
Table of contents
1. The node is offline or decommissioned
1.1 Distinguish the difference between node offline and node decommissioning
1.2 How to deal with various storms when nodes go offline
1.2.1 Datanode block replication
1.2.2 Control node offline RPC storm parameters
1. The node is offline or decommissioned
Background: 5 data nodes store about 11.2 million 40T data blocks, the cluster bandwidth is limited to 200M/s, and the standard node configuration is 4*5T.
1.1 Distinguish the difference between node offline and node decommissioning
Node decommissioning : first add the node to the decommissioning list normally, first tell the namenode and yarn not to submit new tasks and write data; then wait for the data blocks on the node to be copied in the cluster; at this time, the decommissioned node is the priority As the data source of srcNode (the node in decommissioning is preferred as the replication data source src, because it has no write request and the load is low), other nodes copy data blocks from the decommissioned node to other nodes, so the load of this node at this time will be high. After all data blocks are copied, the node status becomes Decommissioned, which can be viewed from the interface. Note that the data node decommissioning data starts to copy after 10 minutes and 30 seconds, not because it is actively decommissioning, because the nannode and datanode always maintain a simple master-slave relationship, and the namenode node will not actively initiate any IPC to the datanode node Call, all the operations that the datanode node needs to complete with the namenode are returned by the DatanodeCommand carried in the heartbeat response of the two.

Node disconnection: For example, the datanode is forced to stop, the physical machine hangs up (such as high load disconnection, sudden network failure, hardware failure, etc.), these are all node disconnections, generally after 10 minutes and 30 seconds by default (mainly controlled by two parameters ) namenode will detect that the node communication is abnormally disconnected. Then the namenode finds out all the blockids of the node and the machine where the corresponding replica is located according to the IP of the node, and arranges data replication through the heartbeat mechanism. At this time, the data source of the data replication is not the offline node, but one of multiple replicas The node where the copy is located also follows the rack awareness and copy shelving strategy at this time.
Screaming reminder: The difference between node offline and decommissioning is not only the data replication method, but also the namenode’s data replication strategy for Under-Replicated Blocks (data block replication levels are divided into 5 types); In an extreme example, data will not be lost when a single-copy node is decommissioned, but if a single-copy node goes offline, the data will actually be lost;
1.2 How to deal with various storms when nodes go offline
Dozens of terabytes, or even hundreds of terabytes, millions of blocks of nodes will go offline, and a large number of RPC storms will occur. In our cluster with a large number of small files, it is a great challenge for the namenode, which not only affects production performance, but also has many problems. Big hidden danger, especially for clusters with limited bandwidth bottlenecks. Generally speaking, the value for namenode to detect whether the datanode is offline is 10*3s (heartbeat time) + 2*5min (namenode detection time, the parameter is: dfs.namenode.heartbeat.recheck-interval) = 10 minutes 30s. If the bandwidth continues to be full within 10 minutes and 30 seconds, the RPC request is delayed, and the communication between the datanode and namenode nodes is not smooth, it is easy to cause other nodes to continue to go offline, forming a vicious circle. How should this situation be avoided?
1.2.1 Datanode block replication
NameNode maintains a replication priority queue, and the file blocks with insufficient replicas are prioritized, and the file blocks with only one replica have the highest replication priority. So if you look at the two copies of the cluster from here, as long as there is an abnormality in one block, there will be only one copy left, which is the block with the highest priority. It will be copied in storm mode. If the control is not good, it will easily affect the performance of the cluster, or even hang the cluster. Therefore, it is generally not recommended that the cluster replication factor be 2.
The five priority queues of the following block to be replicated: In fact, it is in the private method getPriority of UnderReplicatedBlocks, which looks like this:
/**HDFSversion-3.1.1.3.1, 保持低冗余块的优先队列*/
class LowRedundancyBlocks implements Iterable<BlockInfo> {
/** The total number of queues : {@value} */
static final int LEVEL = 5;
/** The queue with the highest priority: {@value} */
static final int QUEUE_HIGHEST_PRIORITY = 0;
/** The queue for blocks that are way below their expected value : {@value} */
static final int QUEUE_VERY_LOW_REDUNDANCY = 1;
/**
* The queue for "normally" without sufficient redundancy blocks : {@value}.
*/
static final int QUEUE_LOW_REDUNDANCY = 2;
/** The queue for blocks that have the right number of replicas,
* but which the block manager felt were badly distributed: {@value}
*/
static final int QUEUE_REPLICAS_BADLY_DISTRIBUTED = 3;
/** The queue for corrupt blocks: {@value} */
static final int QUEUE_WITH_CORRUPT_BLOCKS = 4;
/** the queues themselves */
private final List<LightWeightLinkedSet<BlockInfo>> priorityQueues
= new ArrayList<>(LEVEL);
}L1 (highest) : Blocks with risk of data loss, such as: 1. Blocks with only one copy (especially for blocks with 2 copies, one node goes offline) or these blocks have 0 active copies; 2. A single copy is running Blocks owned by decommissioned nodes.
