
origin
ChatGPT has been popular since the end of last year. Everyone is thinking about how to use the ability of ChatGPT to build their own applications. I am also thinking, if there is a robot that can learn the information in the open source project documentation, can it be used as an open source project? What about project Q&A bots?
This idea has been in my mind until I saw that someone has implemented it, that is, DocsGPT. This project has been open source and has gained 3000+ stars in one month.
I also wanted to try it myself, so I deployed an instance of myself according to the documentation, and added some project documentation. If you are interested, you can visit OSS-GPT to try it out and see how it works.
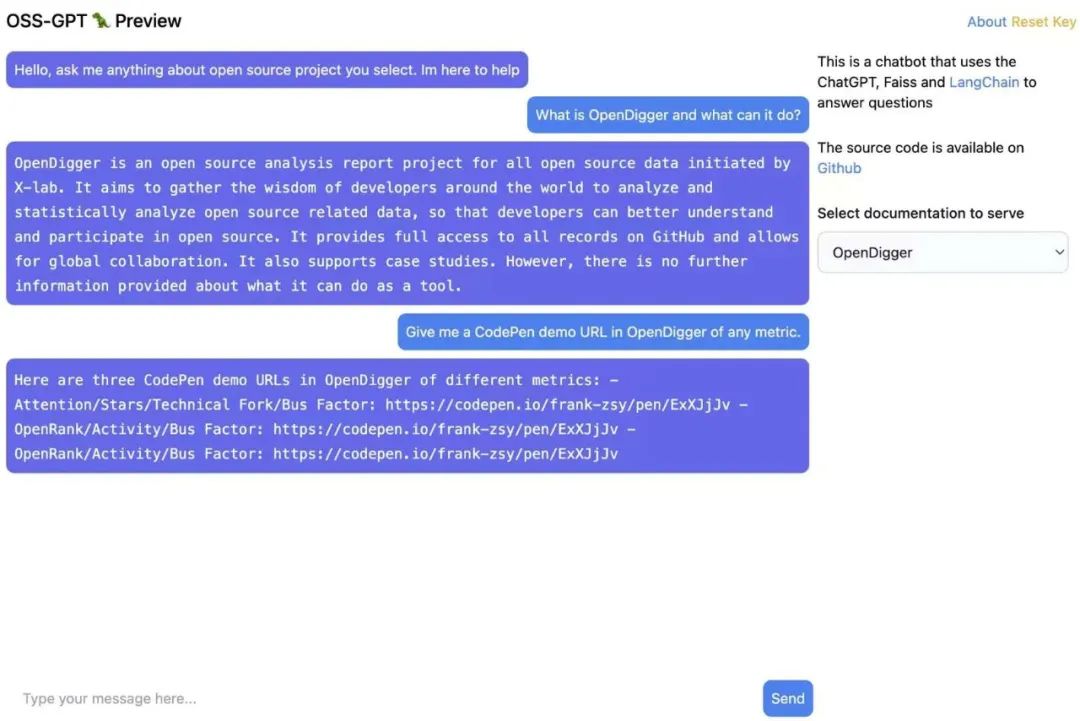
Question answering performance of OpenDigger documents in DocsGPT. Currently supported projects include:
OpenDigger,OpenYurt,Egg.js,Midway.js,NebulaGraph,OceanBase,OpenSumi etc.
get to the bottom
After training several familiar project documents according to the DocsGPT Wiki, I also sent them to the person in charge of the corresponding community for a trial. I found that the effect was not satisfactory, and sometimes it was quite mentally retarded, so I wanted to explore the specific principles behind it.
How to use ChatGPT
When it comes to the specific implementation method, we must first mention how ChatGPT is used and what limitations it has.
ChatGPT provides a very simple API interface that can be used for chat tasks. The bottom layer uses the gpt-3.5-turbo large model. The training data used by this model itself is older Internet information (as of 2021.9), so it does not Doesn't have some newer information, let alone non-public information.
Therefore, ChatGPT provides a method of prompts through prompts, that is, when a request is made, a piece of information can be brought. Since it is a chat interface, it can contain multiple chat contents. It includes hints from the system: for example, to describe what role ChatGPT is now, what language style it should have, etc. In addition, it can also include some users' historical chat records, such as background knowledge, which can be brought in as user input, so that ChatGPT can have domain knowledge and context information in this chat. Through this method of prompts, ChatGPT can be customized to a certain extent, and the natural language ability of its large model can be used to organize answer information.
