is superior to the traditional database mysql in seeking data association
And neo4j supports hundreds of millions of nodes and relationships
Traditional graph operations are generally performed in memory and cannot process the entire knowledge graph. Neo4j can complete graph operations on disk
Therefore, neo4j is often used as a data carrier in the question answering system to quickly search for keyword information
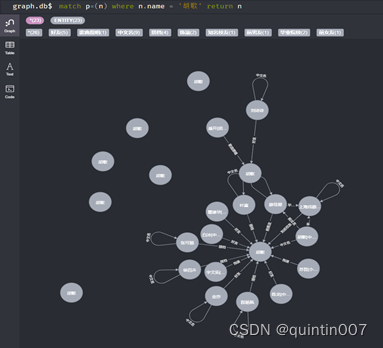
Create a node:
create (n:person's name{name:Xiao Mingle)-[p:age{name:'age]->(m:age{name:183)

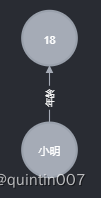
show first degree relationship
match p-(n)-[ ] ->(m) where n.name ='Xiao Ming' return n,m
Show the relationship between the first level and the second level
match p=(n)-[*1…2]->(m) where n.name ='习近’return n,m
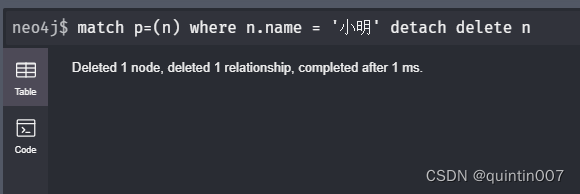
delete node
match p=(n) where nname =' ' detach delete n
In a graph with a large number of nodes and relationships, there is faster database operation speed
Supports distributed access, and can use clusters to expand memory and disk capacity
Support distributed high availability, can support large-scale
Data growth Data is safe and reliable, supporting real-time backup of data
Through the Cypher statement, the operation and display of graph data are more intuitive
Construct data in Neo4j supported formats
There are two ways to import general data into Neo4j:
1. Use fixed-format csv for data loading
2. Use code to import data
The two methods have their own advantages and disadvantages. Using CS to import data is faster, but relatively fixed; using code to import is more flexible, and there is a certain bottleneck in terms of processing speed.
If you use Csv to import, you generally need two pieces of data, entity.csv is used to define the entity; relationship.csv is used to describe the relationship, so the existing data needs to be reprocessed.
This is a sample of entity.csv

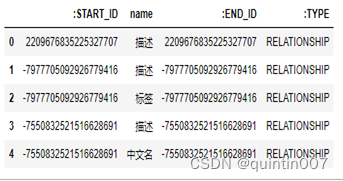
This is a sample of relationship.csv
Preparation before data processing
import csv
from tqdm import tqdm
entity = open('entity.csv',w'encoding=utf-8newline=")
relationship =open(relationship.csv,wencoding='utf-8newline=")
#Open 2 logger
entities writer = csv.writer(entity)
relationship writer = csv.writer(relationship)
#The following are the two csvs accepted by neo4i, the required column names
entity writer.writerow([:IDname:LABELT)relationship writer.writerow([ :START IDname:ENDIDTYPET)
Formally write data
data = pdread csv(file name,chunksize=100000)
for ind,i in enumerate(data):
for d in tqdm(range(len(0)):
d = i.loc[d]
entity writer.writerow([hash(d.实体)d.实体ENTITY)
entity writer.writerow([hash(d.值)d值ENTITYT)
relationship writer.writerow([hash(d.实体)d.属性hash(d.值)RELATIONSHIPT)
break