By Steffen Anderson
Source: DeepHub IMBA
Machine learning can be used to solve a wide range of problems. But with so many different models to choose from, it can be a hassle to know which one is right for you. The summary of this article will help you choose the machine learning model that best suits your needs.
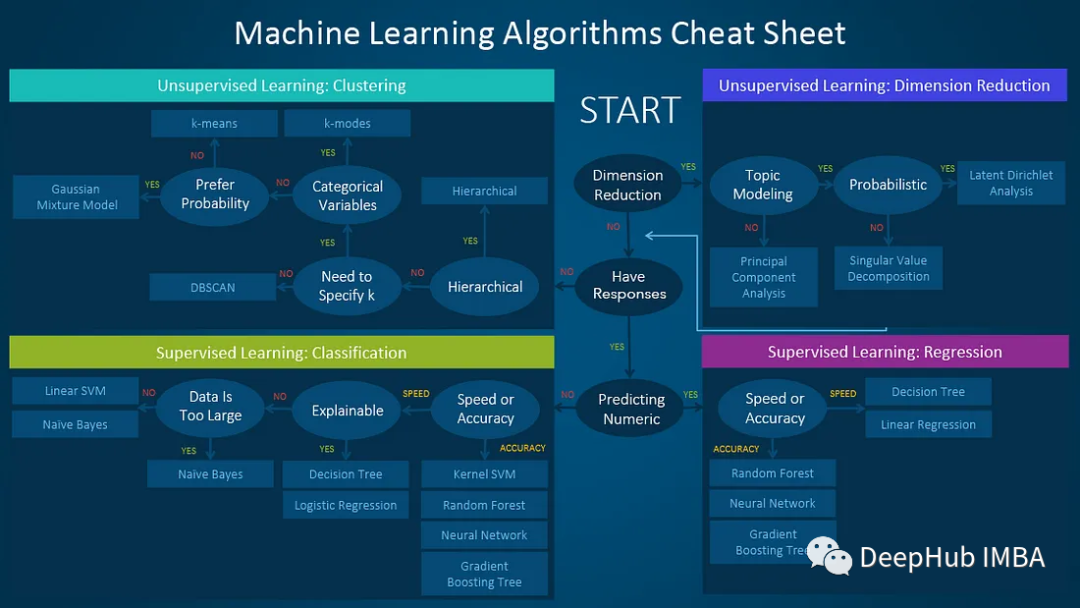
1. Determine the problem you want to solve
The first step is to identify the problem you want to solve: is it a regression, classification or clustering problem? This can narrow down your options and decide which type of model to choose.
What type of problem do you want to solve?
Classification problems: logistic regression, decision tree classifier, random forest classifier, support vector machine (SVM), naive Bayes classifier or neural network.
Clustering problems: k-means clustering, hierarchical clustering or DBSCAN.
2. Consider the size and nature of your dataset
a) The size of the dataset
If you have a small dataset, choose a less complex model such as linear regression. For larger datasets, more complex models such as random forests or deep learning may be appropriate.
How to judge the size of the data set:
Large datasets (thousands to millions of rows): gradient boosting, neural networks, or deep learning models.
Small datasets (less than 1000 rows): Logistic Regression, Decision Trees, or Naive Bayes.
b) Data labeling
Data has predetermined outcomes that unlabeled data does not. In the case of labeled data, typically a supervised learning algorithm such as logistic regression or decision trees is used. Whereas unlabeled data requires unsupervised learning algorithms such as k-means or principal component analysis (PCA).
c) The nature of the characteristic
If your features are categorical, you may want to use decision trees or Naive Bayes. For numerical features, linear regression or support vector machines (SVM) may be more appropriate.
Categorical Features: Decision Trees, Random Forests, Naive Bayes.
Numerical features: linear regression, logistic regression, support vector machines, neural networks, k-means clustering.
Mixed features: decision trees, random forests, support vector machines, neural networks.
d) sequential data
If you are dealing with sequential data, such as time series or natural language, you may need to use recurrent neural network (rnn) or long short-term memory (LSTM), transformer, etc.
e) missing values
Many missing values can be used: decision trees, random forests, k-means clustering. If the missing value is wrong, you can consider linear regression, logistic regression, support vector machine, neural network.
3. Which is more important, interpretability or accuracy
Some machine learning models are easier to interpret than others. If you need to interpret the results of your model, you can choose models such as decision trees or logistic regression. If accuracy is more critical, more complex models such as random forests or deep learning may be more suitable.
4. Unbalanced categories
If you are dealing with unbalanced classes, you may want to use models such as random forests, support vector machines or neural networks to solve this problem.
Handle missing values in the data
If you have missing values in your dataset, you may want to consider imputation techniques or models that can handle missing values, such as K-nearest neighbors (KNN) or decision trees.
5. Data complexity
If non-linear relationships between variables are possible, more complex models such as neural networks or support vector machines need to be used.
Low complexity: linear regression, logistic regression.
Medium Complexity: Decision Trees, Random Forests, Naive Bayes.
High complexity: neural network, support vector machine.
6. Balance speed and accuracy
More complex models may be slower if the tradeoff between speed and accuracy is a concern, but they may also provide higher accuracy.
Speed is more important: decision trees, Naive Bayes, logistic regression, k-means clustering.
Accuracy is more important: Neural Networks, Random Forests, Support Vector Machines.
7. High-dimensional data and noise
If you are dealing with high-dimensional or noisy data, you may need to use dimensionality reduction techniques (such as PCA) or models that can handle noise (such as KNN or decision trees).
Low noise: linear regression, logistic regression.
Moderate noise: decision trees, random forests, k-means clustering.
Noisy: Neural Networks, Support Vector Machines.
8. Real-time prediction
If you need real-time predictions, you need to choose a model like a decision tree or a support vector machine.
9. Dealing with Outliers
If the data has many outliers, you can choose a robust model like svm or random forest.
Models sensitive to outliers: linear regression, logistic regression.
Robust models: decision trees, random forests, support vector machines.
10. Deployment Difficulty
The ultimate goal of the model is for online deployment, so the difficulty of deployment is the final consideration:
Some simple models, such as linear regression, logistic regression, decision trees, etc., can be relatively easily deployed in production environments because of their small model size, low complexity, and low computational overhead. On large-scale, high-dimensional, nonlinear and other complex data sets, the performance of these models may be limited, requiring more advanced models such as neural networks, support vector machines, etc. For example, in domains such as image and speech recognition, datasets can require extensive processing and preprocessing, which can make model deployment difficult.
Summarize
Choosing the right machine learning model can be a challenging task, requiring trade-offs to be made based on the specific problem, data, speed interpretability, deployment, etc., and the most suitable algorithm to be selected based on the requirements. By following these guidelines, you can ensure that your machine learning model is a good fit for your specific use case and can provide you with the insights and predictions you need.
END
Welcome to join Imagination GPU and artificial intelligence communication group 2

Join the group, please add the editor WeChat: eetrend89
(Please add company name and title)
recommended reading
Dialogue with the Chairman of Imagination China: Using GPU as the fulcrum to strengthen software and hardware collaboration to facilitate digital transformation
[Video] Technical Director of Imagination China fully interprets IMG DXT GPU

Imagination Technologies is a UK-based company dedicated to the research and development of chips and software intellectual property (IP). Products based on Imagination IP are used in the phones, cars, homes and workplaces of billions of people around the world. For more information on cutting-edge technologies such as the Internet of Things, smart wearables, communications, automotive electronics, and graphics and image development, welcome to Imagination Tech!