
Preface
The LLM model is very popular recently, and the breadth of knowledge covered by chatGPT is breathtaking. However, coders must not be satisfied with the existing knowledge base. They must expand their own data to achieve greater practical value.
Generally speaking, deep learning models mostly use finetune to increase training data, but the LLM model is too large and the training cost is too high. Whether it is offline or online training samples, only OpenAI can do it in a short time. With the rise of general large models, another prompt project (prompt) called "preamble injection" has gradually matured and can also access its own data.
This article mainly uses the latter method to convert software development documents into vector data, and then uses chatGPT to build a better Q&A interactive experience, using powerful inductive search capabilities to greatly improve the efficiency of information acquisition.

Environmental preparation
Install python 3.8
conda create -n chat python=3.8
conda activate chatConfigure jupyter environment
conda install ipykernel
python -m ipykernel install --user --name chat --display-name "chat"Install pytorch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116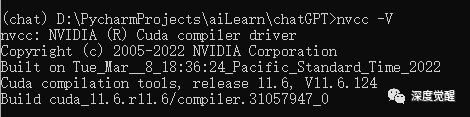
Pay attention to version matching here. The version used on my laptop is CUDA 11.6. If the graphics card is not powerful enough, you can also install the CPU version.
Install dependencies
pip install langchain
pip install unstructured
pip install openai
pip install pybind11
pip install chromadb
pip install Cython
pip3 install "git+https://github.com/philferriere/cocoapi.git#egg=pycocotools&subdirectory=PythonAPI"
pip install unstructured[local-inference]
pip install layoutparser[layoutmodels,tesseract]
pip install pytesseractInstall and compile detectron2
git clone https://github.com/facebookresearch/detectron2.git
python -m pip install -e detectron2
Since detectron2 needs to be compiled from source code in a Windows environment, there are a few pitfalls to be aware of:
pdf2image error
pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
https://github.com/oschwartz10612/poppler-windows/releases/Download poppler and add environment variables.
pdfminer conflicts with pdfminer.six version
'LTChar' object has no attribute 'graphicstate' Error in a docker containerIt can be repaired by uninstalling pdfminer and pdfminer.six and reinstalling them.
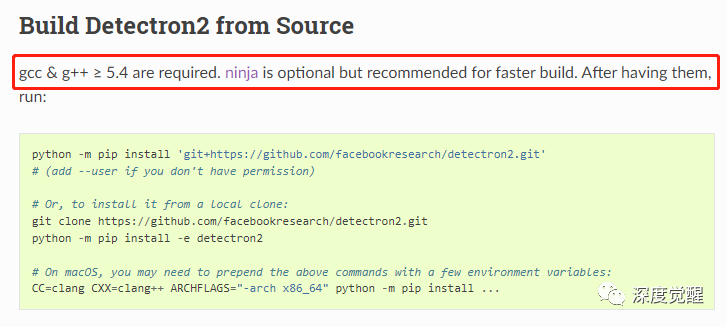
gcc and ninja
gcc needs to be configured during the compilation process. I use MinGW here, and ninja is not optional under windows (otherwise the compilation will not pass) and needs to be placed under Path. (There are relevant file download links at the end of the article)
Prepare training data
Place the pdf document in the /text directory. Multiple files can be placed. The audio and video development document meeting.pdf is used here.
jupyter notebook
import os
os.environ['OPENAI_API_KEY'] = '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'Everything is ready, let's configure OpenAI's api key. (I’ll omit 10,000 steps here. The difficulty of applying for ChatGPT has recently increased a lot. It seems that the prostitutes are putting a lot of pressure on OpenAI’s computing power~~, plus also rejects international credit cards issued in China. In short, it is very annoying)
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.indexes import VectorstoreIndexCreatorConfigure training to use gpu or cpu
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.MODEL.DEVICE = 'gpu' #GPU is recommendedImport custom data into loader
text_folder = 'text'
loaders = [UnstructuredPDFLoader(os.path.join(text_folder, fn)) for fn in os.listdir(text_folder)]
training data
Text vectorization and access to ChatGPT
index = VectorstoreIndexCreator().from_loaders(loaders)Since the development file is very small (169k), it only takes less than 1 minute to complete the training on my 1060 graphics card, and the CPU will be slightly slower.

