Table of contents
foreword
The original link of this article is:
https://blog.csdn.net/freewebsys/article/details/108971807
Not to be reproduced without permission of the blogger.
The blogger’s CSDN address is: https://blog.csdn.net/freewebsys
The blogger’s nugget address is: https://juejin.cn/user/585379920479288
The blogger’s Zhihu address is: https://www.zhihu. com/people/freewebsystem
1. A few examples of learning about gpt2
Quickly use the docker image to build the environment.
Related chatGpt projects are:
gpt2 official model:
https://github.com/openai/gpt-2
6.1K stars:
https://github.com/Morizeyao/GPT2-Chinese
2.4K stars:
https://github. com/yangjianxin1/GPT2-chitchat
1.6K stars:
https://github.com/imcaspar/gpt2-ml
Find a simple one for research:
3.2K stars:
https://github.com/minimaxir/gpt-2-simple
2. Use docker to configure the environment
Let’s take an official example first, using tensorflow’s 2.12 image, because of graphics card driver problems, only CPU can be used for calculation:
git clone https://github.com/minimaxir/gpt-2-simple
cd gpt-2-simple
docker run --name gpt2simple -itd -v `pwd`:/data -p 8888:8888 tensorflow/tensorflow:latest
Version description, the smallest version is used here: as long as it can run.
latest: minimal image with TensorFlow Serving binary installed and ready to serve!
:latest-gpu: minimal image with TensorFlow Serving binary installed and ready to serve on GPUs!
:latest-devel - include all source/dependencies/toolchain to develop, along with a compiled binary that works on CPUs
:latest-devel-gpu - include all source dependencies/toolchain (cuda9/cudnn7) to develop, along with a compiled binary that works on NVIDIA GPUs.
Then enter the docker image to execute the command:
Of course, you can also use Dockerfile, but the network speed is slow and error-prone:
docker exec -it gpt2simple bash
############### 以下是登陆后执行:
sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
sed -i 's/security.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list
mkdir /root/.pip/
# 增加 pip 的源
echo "[global]" > ~/.pip/pip.conf
echo "index-url = https://mirrors.aliyun.com/pypi/simple/" >> ~/.pip/pip.conf
echo "[install]" >> ~/.pip/pip.conf
echo "trusted-host=mirrors.aliyun.com" >> ~/.pip/pip.conf
cd /data
#注释掉 tensorflow 依赖
sed -i 's/tensorflow/#tensorflow/g' requirements.txt
pip3 install -r requirements.txt
3. Use the uget tool to download the model, the file is large and easy to get stuck
sudo apt install uget
Then the network is extremely slow. Can't download at all, just stuck in progress. Several particularly large models, the largest 6G.
One is bigger than the other, I don’t know if it’s compressed or not:
498M:
https://openaipublic.blob.core.windows.net/gpt-2/models/124M/model.ckpt.data-00000-of-00001
1.42G
https:/ /openaipublic.blob.core.windows.net/gpt-2/models/355M/model.ckpt.data-00000-of-00001
3.10G
https://openaipublic.blob.core.windows.net/gpt-2/ models/774M/model.ckpt.data-00000-of-00001
6.23G
https://openaipublic.blob.core.windows.net/gpt-2/models/1558M/model.ckpt.data-00000-of-00001
Use the tool to download the model, and it is easy to get stuck when executing the command line:
This cloud address does not support multi-threaded downloads, so I downloaded a minimum 124M model.
Just try something fresh first.
The remaining files can be downloaded separately:
For the code in gpt2, remove the model file and download it with a script. The network is a big problem.
