Article directory
1.1 Dictionary mdx file resource download
In order to realize the need of error correction for search words, I try to maintain a local dictionary and look for error correction replacement words from it.
First, you need to obtain the dictionary file resource, download it locally, and give the URLs of the two dictionary resources:
Index of /Recommend/Chinese-English Dictionary (Third Edition)/ (freemdict.com)
Oxford / Longman / Collins / Merriam-Webster mdx thesaurus files Mister Fan Studios® (mrfan.org)
If it fails, you can search for the mdx file of the dictionary you need.
1.2 Convert dictionary file to text
Python can directly read mdx files
But it is inconvenient for JAVA to directly process mdx files, so we use conversion tools to convert them into txt files.
The tool name is called: GetDict
I put it in Baidu Netdisk
Link: https://pan.baidu.com/s/1sM6qRIDYeofGef120E9rNQ?pwd=k6g7 Extraction code: k6g7
The running effect is as follows:
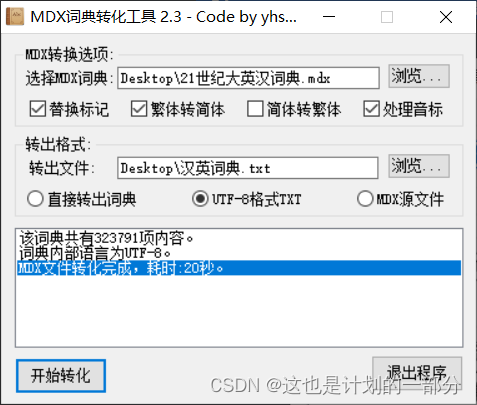
The text file is relatively large in size, and cannot be opened normally with conventional "Notepad", "EXCEL" and "Notepads".