The cost of using the API is also very low, and the free quota is enough for more than 100 uses. Heavy users may want to consider the plus version.
Q&A effect
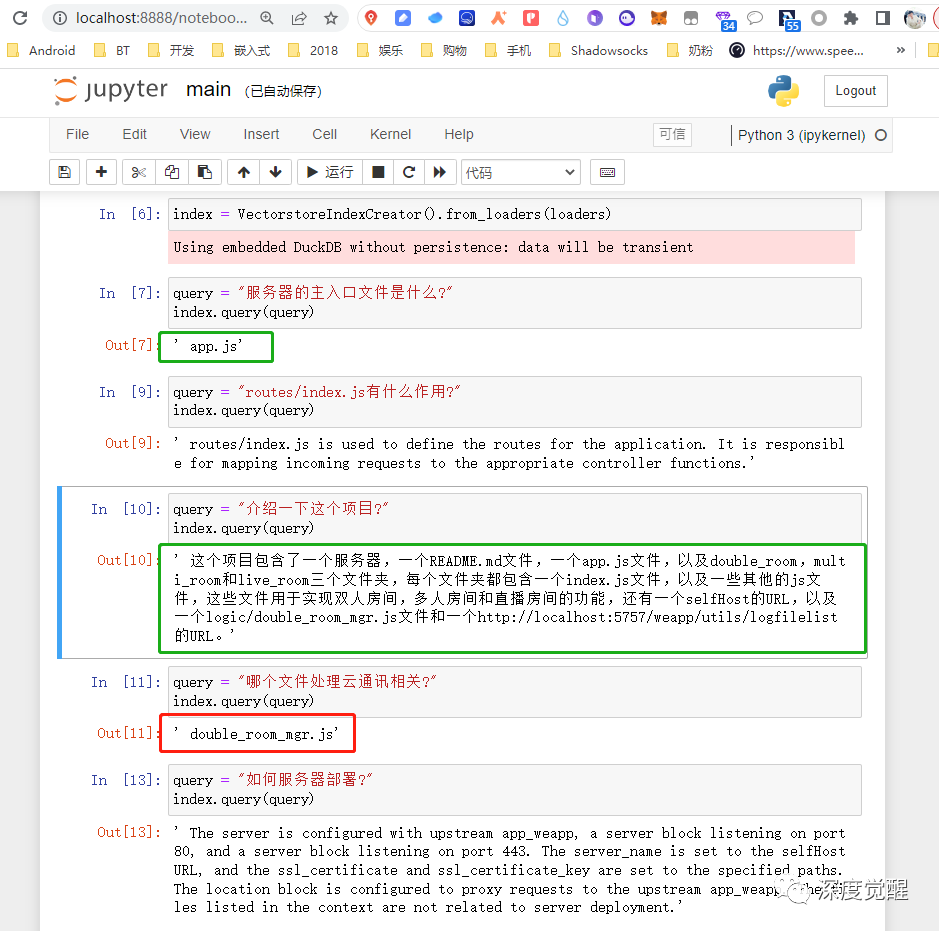
What is the main entry file of the server?
query = "服务器的主入口文件是什么?"
index.query(query)' app.js'

This question is relatively simple and the answer can be found directly in the text. The answer is correct.
What does routes/index.js do?
query = "routes/index.js有什么作用?"
index.query(query)' routes/index.js is used to define the routes for the application. It is responsible for mapping incoming requests to the appropriate controller functions.'
This question is obviously not described in detail in the document, and only the routing definition file is mentioned. The answer is most likely a supplementary explanation made by ChatGPT.
Please introduce this project?
query = "介绍一下这个项目?"
index.query(query)' 这个项目包含了一个服务器,一个README.md文件,一个app.js文件,以及double_room,multi_room和live_room三个文件夹,每个文件夹都包含一个index.js文件,以及一些其他的js文件,这些文件用于实现双人房间,多人房间和直播房间的功能,还有一个selfHost的URL,以及一个logic/double_room_mgr.js文件和一个http://localhost:5757/weapp/utils/logfilelist的URL。'
This is an inductive question. Apparently ChatGPT summarized it pretty well after reading the full text.
