1. Test data
emp集合
db.emp.insert(
[
{
_id: 1,
name: "tom",
age: 13,
likes: ["basketball", "football"],
sex: "F",
dept_id: 1
},
{
_id: 2,
name: "jack",
age: 14,
likes: ["games", "douyin"],
sex: "M",
dept_id: 2
},
{
_id: 3,
name: "amy",
age: 23,
likes: ["code", "basketball"],
sex: "F",
dept_id: 1
},
{
_id: 4,
name: "musk",
age: 42,
likes: ["car", "space"],
sex: "F",
dept_id: 2
},
{
_id: 5,
name: "paul",
age: 34,
likes: [],
sex: "F",
dept_id: 2
}
]
)
dept集合
db.dept.insert(
[
{
_id: 1,
d_name: "研发部"
},
{
_id: 2,
d_name: "运维部"
}
]
)
2. Simple demo
A simple aggregation operation is as follows, this aggregation operation will go through two stages of data processing:
- The first pipeline stage is $match : all documents will be filtered out
sex值为F 并且 dept_id 为2and then output to the next pipeline operation; - The second pipeline stage is $project : used to define the returned field content, here returns _id name sex dept_id and the custom field name emp_name takes the value of name
db.emp.aggregate([
{
$match: {
sex: "F", //匹配 sex = F的
dept_id: 2 //匹配 dept_id = 2的
}
},
{
$project: {
//映射,1显示,0不显示
_id: 1,
name: 1,
sex: 1,
dept_id: 1,
}
}
])
operation result

java code
@Test
void agg() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.match(Criteria.where("sex").is("F").and("dept_id").is(2)),
Aggregation.project("_id", "name", "sex", "dept_id")
);
//参数一 Aggregation
//参数二 聚合名
//参数三 对应的类对象
AggregationResults<Emp> emp = mongoTemplate.aggregate(aggregation, "emp", Emp.class);
//调用getMappedResults()方法返回结果集
List<Emp> mappedResults = emp.getMappedResults();
}
3.$Match
$match is mainly used to filter qualified data . Usually, $match should be placed as early as possible. At this time, it will use the index to optimize the query, and it can also reduce the amount of data that needs to be processed in the subsequent stage. Examples are as follows:
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.match(查询条件)
);
4.$Project
$project is mainly used to define the fields that need to be returned , 1 means to include this field, and 0 means not to include it.
//定义只返回k1和k2字段的值,注意这里必须填集合中的字段名
Aggregation.project("k1", "k2")
5.$group
The $group pipeline stage is similar to group bythe clauses , and is used for group calculations. Examples are as follows:
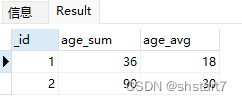
db.emp.aggregate(
{
//根据dept_id分组,查询总年龄和平均年龄
$group:{
"_id": "$dept_id",
"age_sum": {
$sum: "$age"},
"age_avg": {
$avg: "$age"}
}
}
)
output
java code
@Test
void agg() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.group("dept_id").sum("age").as("age_sum").avg("age").as("age_avg"),
Aggregation.sort(Sort.by(Sort.Order.asc("_id")))
);
//第三个参数,指定数据每条数据以什么类型返回,这里显然以Map形式返回。
AggregationResults<Map> emp = mongoTemplate.aggregate(aggregation, "emp", Map.class);
List<Map> mappedResults = emp.getMappedResults();
for (Map mappedResult : mappedResults) {
System.out.println(mappedResult);
}
}
/*
* 输出结果
* {_id=1.0, age_sum=36.0, age_avg=18.0} //_id就是 dept_id(这里根据dept_id分组)
* {_id=2.0, age_sum=90.0, age_avg=30.0}
*/
Refer to more aggregate functions after group
6.$unwind
$unwind 数组中splits the document according to each element
grammatical format
{
$unwind:
{
path: <field path>,
includeArrayIndex: <string>,
preserveNullAndEmptyArrays: <boolean>
}
}
- path : array field for expansion ;
- includeArrayIndex : used to display the position information of the corresponding element in the original array;
- preserveNullAndEmptyArrays : If the field value used for expansion is null or an empty array, the corresponding document will not be output to the next stage. If you want to output to the next stage, you need to set this property to true. Example statements are as follows:
example
db.emp.aggregate(
{
$unwind:{
path: "$likes",
