
Author: Earth Dog Thirsting for Strength
Blog homepage: blog homepage of a power-hungry dirt dog
Column: Data Structures and Algorithms
If a worker wants to do a good job, he must first sharpen his tool. Let me introduce a super awesome tool to win the offer of a big factory——Niuke.com
Table of contents
2.3 Description of common methods of Map
3.1 Description of common methods
4.4 Conflict - Methods of Avoidance
4.5 Conflict-avoidance-load factor adjustment (emphasis on mastering)
4.7 Collision-resolution-closed hashing
4.8 Conflict-Resolution-Open Hash/Hash Bucket (Key Mastery)
5. Hash table search success and search failure method
5.1 Find a successful solution
1. Introduction to map&set
1.1 Concept and Scenario
Map and set are containers or data structures designed for searching. Map and Set are collection containers suitable for dynamic lookup.
1.2 Model
Generally, the searched data is called a key (Key), and the corresponding key is called a value (Value), which is called a Key-value key-value pair, so there are two types of models: 1. Pure key
model , for example:
there is an English dictionary, quickly find whether a word is in the dictionary,
quickly find whether a name is in the address book
2. Key-Value model, for example:
count the number of occurrences of each word in the file, the statistical result is each Each word has its corresponding number of times: <word, the number of times the word appears>
and the key-value pair is stored in the Map, and only the Key is stored in the Set.
2. Use of Map
2.1 Explanation about Map
Map is an interface class. This class does not inherit from Collection. This class stores key-value pairs of <K, V> structure, and K must be unique and cannot be repeated.
2.2 Explanation about Map.Entry<K, V>
Map.Entry<K, V> is an internal class implemented inside Map to store the mapping relationship between <key, value> key-value pairs. This internal class mainly provides the acquisition of <key, value>, the setting of value and Key way of comparison.
| method | explain |
| K getKey() | Return the key in the entry |
| V getValue() | Return the value in the entry |
| V setValue(V value) | Replace the value in the key-value pair with the specified value |
Note: Map.Entry<K,V> does not provide a method to set Key
2.3 Description of common methods of Map
| method | explain |
| V get(Object key) | Return the value corresponding to the key |
| V getOrDefault(Object key, V defaultValue) | Return the value corresponding to the key, if the key does not exist, return the default value |
| V put(K key, V value) | Set the value corresponding to the key |
| V remove(Object key) | Delete the mapping relationship corresponding to the key |
| Set<K> keySet() | Returns a unique set of all keys |
| Collection<V> values() | Returns a iterable collection of all values |
| Set<Map.Entry<K, V>> entrySet() | Return all key-value mappings |
| boolean containsKey(Object key) | Determine whether to contain the key |
| boolean containsValue(Object value) | Determine whether to contain value |
Note:
1. Map is an interface, and objects cannot be instantiated directly. If you want to instantiate an object, you can only instantiate its implementation class TreeMap or HashMap
2. The key storing the key-value pair in the Map is unique, and the value can be
repeated3 . The Keys in the Map can all be separated and stored in the Set for access (because the Key cannot be repeated).
4. All the values in the Map can be separated and stored in any sub-collection of the Collection (values may be duplicated).
5. The key of the key-value pair in the Map cannot be modified directly, but the value can be modified. If you want to modify the key, you can only delete the key first, and then reinsert it
.
6. The difference between TreeMap and HashMap
| Map underlying structure | TreeMap | HashMap |
| underlying structure | red black tree | hash bucket |
| Insertion/deletion/find time complexity |
O(1) | |
| Is it in order | About Key Order | out of order |
| thread safety | unsafe | unsafe |
| insert/delete/find difference | element comparison is required | Calculate the hash address through the hash function |
| compare and override | The key must be comparable, otherwise a ClassCastException will be thrown |
Custom types need to override the equals and hashCode methods |
| Application Scenario | In the scene where keys are required to be ordered | It doesn't matter whether the key is in order or not, it needs higher time performance |
3. Description of Set
There are two main differences between Set and Map: Set is an interface class inherited from Collection, and only Key is stored in Set
3.1 Description of common methods
| method | explain |
| boolean add(E e) | Add elements, but duplicate elements will not be added successfully |
| void clear() | empty collection |
| boolean contains(Object o) | Determine whether o is in the set |
| Iterator<E> iterator() | return iterator |
| boolean remove(Object o) | delete o from the set |
| int size() | Returns the number of elements in the set |
| boolean isEmpty() | Check whether the set is empty, return true if empty, otherwise return false |
| Object[] toArray() | Convert the elements in the set to an array and return |
| boolean containsAll(Collection<?> c) | Whether all the elements in the set c exist in the set, return true, otherwise return false |
| boolean addAll(Collection<? extends E> c) |
Adding the elements in the set c to the set can achieve the effect of deduplication |
Note:
1. Set is an interface class inherited from Collection
2. Only key is stored in Set, and the key must be unique
3. The underlying layer of Set is implemented using Map, which uses a default object of key and Object as The key-value pair is inserted into the Map.
