Table of contents
1. Time series data
1.1 Definition
Time series data is a series of data indexed by the time dimension, which describes the measurement value of a measured subject at each time point within a time range.
When modeling time-series data, there are three important parts: subjects, time points, and measurements.
The monitoring data we often come into contact with is a type of time-series data, such as the hourly occupancy of machine memory at intervals of 1 second.
1.2 Mathematical model
The basic model of time series data can be divided into the following parts:
- Metric: The measured data set, similar to the table in the relational database, is a fixed attribute and generally does not change over time
- Timestamp: Timestamp, representing the time point when the data was collected
- Tags: Dimension column, used to describe the Metric, representing the attribution and attribute of the data, indicating which device/module generated it, and generally does not change over time
- Field/Value: The index column, which represents the measurement value of the data, can be single-valued or multi-valued
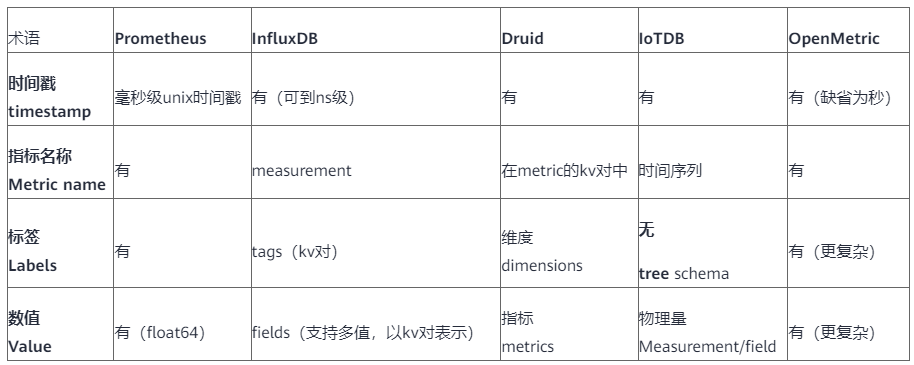
Correspondence of basic concepts in common TSDB
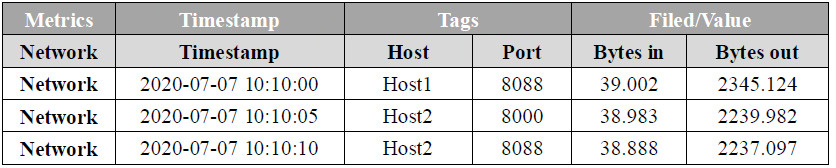
The figure below shows the timing data of a machine's network traffic
1.3 Data characteristics
- Data mode: Time series data grows with time, and the same dimension takes repeated values
- Data writing: continuous high-concurrency writing, very few update operations
- Data query: Statistical analysis of indicators by different dimensions
2. Storage optimization
The invention of time-series database products is to solve the shortcomings and defects of traditional relational databases in time-series data storage and analysis. Corresponding to the above data characteristics, time-series databases have been roughly optimized:
-
storage cost:
Utilize the characteristics of time increment, dimension repetition, and index smooth change, reasonably select the encoding compression algorithm, and improve the data compression ratio;
through pre-decreasing accuracy, aggregate historical data to save storage space -
High concurrent write:
Write data in batches to reduce network overhead;
data is first written into memory, and then periodically dumped as immutable file storage -
Low query latency, high query concurrency:
Optimize common query modes, reduce query delay through indexing and other technologies;
improve query concurrency through caching, routing and other technologies
3. Storage principle
Traditional database storage uses B-tree, because of its organizational form that helps reduce the number of seeks during query and sequential insertion. We know that the disk seek time is very slow, generally around 10ms. The random read and write of the disk is slow on the seek. For random writing to the B tree, a lot of time will be spent on disk seeking, resulting in a very slow speed.
For time-series databases where more than 90% of the scenarios are written, B-tree is obviously not suitable. The mainstream of the industry is to adoptLSM treeReplacing the B tree, the LSM tree includes two parts: the data structure in the memory and the file on the disk.
The operation process of LSM tree is as follows:
When data is written and updated, the data structure located in memory is first written. In order to avoid data loss, it will also be written to the WAL file first. The data structure in the memory will be flushed to the disk at regular intervals or when it reaches a fixed size. Files on these disks are not modified. As more and more files are accumulated on the disk, the merge operation will be performed regularly to eliminate redundant data and reduce the number of files.
It can be seen that the core idea of LSM tree is to obtain higher write performance through memory write and subsequent sequential write to disk, avoiding random write. But at the same time, the read performance is also sacrificed, because the value of the same key may exist in multiple HFiles. In order to obtain better read performance, it can be optimized in other ways.