includeArrayIndex: "arrayIndex",
preserveNullAndEmptyArrays: true
}
}
)
结果

Note: If the value of preserveNullAndEmptyArrays is false or not set, the 5-paul data will not be output:
java code
@Test
void agg() {
Aggregation aggregation = Aggregation.newAggregation(
//默认 没有第二个参数,第三个参数为false
Aggregation.unwind("likes")
);
AggregationResults<Emp> emp = mongoTemplate.aggregate(aggregation, "emp", Emp.class);
List<Emp> mappedResults = emp.getMappedResults();
for (Emp mappedResult : mappedResults) {
System.out.println(mappedResult);
}
}
/*
Emp{id=1, name='tom', age=13, lists=[basketball], sex='F', deptId=1}
Emp{id=1, name='tom', age=13, lists=[football], sex='F', deptId=1}
Emp{id=2, name='jack', age=14, lists=[games], sex='M', deptId=2}
Emp{id=2, name='jack', age=14, lists=[douyin], sex='M', deptId=2}
Emp{id=3, name='amy', age=23, lists=[code], sex='F', deptId=1}
Emp{id=3, name='amy', age=23, lists=[basketball], sex='F', deptId=1}
Emp{id=4, name='musk', age=42, lists=[car], sex='M', deptId=2}
Emp{id=4, name='musk', age=42, lists=[space], sex='M', deptId=2}
*/
7.$sort&skip&limit
$sortIt is mainly used for sorting operations. It should be noted that if possible, the operation should be placed in the first stage of the pipeline as much as possible, so that the index can be used for sorting, otherwise it needs to use memory for sorting, and the sorting operation will become quite Expensive, requiring additional consumption of memory and computing resources. The example is as follows$limitLimit the number of returned documents.$skipSkip a certain number of documents.
db.emp.aggregate(
[
{
$sort:{
age:1}}, //按照年龄升序排序
{
$skip:2}, //跳过前2条数就
{
$limit:2} //显示2条数据
]
)
java code
@Test
void agg() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.sort(Sort.by(Sort.Order.asc("age"))),
Aggregation.skip(2),
Aggregation.limit(2)
);
AggregationResults<Emp> emp = mongoTemplate.aggregate(aggregation, "emp", Emp.class);
List<Emp> mappedResults = emp.getMappedResults();
for (Emp mappedResult : mappedResults) {
System.out.println(mappedResult);
}
}
/*运行结果
Emp{id=3, name='amy', age=23, lists=[code, basketball], sex='F', deptId=1}
Emp{id=5, name='paul', age=34, lists=[], sex='F', deptId=2}
*/
8.$lookup
8.1 Association query
$lookup is similar to the left outer join in most relational databases, and is used to realize the connection between different collections. Its basic syntax is as follows:
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
- from : Specify a collection in the same database for connection operations;
- localField : the field used for connection in the connection collection;
- foreignField : the field used for connection in the collection to be connected;
- as : specified for storing matching documents
新数组字段的名称. If the specified field already exists, it will be overwritten.
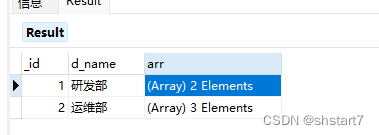
//用dept表的主键_id 连接emp表的外键dept_id
db.dept.aggregate([
{
$lookup:
{
from: "emp",
localField: "_id",
foreignField: "dept_id",
as: "arr"
}
}
])
java code
@Test
void agg() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.lookup("emp", "_id", "dept_id", "arr")
);
AggregationResults<Map> emp = mongoTemplate.aggregate(aggregation, "dept", Map.class);
List<Map> mappedResults = emp.getMappedResults();
for (Map mappedResult : mappedResults) {
System.out.println(mappedResult);
}
}
/*
{_id=1.0, d_name=研发部, arr=[{_id=1.0, name=tom, age=13.0, likes=[basketball, football], sex=F, dept_id=1.0}, {_id=3.0, name=amy, age=23.0, likes=[code, basketball], sex=F, dept_id=1.0}]}
{_id=2.0, d_name=运维部, arr=[{_id=2.0, name=jack, age=14.0, likes=[games, douyin], sex=M, dept_id=2.0}, {_id=4.0, name=musk, age=42.0, likes=[car, space], sex=M, dept_id=2.0}, {_id=5.0, name=paul, age=34.0, likes=[], sex=F, dept_id=2.0}]}
*/