4. The biggest function of Set is to deduplicate the elements in the set.
5. The common classes that implement the Set interface are TreeSet and HashSet, and there is also a LinkedHashSet. LinkedHashSet is
maintained on the basis of HashSet A doubly linked list to record the insertion order of elements.
6. The Key in the Set cannot be modified. If you want to modify it, delete the original one first, and then reinsert it.
7. You cannot insert a null key in the Set.
8. The difference between TreeSet and HashSet
| Set underlying structure | TreeSet | HashSet |
| underlying structure | red black tree | hash bucket |
| Insertion/deletion/find time complexity |
O(1) | |
| Is it in order | About Key Order | not necessarily orderly |
| thread safety | unsafe | unsafe |
| insert/delete/find difference | 按照红黑树的特性来进行插入和删除 | 1. 先计算key哈希地址 2. 然后进行 插入和删除 |
| 比较与覆写 | key必须能够比较,否则会抛出 ClassCastException异常 |
自定义类型需要覆写equals和 hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的 时间性能 |
4. 哈希表
4.1 概念
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:插入元素,根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。搜索元素,对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(HashTable)(或者称散列表)
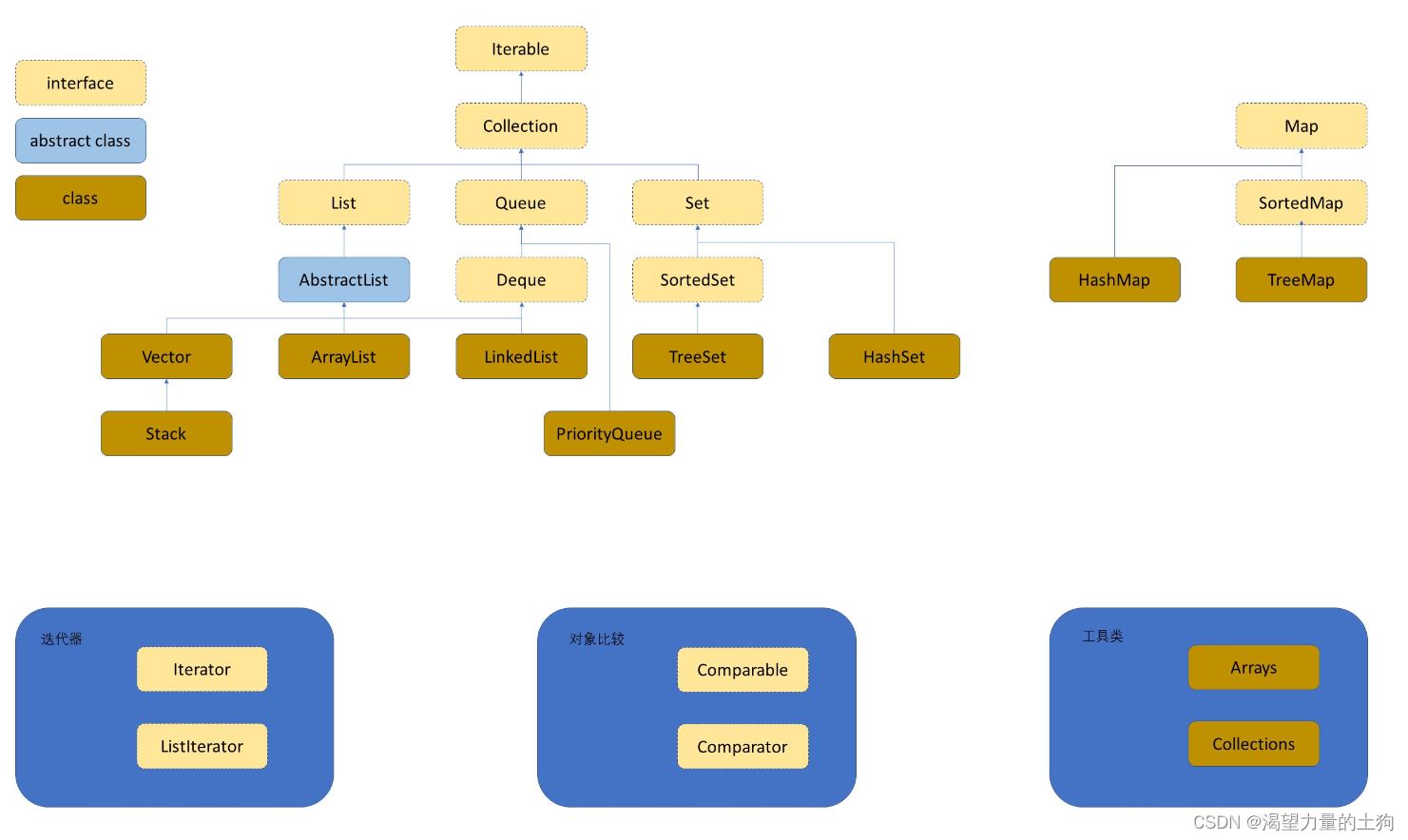
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。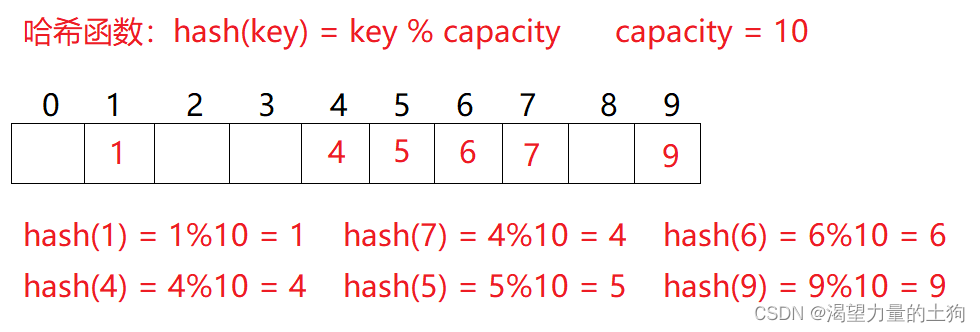 用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快,但是如果数字的余数相同的时候就容易产生冲突(都在同一个位置了)
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快,但是如果数字的余数相同的时候就容易产生冲突(都在同一个位置了)
4.2 冲突-概念
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