Which document deals with cloud communications?
query = "哪个文件处理云通讯相关?"
index.query(query)' double_room_mgr.js'
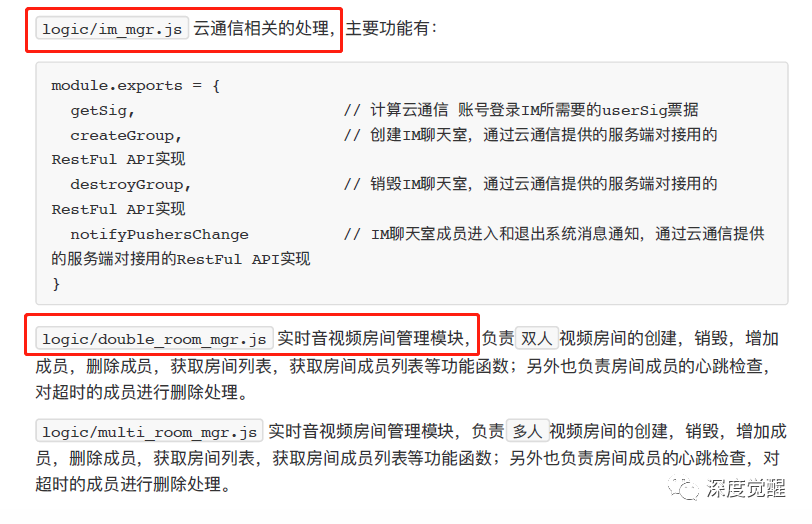
The chat teacher "overturned" this question. It may be that the "relevant" in the question caused ambiguity in the Chinese context, and the file of the next module was regarded as the answer.
How to deploy the server?
query = "如何服务器部署?"
index.query(query)' The server is configured with upstream app_weapp, a server block listening on port 80, and a server block listening on port 443. The server_name is set to the selfHost URL, and the ssl_certificate and ssl_certificate_key are set to the specified paths. The location block is configured to proxy requests to the upstream app_weapp. The files listed in the context are not related to server deployment.'
For content that is not in the document, ChatGPT started to let it go, and Yaya published a lot of correct nonsense.
The overall effect is still amazing, far beyond my imagination, especially the ability to summarize. As for the search positioning function, for developing documents, we coders may be accustomed to using keyword matching to search more efficiently, but in the field of fuzzy search, this is actually where chat teachers really come into play.
You can imagine some usage scenarios, read through personal novels, and summarize character relationships and story lines; extract the style of copywriting and apply it to your own products; read various financial research reports and give investment suggestions. . .
"In the future, we need someone who can ask questions, a large enough basic language model, and a professional enough guidance document. This is how vertical domain experts were born!"
Outlook and improvements
In this article, it will take a long time to construct text into vector data each time (especially if the CPU method is used). If this part of the work can be completed using a vector database, the speed will be improved by several orders of magnitude.
In view of the current unfriendly service of chatGPT in China, we are still looking forward to similar Baidu's "Wen Xin Yi Yan", Alibaba's "Tong Yi Qian Wen", including iFlytek's large language model to mature as soon as possible. Subsequent changes to the API interface can switch between different services. If the computing power problem is not a bottleneck in the future, you can even consider building your own language model for localized deployment. This will be a strong competitor for knowledge graph applications.
❝ps: I want to complain about Lenovo’s after-sales service. I originally wanted to use stable diffusion to generate the title picture, but it turned out that my 3090 training machine was repaired from "CPU downclocking fault" to "motherboard burnt CPU", and no one can...
Use Wen Xinyiyan to temporarily support it, and the effect is not bad. Come on, domestically produced large models!
❞
Source code download
Relevant documents and information for this issue can be found on the public account "Deep Awakening" and reply: "chat01" in the background to obtain the download link.