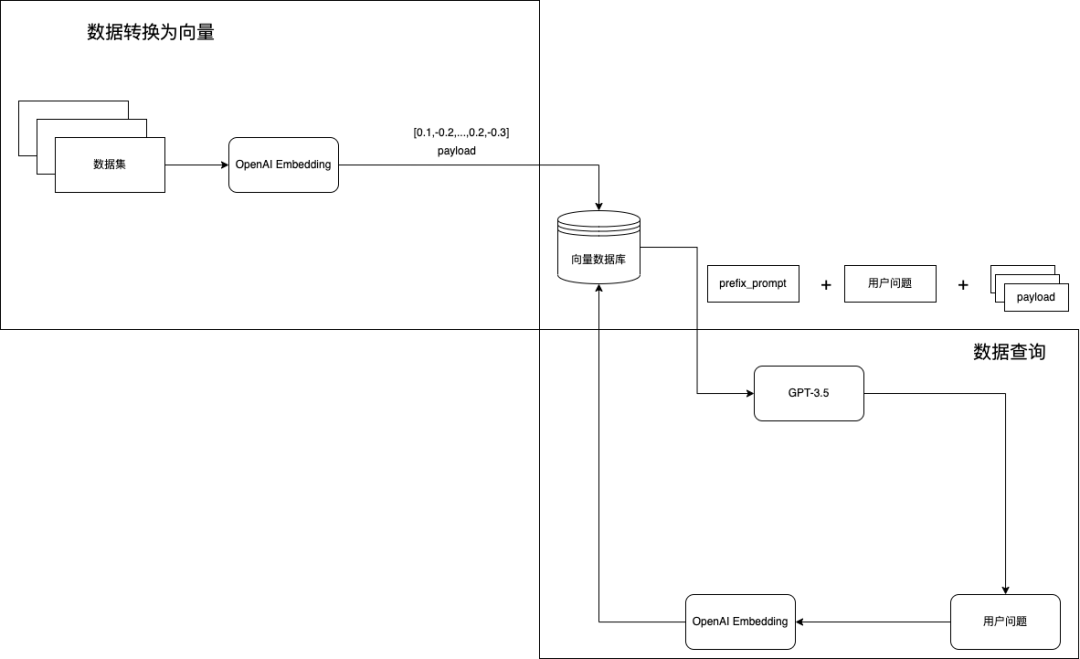
The above is the basic principle of chatbots in the field of ChatGPT. In addition to DocsGPT, the recently open-source project document.ai uses a similar method. The basic process of this method is:
Vectorize and store all input document data
When chatting, query the content of the document that is most similar to the current chat content in the stored vector data
Send the above document content as part of the prompts together with the chat content to ChatGPT for Q&A
This also completes the injection of information in a specific field. If you want to achieve the effect of chat context, you can also bring the previous chat content together, so you can have context information.
Here is the flowchart from the document.ai project:
Limitations of ChatGPT
But in fact, the limitation of this method based on pre-retrieval and prompts is also here.
Because the underlying ChatGPT model is a general model, and OpenAI does not open the fine-tune capability of the gpt-3.5-turbo model, which means that we cannot train our own exclusive model through fine-tune, we can only do it through prompts hint.
The prompts themselves have certain limitations. The ChatGPT interface has a max_tokens limit of 4096, and this limit refers to the total amount of prompts plus answers. Therefore, we cannot bring too much information in prompts, and if we want to bring chat context information , the amount of pre-retrieved data will be smaller. This also limits the accuracy of ChatGPT.
The following is the official website description about the gpt-3.5-turbo model, including the restrictions on tokens and the time interval of the data set:

try
So I was thinking, can I use a fine-tune model to train my own exclusive model? In this way, background knowledge prompts are no longer needed during the conversation, because the background knowledge has been integrated into this exclusive model, and contextual information can be brought in at most multiple rounds of chatting, which can make the answer more intelligent.
Since the gpt-3.5-turbo model does not provide fine-tune capabilities, we can use GPT-3 models, such as text-davinci-003, for fine-tune. As mentioned in OpenAI's official website homepage and documentation, the two models are very close in performance, but the cost of the gpt-3.5-turbo model is 10% of the davinci model, so it is recommended that you use the former.