4.3 冲突-避免
首先,我们需要明确一点,由于我们哈希表底层数组的容量往往是小于实际要存储的关键字的数量的,这就导致一个问题,冲突的发生是必然的,但我们能做的应该是尽量的降低冲突率。
4.4冲突-避免的方法
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
所以有几种常见的设计哈希函数的方法:
直接定制法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况 面试题:字符串中第一个只出现一次字符
除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
还有几种不常用的方法也列举一下:平方取中法,折叠法,随机数法,数学分析法。
4.5 冲突-避免-负载因子调节(重点掌握)
 负载因子和冲突率的关系粗略演示
负载因子和冲突率的关系粗略演示

所以当冲突率达到一个无法忍受的程度时,我们需要通过降低负载因子来变相的降低冲突率。
已知哈希表中已有的关键字个数是不可变的,那我们能调整的就只有哈希表中的数组的大小。
4.6 冲突-解决
解决哈希冲突两种常见的方法是:闭散列和开散列
4.7 冲突-解决-闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。
存放到下一个位置有两种方式比较常用:
1. 线性探测
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他
元素的搜索。
2. 二次探测 研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:比散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷
4.8 冲突-解决-开散列/哈希桶(重点掌握)
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
链地址法的图示:当有哈希桶在某个下标下,则哈希表对应下标的值为链表头结点的地址,如果没有则为null。每个结点都由key,value与next组成。
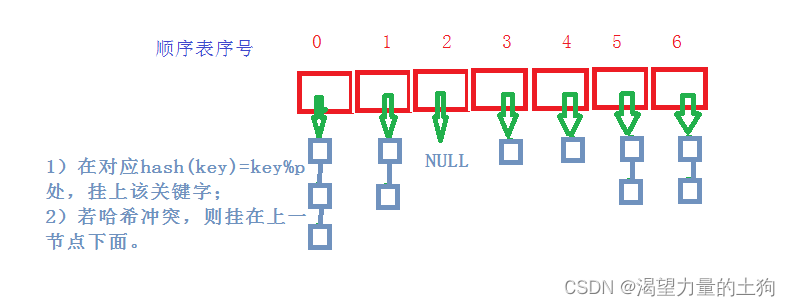
因为是用哈希桶来解决冲突,因此要创建一个每个下标底下都是结点组成的链表的数组Node[] array;,并且用size来记录数组中结点的个数,目的是求出负载因子。而每个哈希桶都是由结点组成的,因此结点类可以定义到哈希桶类里面。put、resize方法:先根据设计的哈希函数求出对应的下标,找到对应下标后去遍历该下标的链表,如果已经有相同的key值的结点,则更新完key值中的value后退出。如果没有,则创建一个哈希桶,设置cur结点从头结点开始,用头插法插入新的结点。当然,插入后要计算出负载因子是否超过了0.75,如果超过就扩容。扩容后数组的长度会变长,因此每个哈希桶根据新的哈希函数的计算结果跟原来的不同,则要重新哈希。(resize方法)等全部哈希桶重新哈希完之后,新的数组的引用要赋值给旧的数组的引用。
get方法:首先要根据哈希函数求出对应的下标,再从下标当中去找是否有相同的值的哈希桶,若有,则返回该哈希桶的value值,否则返回-1。
实现代码:
// key-value 模型
public class HashBucket {
private static class Node {
private int key;
private int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private Node[] array;