L2: The actual value of the block copy is much lower than the configured value (for example, 3 copies, 2 missing), that is, when the number of copies is less than 1/3 of the expected value, these blocks will be copied by the second priority. For example, for a block with 4 copies, if 3 of them are lost or broken, it will be duplicated more preferentially than 2 of the 4-copy block.
L3: Insufficient copies, those copies with higher priority than L2, are copied first. third priority.
L4: The minimum number of copies of the block that meets the requirements. The demand for duplication is lower than that of L2-L3.
L5: The block is corrupted and there is currently a non-corrupted copy available
1.2.2 Control node offline RPC storm parameters
The three parameters are the parameters in hdfs-site.xml. For details, please refer to the Apache Hadoop official website. In fact, the block replication speed is determined by two aspects. One is the speed of namenode distribution tasks, and the other is the speed of replication between datanodes. The former can be understood as an entrance, while the latter can be regarded as an exit.
1. Entry parameters: Control task distribution from the namenode level. This parameter modification must restart the namenode, and does not need to restart the datanode.
dfs.namenode.replication.work.multiplier.per.iteration The default value of this parameter is 2 for apache hadoop and 10 for cdh cluster
This parameter determines the number of blocks that can be replicated for each DN when NN and DN send a task list in a heartbeat (3s). For example, if there are 5 nodes in the cluster, if this value is set to 5, then the number of data blocks that the namnode can send to the datanode for one heartbeat is 5*5=25 blocks. If a node is offline/decommissioned and there are 365,588 blocks that need to be copied, how long does it take for the namenode to distribute the task of the blocks to be copied to the datanode?
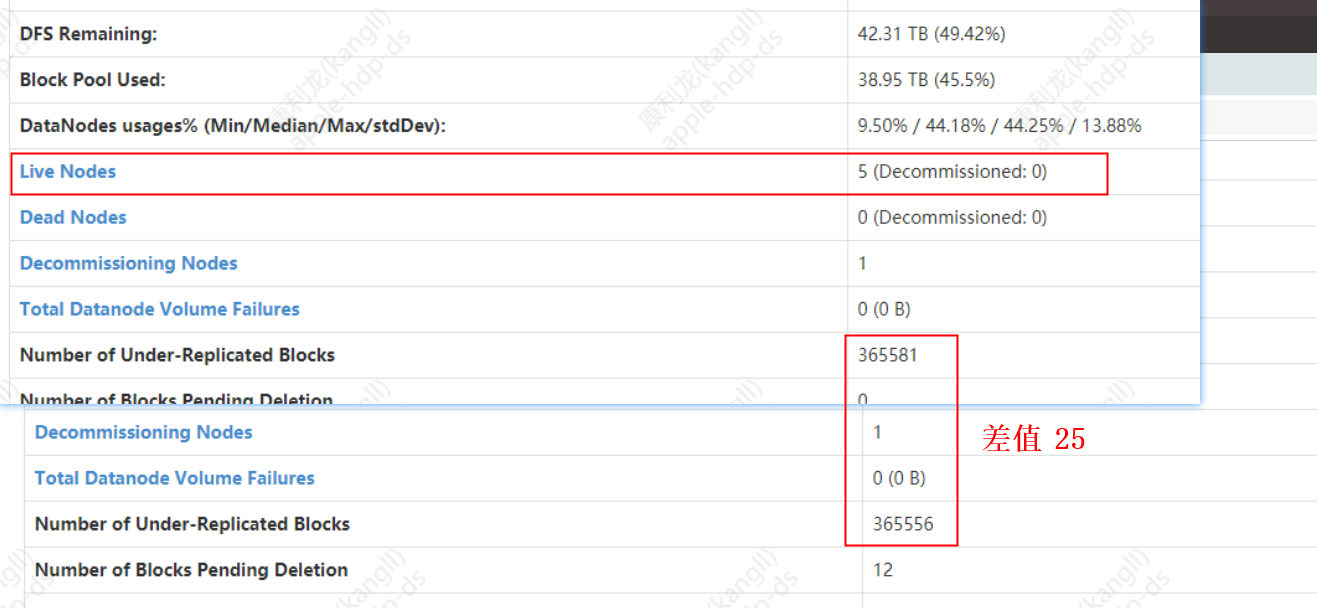
The Ambari-web namenode parameters are set as follows:
The result of the limit calculation:
Task distribution time = total number of blocks to be copied / (cluster active dn * parameter value) * heartbeat time
time=365585/(5*5)=14623 heartbeats*3s/each heartbeat=43870s = about 13 hours