So the next question is how do we use our own document data to train a dedicated model? Because the fine-tune method of the davinci model needs to input a set of prompt and completion text pairs, the prompt can be a question or a sentence to fill in the blanks, and the completion is the answer to the question or the supplement to fill in the blanks. So we need to convert the project documentation into a similar form.
At this point we can go back to ChatGPT, because it has a very good reading comprehension ability, and it works well for this type of text task. So we can first split our document into pieces of information, and then feed it to ChatGPT to convert the information into factual question and answer pairs, and return them in JSON form. When all the documents are split, it becomes a large number of prompts data based on the factual information of the project.
Then send these prompts data to OpenAI's interface to train a dedicated model based on davinci's basic model. After the model is trained, you can try to chat with your own dedicated model.
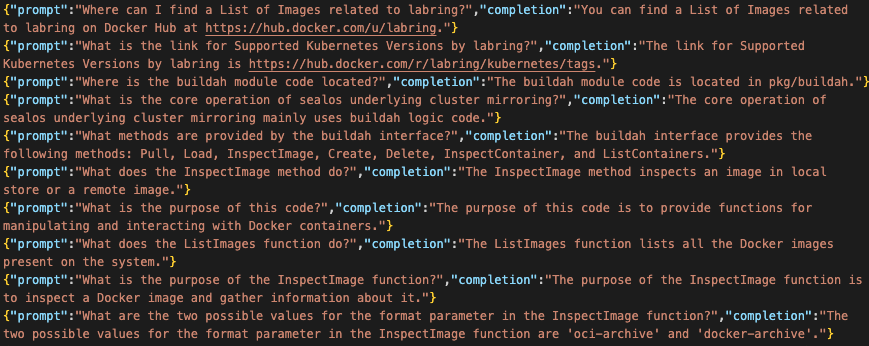
Using the 89 Markdown files in the official document of Sealos, we got 1502 question and answer pairs. Some examples of prompts are as follows, which looks very good:
Compared
cost
In fact, the biggest comparison is the cost comparison. Since ChatGPT does not have fine-tune, the cost is only the cost of each question and answer. See prompts with thousands of characters for a short question.
The training cost of davinci's fine-tune model is relatively high. The training of the Sealos document has input more than 250,000 tokens into the exclusive model. The training time is about 1 hour and the cost is 8 US dollars. But once the exclusive model is obtained, there is no need to do pre-retrieval and background knowledge prompts in subsequent chats, and you can directly conduct knowledge questions and answers about this field. Not only will the token consumption be smaller, but the speed will also be faster.
The exclusive model of the Sealos 4.0 document is davinci:ft-personal:sealos-doc-2023-03-11-13-00-02 , students who are interested can try it, I am not sure if it is available for everyone.
Effect
Here I compare the effect of DocsGPT and a simple fine-tune model under OpenDigger.
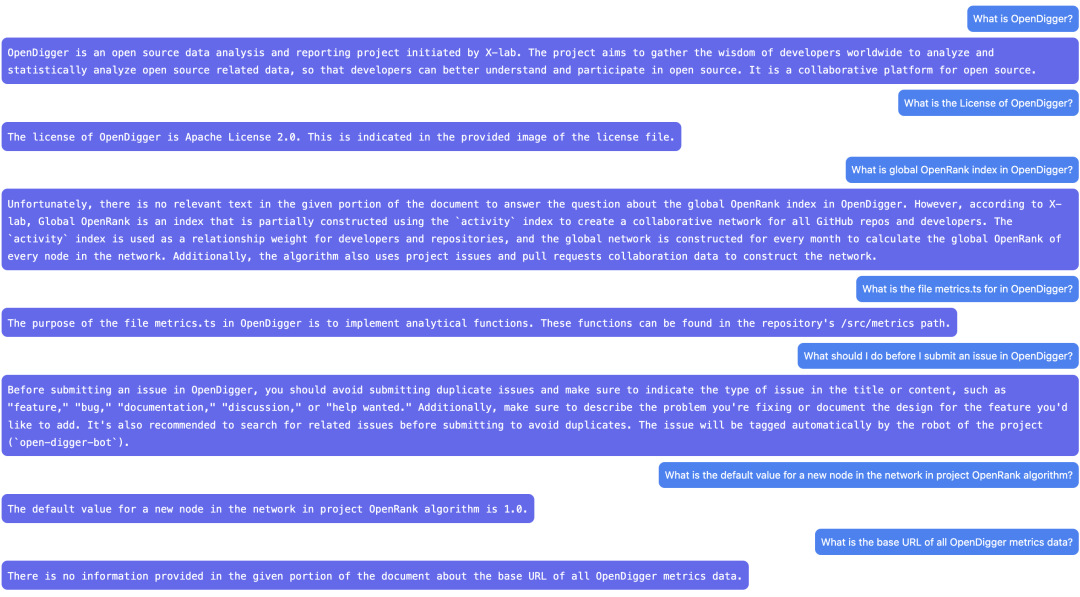
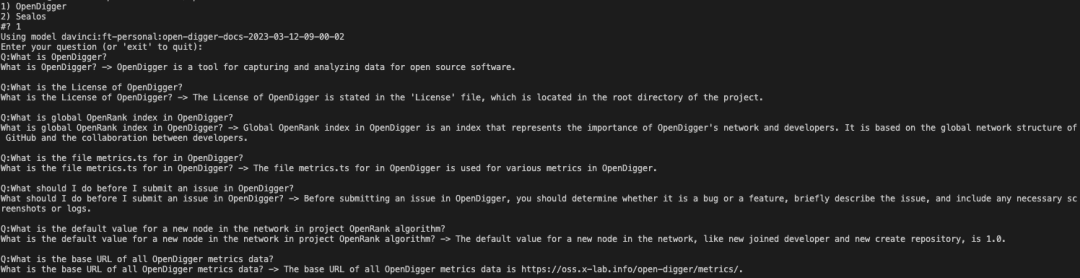
The first one is the effect of DocsGPT, and the second one is the effect of the davinci fine-tune model. It can be seen that both performances are not bad, but there are also obvious differences: the results based on ChatGPT look better because it has better language capabilities, and even does some extensions and extensions, although some are wrong. The answer of the exclusive model is more concise, and has a greater relationship with prompts, so it has more details.