public HashBucket() {
// write code here
array=new Node[DEFAULT_SIZE];
}
private int size; // 当前的数据个数
private static final double LOAD_FACTOR = 0.75;
private static final int DEFAULT_SIZE = 8;//默认桶的大小
public void put(int key, int value) {
// write code here
//获取下标
int index=key%array.length;
Node cur=array[index];
//找位置,如果有相同的就覆盖
while (cur!=null){
if(cur.key==key){
cur.value=value;
return;
}
cur=cur.next;
}
//进行插入(头插)
Node head=new Node(key,value);
head.next=array[index];
array[index]=head;
size++;
//负载因子大于0.75时扩容
if(loadFactor()>=0.75){
resize();
}
}
private void resize() {
// write code here
Node[]newArray=new Node[2*array.length];
//对原array中的每一个数据进行重新哈希
for(int i=0;i<array.length;i++){
Node cur=array[i];
while(cur!=null){
Node curNext=cur.next; //保存后续结点
int newIndex=cur.key%newArray.length;
cur.next=newArray[newIndex];
newArray[newIndex]=cur;
cur=curNext;
}
}
array=newArray;//重新赋值
}
private double loadFactor() {
return size * 1.0 / array.length;
}
public int get(int key) {
// write code here
int index=key%array.length;
Node cur=array[index];
//找位置
while (cur!=null){
if(cur.key==key){
return cur.value;
}
cur=cur.next;
}
return -1;
}
}虽然哈希表一直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是一个常数,所以,通常意义下,我们认为哈希表的插入/删除/查找时间复杂度是O(1) 。
一些要注意的点:
1. HashMap 和 HashSet 即 java 中利用哈希表实现的 Map 和 Set
2. java 中使用的是哈希桶方式解决冲突的
3. java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)
4. java 中计算哈希值实际上是调用的类的 hashCode 方法,进行 key 的相等性比较是调用 key 的 equals 方法。所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须覆写 hashCode 和 equals 方法,而且要做到 equals 相等的对象,hashCode 一定是一致的