4. Time series data model
4.1 Based on tags (tag-value)
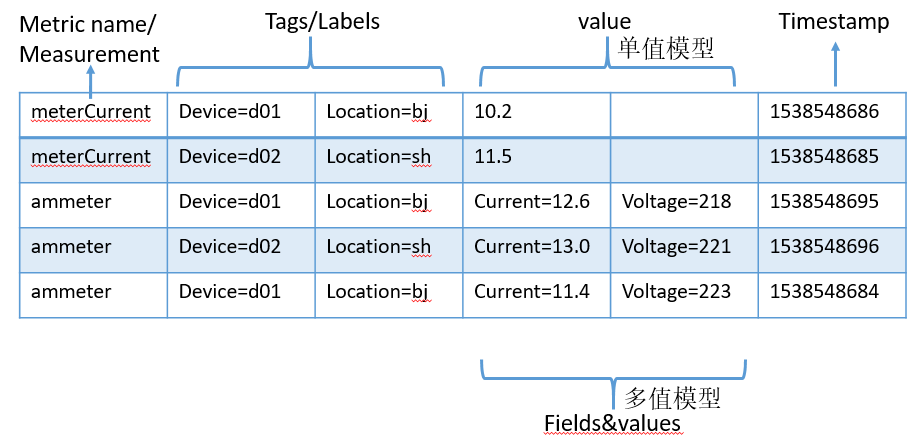
Time series data is generally divided into two parts, one is the identifier (index name, label or dimension), which is convenient for searching and filtering; the other is the data point, including timestamp and measurement value. Values are mainly used for calculations, and are generally not indexed. From the number of values contained in the data points, it can be divided into single-value models (such as Prometheus) and multi-value models (such as InfluxDB); from the perspective of data point storage, there are row storage and column storage. In general, column storage can have better compression ratio and query performance.
4.2 Based on tree schema
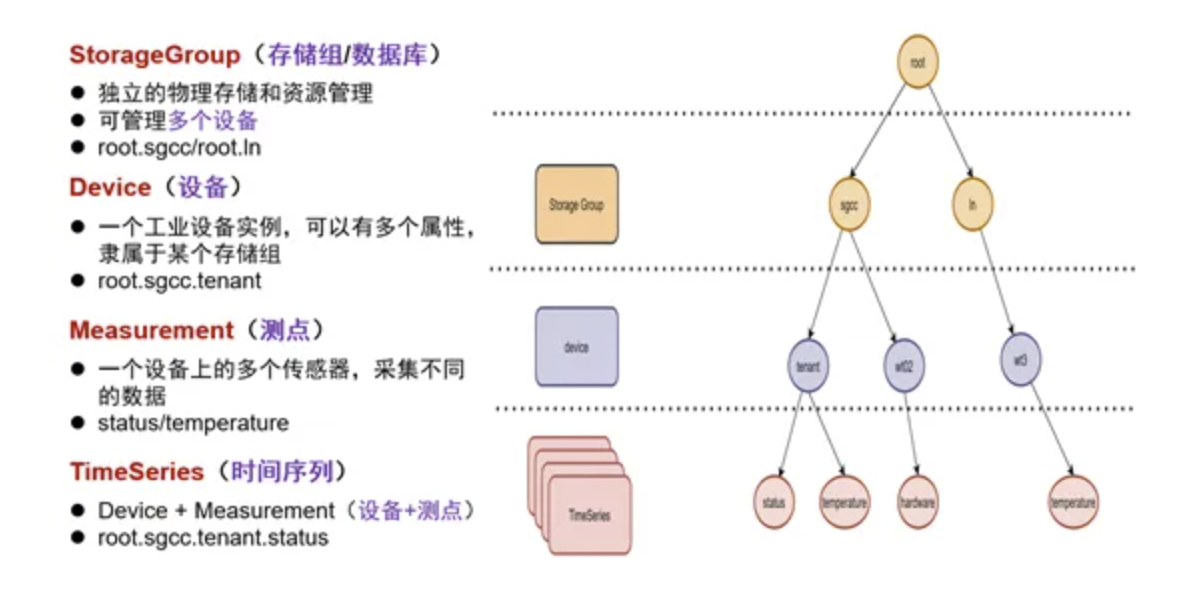
The biggest difference between the data model of IoTDB and other TSDBs is that it does not use the tag-value, Labels mode, but uses a tree structure to define the data mode: root is the root node, and storage groups, devices, and sensors are connected in series. In the tree structure, a path (Path) is formed from the root node through storage groups, devices, and sensor leaf nodes. A path can name a time series, and the levels are connected with ".".
Reference links:
https://blog.miuyun.work
https://zhuanlan.zhihu.com/p/410255386
https://www.cnblogs.com/eyesfree/p/15394159.html
https://bbs.huaweicloud. If com/blogs/300156
is wrong, please point it out, thanks~