So the more nodes there are, the faster the tasks will be distributed, and the distribution speed is proportional to the number of nodes and this parameter
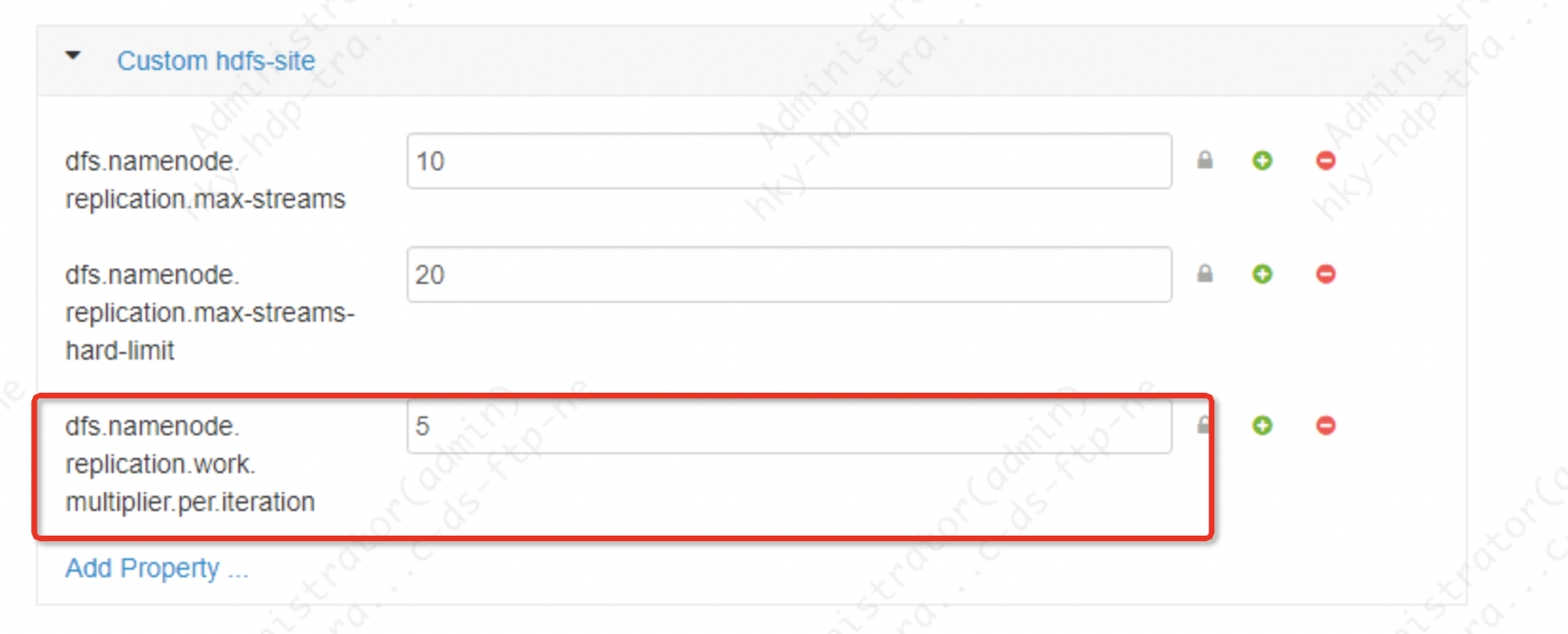
2. Export parameters: Compared with the above task distribution control from Namenode, the following two are controlled at the datanode level. These two parameters also need to restart the namenode
dfs.namenode.replication.max-streamsThe default value of apache hadoop is 2, and the default value of cdh cluster is 20.
The meaning of this parameter is to control the maximum number of threads for data replication by the datanode node. From the above, we know that the replication priority of the block is divided into 5 types. This parameter controls not including the highest priority block replication. That is, in addition to the highest priority replication flow limit
dfs.namenode.replication.max-streams-hard-limitThis value is apache hadoop default value 2, cdh cluster default value 40
The meaning of this parameter is to control the number of streams copied by all priority blocks of the datanode, including the highest priority; generally the above and the above two parameters are used in conjunction with each other.
Screaming summary: The former parameter controls the frequency at which the datanode accepts tasks, and the latter two parameters further limit the maximum parallel thread network transmission volume completed by the DataNode at one time. The specific value of the above parameters depends on the size of the cluster and the configuration of the cluster, and cannot be discussed in the same way. Generally speaking, it is simpler and easier to control from the entrance. For example, if the scale is 5 clusters, dfs.namenode.replication.work.multiplier.per.iteration=10, 5 DataNodes, then the cluster distributes 50 blocks per heartbeat. If the cluster file storage is all scattered among 5 nodes, each Nodes replicate 10 blocks at the same time (actually, not all nodes will participate in data replication due to copy shelving strategy, rack awareness, etc.), each block size is 128Mb, and the network load of each node is 128*10/3= 546Mb/s, then you have to see whether there will be a bandwidth bottleneck in combination with the actual situation, and whether such a large network IO will affect the calculation of normal tasks. If so, this value should be lowered.
