PaddleDetection/pphuman_mot.md at release/2.6 · PaddlePaddle/PaddleDetection · GitHubObject Detection toolkit based on PaddlePaddle. It supports object detection, instance segmentation, multiple object tracking and real-time multi-person keypoint detection. - PaddleDetection/pphuman_mot.md at release/2.6 · PaddlePaddle/PaddleDetection https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/deploy/pipeline/docs/tutorials/pphuman_mot.mdGitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021) - GitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)https://github.com/JialeCao001/PedSurvey pedestrian detection review_denghe1122's blog-CSDN blog PART Ifrom: http://www.cnblogs.com/molakejin/p/5708791.htmlPedestrian detection has a wide range of applications: intelligence Assisted driving, intelligent monitoring, pedestrian analysis and intelligent robots and other fields. Pedestrian detection has entered a rapid development stage since 2005, but there are still many problems to be solved, mainly in terms of performance and speed. In recent years, the research and development of autonomous driving technology led by Google is in full swing, which also forces
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.6/deploy/pipeline/docs/tutorials/pphuman_mot.mdGitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021) - GitHub - JialeCao001/PedSurvey: From Handcrafted to Deep Features for Pedestrian Detection: A Survey (TPAMI 2021)https://github.com/JialeCao001/PedSurvey pedestrian detection review_denghe1122's blog-CSDN blog PART Ifrom: http://www.cnblogs.com/molakejin/p/5708791.htmlPedestrian detection has a wide range of applications: intelligence Assisted driving, intelligent monitoring, pedestrian analysis and intelligent robots and other fields. Pedestrian detection has entered a rapid development stage since 2005, but there are still many problems to be solved, mainly in terms of performance and speed. In recent years, the research and development of autonomous driving technology led by Google is in full swing, which also forces https://blog.csdn.net/denghecsdn/article/details/77987627 to realize people flow statistics based on FairMOT- Flying Paddle AI Studio This project is based on PaddleDetection FairMOT realizes people flow statistics in dynamic and static scenes, and provides guidance on the whole process from "model selection → model optimization → model deployment". The model can be used for related tasks directly or after fine-tuning with a small amount of data. - Flying Paddle AI Studio
 https://aistudio.baidu.com/aistudio/projectdetail/2421822?channelType=0&channel=0 VOC-COCO-MOT20 - Flying Paddle AI Studio VOC-COCO-MOT20 - Flying Paddle AI Studio https:// aistudio.baidu.com/aistudio/datasetdetail/47128
https://aistudio.baidu.com/aistudio/projectdetail/2421822?channelType=0&channel=0 VOC-COCO-MOT20 - Flying Paddle AI Studio VOC-COCO-MOT20 - Flying Paddle AI Studio https:// aistudio.baidu.com/aistudio/datasetdetail/47128
Time Work Technology-China's Leading Business Digital Intelligence Service Provider- Time Work Technology Time Work Technology-China's Leading Business Data Intelligence Service Providerhttps ://www.timework.cn/col.jsp? id=157 YOLOv5 Train your own data set (super detailed)_yolo data set_AI follower's blog-CSDN blog 1. Prepare the deep learning environment My laptop system is: Windows10 first enter the YOLOv5 open source website, manually download zip or git clone remote warehouse , I downloaded the 5.0 version code of YOLOv5, and there will be a requirements.txt file in the code folder, which describes the required installation package. The final version of pytorch installed in this article is 1.8.1, the version of torchvision is 0.9.1, and the version of python is 3.7.10. Other dependent libraries can be installed according to the requirements.txt file. ...
https://blog.csdn.net/qq_40716944/article/details/118188085
This project is derived from a video surveillance project with a background of bright kitchen and bright stove. It is intended to use the yolov5 algorithm to identify whether there are people in the kitchen.
1. Dataset
The current datasets for pedestrian detection include coco_person, voc_person, mot20/16, 17, CrowdHuman , HIEVE , Caltech Pedestrian, CityPersons, CHUK-SYSU, PRW, ETHZ.
2. Data processing
Using the coco-voc-mot20 dataset, there are a total of 41,856 images, including 37,736 images for training data, 3,282 images for verification data, and 838 images for test data.
2.1 Convert the train/val/test in the above data into txt containing pictures.
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='/home/imcs/local_disk/D0011/Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='dataSet', type=str, help='output txt label path')
opt = parser.parse_args([])
trainval_percent = 0.98 # 剩下的0.02就是测试集
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in tqdm(list_index):
# import pdb;pdb.set_trace()
name = Path(total_xml[i]).stem + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
2.2 Convert xml data to yolo data format
sets = ['train', 'val', 'test']
classes = ["person"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(abs_path+'/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open(abs_path+'/Yolo/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
try:
difficult = obj.find('Difficult').text
except:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in tqdm(sets):
image_ids = [line.strip() for line in open('./dataSet/%s.txt' % (image_set)).readlines()]
list_file = open('%s_yolo.txt' % (image_set), 'w')
for image_id in image_ids:
try:
list_file.write(abs_path + '/JPEGImages/%s.jpg\n' % (image_id))
convert_annotation(image_id)
except:
continue
list_file.close()2.3 Change the dataset name
../datasets/coco128/images/im0.jpg # image ../datasets/coco128/labels/im0.txt # label
Yolo will automatically replace the image with labels and find the label name, so the data set name should be replaced with labels and images.
3. Environment installation
python3.7 cuda10.1
pip install -r requirements
torch==1.8.1_cu101
torchvision==0.9.1_cu101
tqdm==4.64.0
top==0.1.1
Upgrade glic/libstdc++.so.6
4. Model
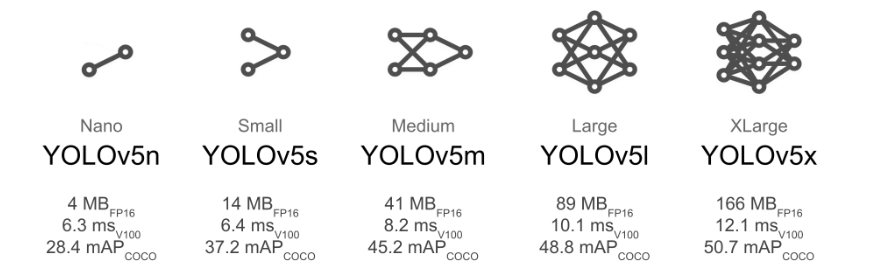
Generally, if you consider deploying on the end side, use yolov5s
4.1 Create a new person.yaml under data
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/imcs/local_disk/D0011 # dataset root dir
train: train_yolo.txt # train images (relative to 'path') 118287 images
val: val_yolo.txt # val images (relative to 'path') 5000 images
test: test_yolo.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 1 # number of classes
names: ['person'] # class names4.2 In the models update yolov5s.yaml, change nc to category.
4.3 Distributed Training
python -m torch.distributed.launch --nproc_per_node 4 train.pybatch_size=32, the code of yolov5 is well written, even on k80, no major changes are required.
5. Test