1.3 Dictionary large text processing
The large text file can be opened with Visual Studio Code or EmEditor
Visual Studio Code - Code Editing. Redefined
Download – EmEditor (Text Editor)
Keep clicking Next to complete the installation. After opening the text, we observe the following interface:

Use the replace function to delete the HTML code
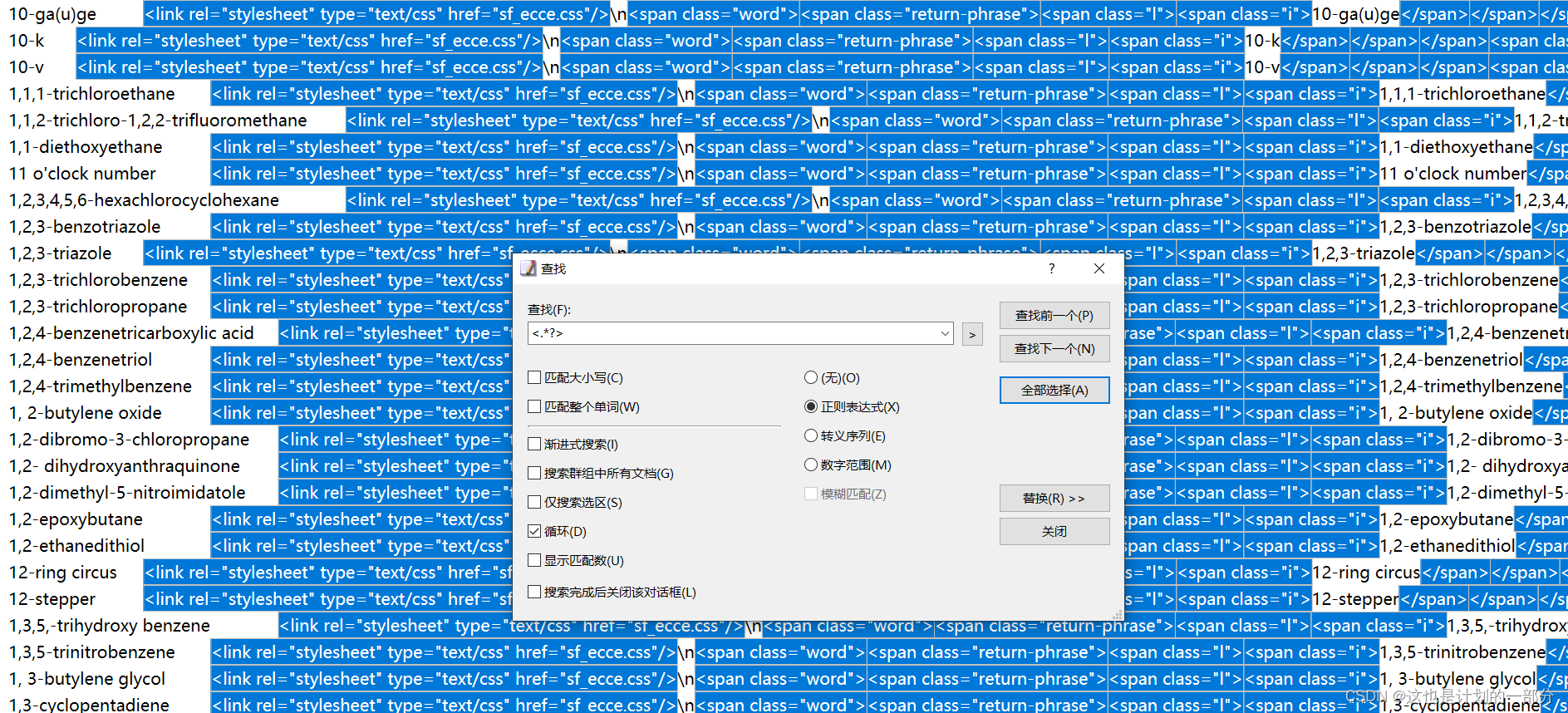
Use the replace function again to remove newlines\n
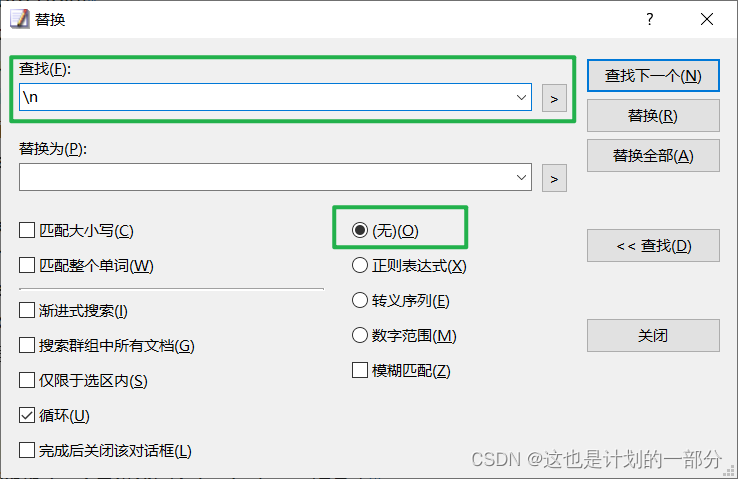
Only the English words and their definitions we need are left.

1.4 Convert dictionary text to database
The number of lines in the dictionary is large, and the query speed needs to be considered. Therefore, it is inconvenient for us to directly query text files and need to build a database.
Converting chaotic text into a logically organized two-dimensional table is also more helpful for our subsequent error detection work.
First split each word of the above dictionary text file into its components

Then processed into SQL statement files to facilitate the rapid establishment of databases

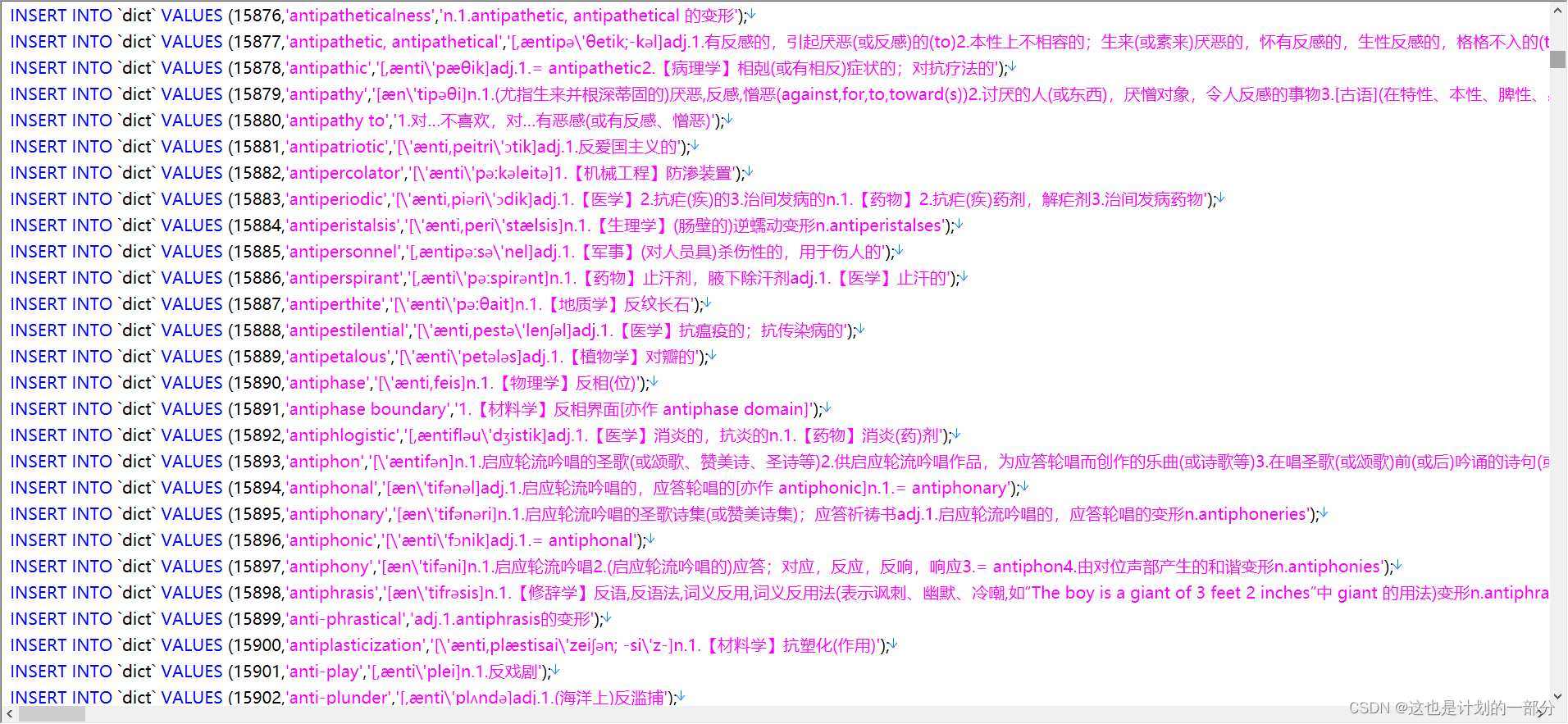