2. How to quickly go offline
The essence of how to make nodes offline quickly is to increase the replication speed of replicas. It is mainly controlled by the above three parameters. The first is to control the distribution of namenode tasks, and the second is to control the replication rate of datanodes, provided that it does not affect the normal production tasks. The smaller the cluster size, the slower the offline, for example because the total number of distributions will be much slower.
The following is the Datanode node:
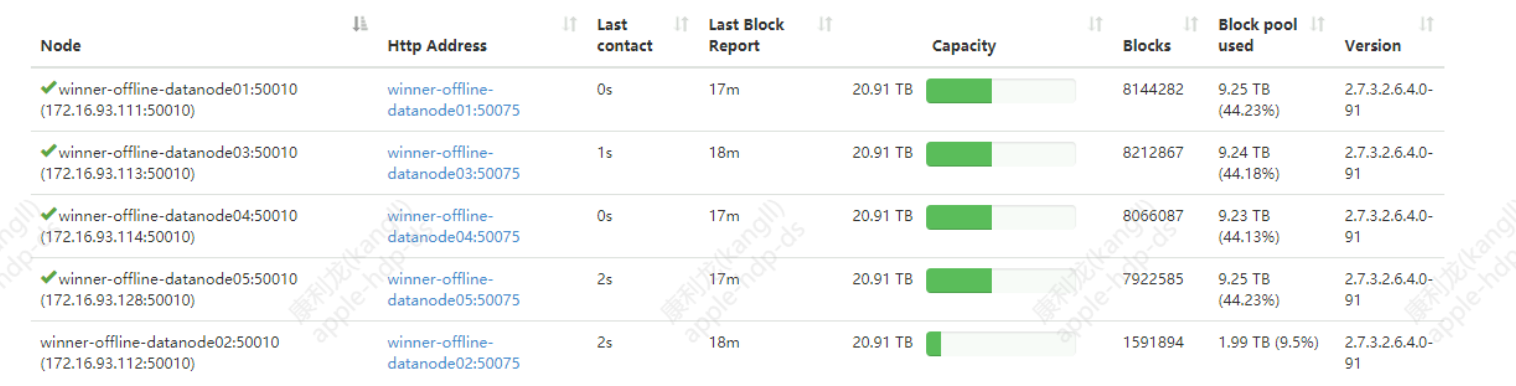
Ambari-web parameter setting:
dfs.namenode.replication.work.multiplier.per.iteration=5
dfs.namenode.replication.max-streams=10
dfs.namenode.replication.max-streams-hard-limit=20The result of the limit calculation:
Task distribution time = total number of blocks to be copied / (cluster active dn * parameter value) * heartbeat time
time=365585/(5*5)=14623 heartbeats*3s/each heartbeat=43870s = about 13 hours
Because the cluster does not process small files in time, the number of blocks is large, and there are only 5 cluster nodes, so decommissioning a Datanode will take a long time to complete block replication, but it is within an acceptable range. If it is a node with relatively many nodes, we will continue to adjust the above parameters.
In the active namenode log, we can see that the number of blocks to be copied each time is 50 blocks, and the total number of bolcks that need to be copied is 344341 and other information.
/var/log/hadoop/hdfs/hadoop-hdfs-namenode-namenode.log
2022-12-15 11:41:15,551 INFO BlockStateChange (UnderReplicatedBlocks.java:chooseUnderReplicatedBlocks(395)) - chooseUnderReplicatedBlocks selected 50 blocks at priority level 2; Total=50 Reset bookmarks? false
2022-12-15 11:41:15,552 INFO BlockStateChange (BlockManager.java:computeReplicationWorkForBlocks(1653)) - BLOCK* neededReplications = 344341, pendingReplications = 67.
2022-12-15 11:41:15,552 INFO blockmanagement.BlockManager (BlockManager.java:computeReplicationWorkForBlocks(1660)) - Blocks chosen but could not be replicated = 10; of which 0 have no target, 10 have no source, 0 are UC, 0 are abandoned, 0 already have enough replicas.
2022-12-15 11:41:15,552 INFO blockmanagement.BlockManager (BlockManager.java:rescanPostponedMisreplicatedBlocks(2121)) - Rescan of postponedMisreplicatedBlocks completed in 0 msecs. 18 blocks are left. 0 blocks were removed.