Since the answers of the proprietary model are very correlated with the quality of the prompts, better training data will definitely make it perform better. At present, only the simplest ChatGPT is used, and the given tasks may not be good enough, so there is room for improvement in the results. But it can be seen that ChatGPT's understanding of text is still very strong, especially for some structured text, such as the understanding of tables. If we further optimize the logic of constructing the prompts data in the first step, and add some manual adjustments and corrections, the effect should be better.
future
In fact, there are really many possibilities based on large models. If you have imagination, you can do too many things. For example, you can use your own thoughts and blogs as input to train a model that contains your own ideas, and then give it a position. Imitate people to communicate, then you can get a virtual person of yours. In many cases, KOLs in the field can interact with fans in this way. Fans can directly ask questions and communicate with his thoughts.
For those who are not good at writing, they can output their own ideas in the form of simple question-and-answer pairs to train their own exclusive robots, and then cooperate with the language and logic capabilities of the large model itself to help them write articles containing their own thoughts. It should be very good. train of thought.
For a beginner who has never done machine learning training by himself before, he has made some attempts with great interest in the past few days, and the results are quite amazing. Students who are interested in prompts engineering are also welcome to share their experiences.
Author丨Frank
Editor丨Wang Mengyu
Related Reading| Related Reading

The Future of Open Source: Launch Open100 Measures Driving OSS Adoption in New Markets
 Finding Robots: Why We Shouldn't 'Hide Humans'
Finding Robots: Why We Shouldn't 'Hide Humans'
Introduction to Kaiyuanshe
Founded in 2014, Kaiyuan Society is composed of individual members who voluntarily contribute to the cause of open source. It is formed according to the principle of "contribution, consensus, and co-governance". It has always maintained the characteristics of vendor neutrality, public welfare, and non-profit. International integration, community development, project incubation" is an open source community federation with the mission. Kaiyuanshe actively cooperates closely with communities, enterprises and government-related units that support open source. With the vision of "Based in China and Contributing to the World", it aims to create a healthy and sustainable open source ecosystem and promote China's open source community to become an active force in the global open source system. Participation and Contributors.
In 2017, Kaiyuanshe was transformed into an organization composed entirely of individual members, operating with reference to the governance model of top international open source foundations such as ASF. In the past nine years, it has connected tens of thousands of open source people, gathered thousands of community members and volunteers, hundreds of lecturers at home and abroad, and cooperated with hundreds of sponsors, media, and community partners.