The python code for this part of the process is as follows
# 处理词典文本文件 将其转化为数据库语句
fileHandler = open("21世纪大英汉词典.txt", "r", encoding="utf-8")
listOfLines = fileHandler.readlines()
fileHandler.close()
f = open("dict.sql", "a",encoding="utf-8")
i = 0
for line in listOfLines:
i = i + 1
word_list = line.strip().split("\t")
en = word_list[0]
ch = word_list[1].replace(en, "")
en = en.replace("'", "\\'")
ch = ch.replace("'", "\\'")
print("INSERT INTO `dict` VALUES (" + str(i) + ",'" + en + "','" + ch + "');",file=f)
f.close() # 关闭文件
Execute the statement in dict.sql to complete the establishment of the dictionary table,
It takes a long time here. If the computer is slow, it will take about 40mins to run.
Maybe it will be faster to process it with Python, I haven't tried it again.
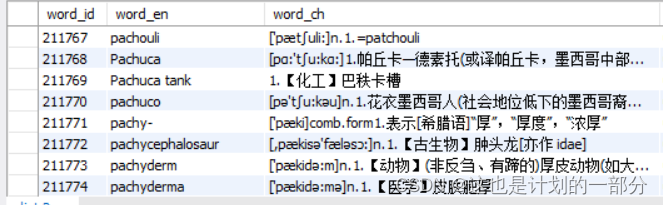
The results are as follows, a total of 323791 records:
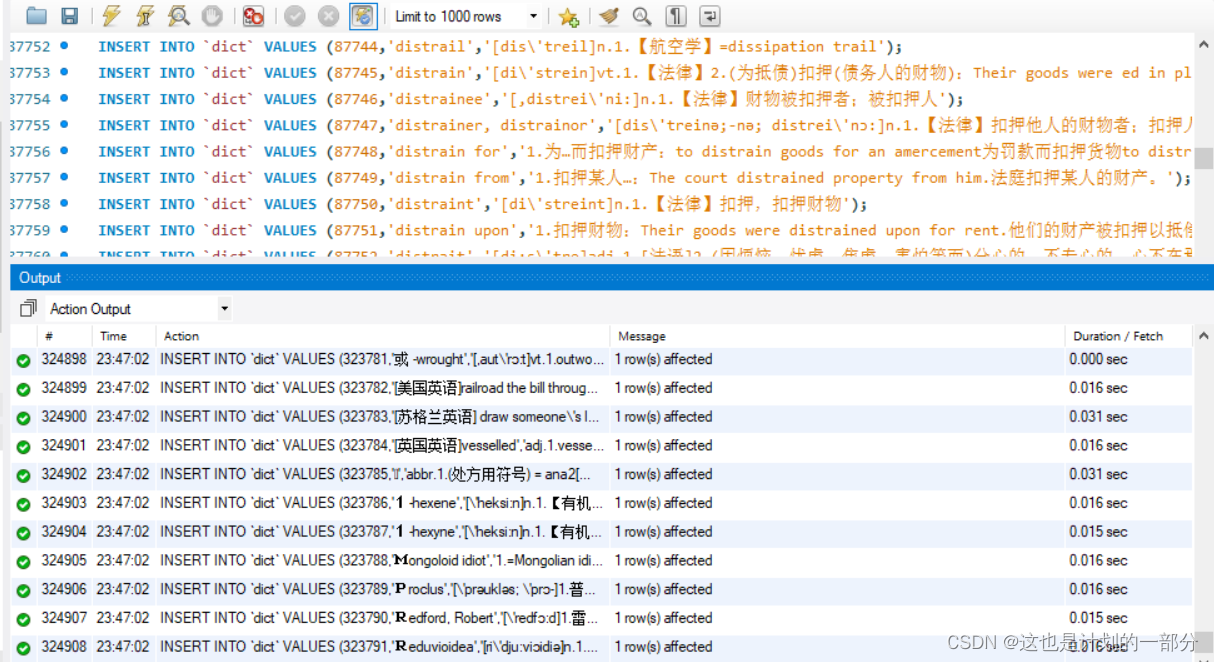
1.5 Dictionary database query
After the database is established, the query is much more efficient
Such as querying all words/phrases beginning with the letter p
SELECT * FROM `dict` where word_en like 'p%';