5.哈希表查找成功与查找失败的求法
5.1 查找成功的求法
一个哈希表如下图:
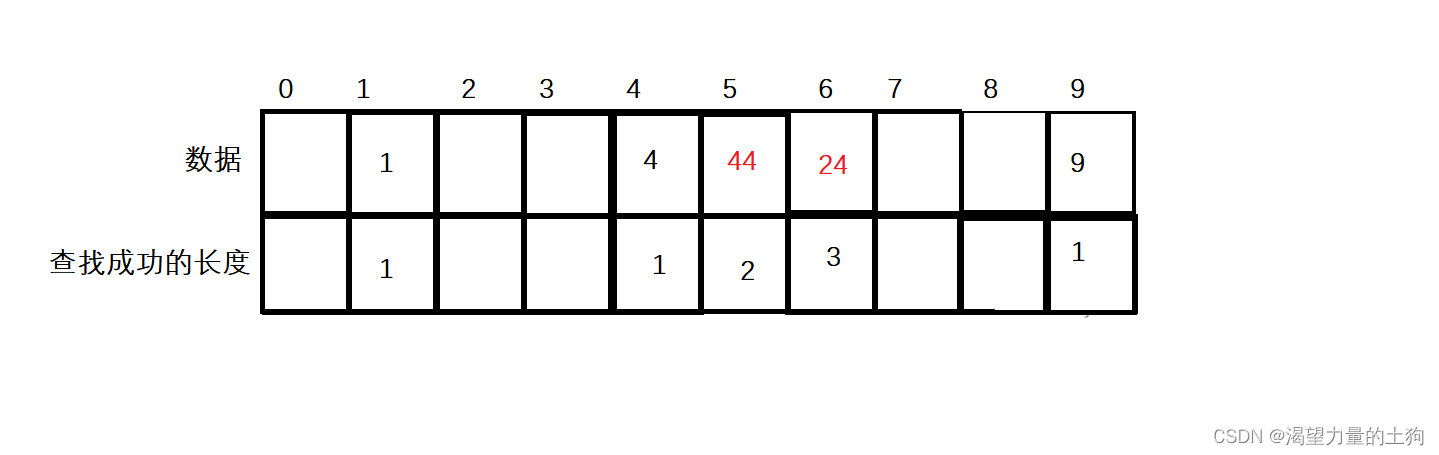
假设现在要查找4,则根据哈希函数Hash(key)=key%array.length,找到了4下标,因为4下标下的数据就是4,则查找一次就成功,1和9数据的查找成功次数求法也是一致。
假设此时要查找24,则先根据哈希函数求出下标为4,但是4下标的数据是4,而不是24,算查找一次。此时往后移一个单位,发现是44不是我们查找的24,则算查找第二次。此时再往后移一个单位,发现是24,算是查找的次数是第三次。因此上图中查找成功的平均查找长度:(1+1+2+3+1)/5=8/5。
如果找9下标的值查找的不是要查找的数据,则返回到0下标开始找,并且找9下标失败后算查找1次。
5.2 查找失败的求法
一个哈希表如下图:
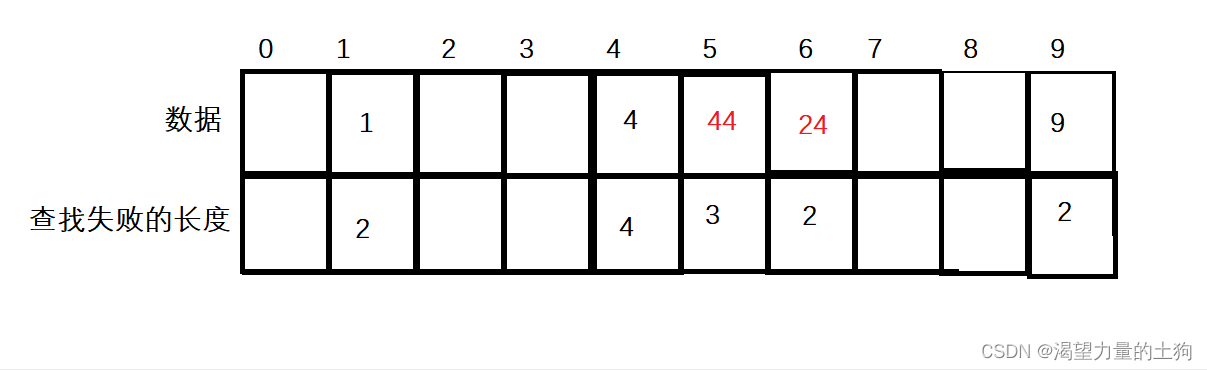
第一次假如找数据1,则根据哈希函数Hash(key)=key%array.length求得下标为1,假设下标1中的数据不是我们找的数据1,算查找失败了一次,则向后移一个单位去找。此时下标2的值为空,则说明查找失败,算查找失败了两次。
If you are looking for data 44 at this time, the subscript is 4 according to the hash function, but the data under subscript 4 is not 44 at this time, then there is no guarantee that the search will be successful. Therefore, move back one unit to search, and find that the data of subscript 5 is 44, and the number of search failures will start to be counted from this time. We still have to assume that the search for the current 5 subscripts has failed, and if the search fails once, then move back one unit to find it. Still the same, assuming that the value of subscript 6 is not 44, and the search fails, move back one unit to find it. After reaching the subscript 7, if the data of the subscript is found to be empty, the search must have failed, and this time it is counted as a search, so the length of the search failure adds up to three times.
Note: The operation of finding a failure is to find the next empty place backwards from the value that is actually found.