There is no domestic mirror image either.
download_model.py 124M
Modified the code, removed the largest model.ckpt.data which was downloaded separately, downloaded and copied into it.
import os
import sys
import requests
from tqdm import tqdm
if len(sys.argv) != 2:
print('You must enter the model name as a parameter, e.g.: download_model.py 124M')
sys.exit(1)
model = sys.argv[1]
subdir = os.path.join('models', model)
if not os.path.exists(subdir):
os.makedirs(subdir)
subdir = subdir.replace('\\','/') # needed for Windows
for filename in ['checkpoint','encoder.json','hparams.json', 'model.ckpt.index', 'model.ckpt.meta', 'vocab.bpe']:
r = requests.get("https://openaipublic.blob.core.windows.net/gpt-2/" + subdir + "/" + filename, stream=True)
with open(os.path.join(subdir, filename), 'wb') as f:
file_size = int(r.headers["content-length"])
chunk_size = 1000
with tqdm(ncols=100, desc="Fetching " + filename, total=file_size, unit_scale=True) as pbar:
# 1k for chunk_size, since Ethernet packet size is around 1500 bytes
for chunk in r.iter_content(chunk_size=chunk_size):
f.write(chunk)
pbar.update(chunk_size)
4. The study uses gpt2-simple to execute the demo and train 200 times
Then run demo.py code
project code:
Prepare the model and files in advance:
https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
Save as,
shakespeare.txt in the project directory
gpt-2-simple/models$ tree
.
└── 124M
├── checkpoint
├── encoder.json
├── hparams.json
├── model.ckpt.data-00000-of-00001
├── model.ckpt.index
├── model.ckpt.meta
└── vocab.bpe
1 directory, 7 files
https://github.com/minimaxir/gpt-2-simple
import gpt_2_simple as gpt2
import os
import requests
model_name = "124M"
file_name = "shakespeare.txt"
sess = gpt2.start_tf_sess()
print("########### init start ###########")
gpt2.finetune(sess,
file_name,
model_name=model_name,
steps=200) # steps is max number of training steps
gpt2.generate(sess)
print("########### finish ###########")
implement:
time python demo.py
real 80m14.186s
user 513m37.158s
sys 37m45.501s
Start training, do testing, and model training 200 times. Time-consuming is 1 hour and 20 minutes.
It uses Intel® Core™ i7-9700 CPU @ 3.00GHz, 8 cores and 8 threads.
Use CPU for training, no graphics card.
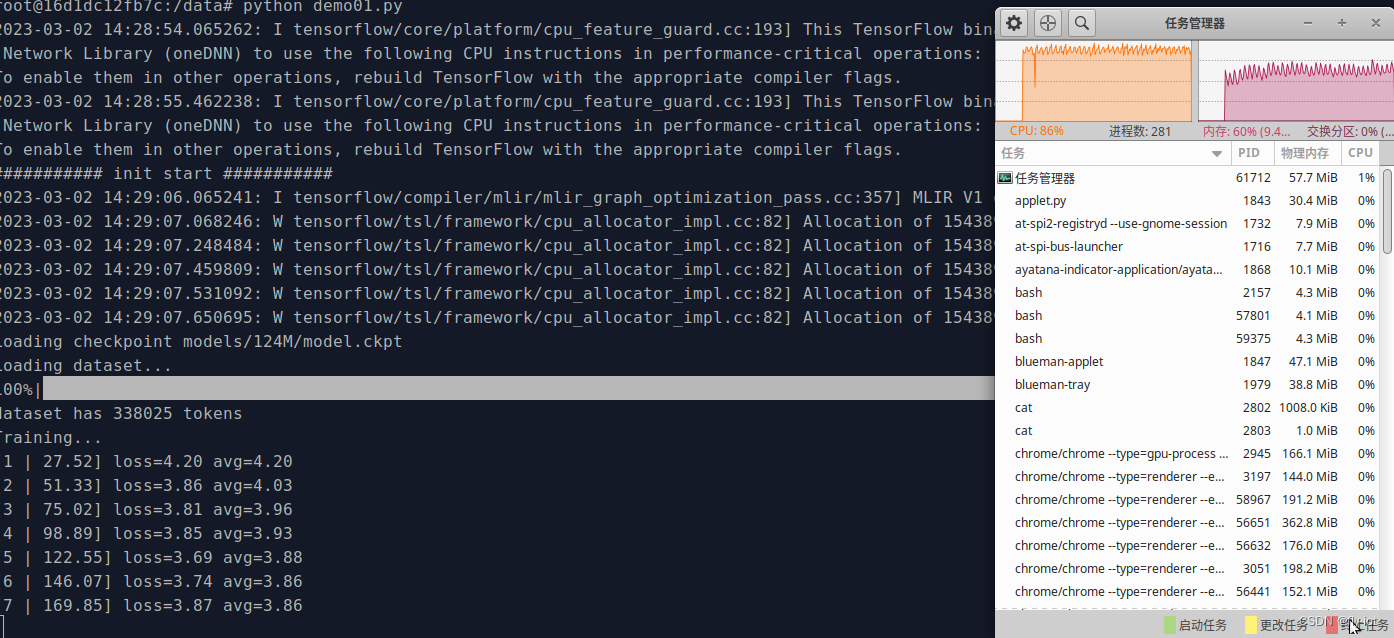
The cpu is 80%, the load is 7, and the fan is spinning.
Then generate the dialog:
demo-run.py
import gpt_2_simple as gpt2
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess)
gpt2.generate(sess)
Execution results without cpu/gpu optimization:
python demo_generate.py
2023-03-03 13:11:53.801232: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-03 13:11:55.191519: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-03 13:11:57.054783: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:357] MLIR V1 optimization pass is not enabled
Loading checkpoint checkpoint/run1/model-200
Ministers' policy: policy
I am the king, and
I shall have none of you;
But, in the desire of your majesty,
I shall take your honour's honour,
And give you no better honour than
To be a king and a king's son,
And my honour shall have no more than that
Which you have given to me.
GLOUCESTER:
MONTAGUE:
Mistress:
Go, go, go, go, go, go, go, go, go!
GLOUCESTER:
You have done well, my lord;
I was but a piece of a body;
And, if thou meet me, I'll take thy pleasure;
And, if thou be not satisfied
I'll give thee another way, or let
My tongue hope that thou wilt find a friend:
I'll be your business, my lord.
MONTAGUE:
Go, go, go, go!
GLOUCESTER:
Go, go, go!
MONTAGUE:
Go, go, go!
GLOUCESTER:
You have been so well met, my lord,
I'll look you to the point:
If thou wilt find a friend, I'll be satisfied;
Thou hast no other choice but to be a king.
MONTAGUE:
Go, go, go!
GLOUCESTER:
Go, go, go!
MONTAGUE:
Go, go, go!
GLOUCESTER:
Go, go, go!
MONTAGUE:
Go, go, go!
GLOUCESTER:
Go, go, go!
KING RICHARD II:
A villain, if you have any, is a villain without a villain.
WARWICK:
I have seen the villain, not a villain,
But--
KING RICHARD II:
Here is the villain.
WARWICK:
A villain.
KING RICHARD II:
But a villain, let him not speak with you.
WARWICK:
Why, then, is there in this house no man of valour?
KING RICHARD II:
The Lord Northumberland, the Earl of Wiltshire,
The noble Earl of Wiltshire, and the Duke of Norfolk
All villainous.
WARWICK:
And here comes the villain?
KING RICHARD II:
He is a villain, if you be a villain.
Every generated dialogue is different. You can run it several times, and the generated content will be different.
5. Summary
AI is really a high-tech thing, there are not many codes, but I just don't understand it very well.
Then consume CPU and GPU resources, which is also very hardware-intensive.
It takes so much time to train this small model 200 times, let alone a model with a large amount of data and multiple parameters! !
At the same time, the infrastructure needs to be built. There is a project to be studied, which is
https://www.kubeflow.org/
I have to study server clusters. Because of Nvidia's limitations, the servers run on expensive and low-performance graphics cards.
But you can run clusters locally for training! ! !
The original link of this article is:
https://blog.csdn.net/freewebsys/article/details/108971807