GPT model
GPT model: Generative Pre-Training
The overall structure:
Unsupervised pre-training
Supervised fine-tuning for downstream tasks
Core structure: the middle part is mainly composed of 12 Transformer Decoder blocks stacked
The following picture more intuitively reflects the overall structure of the model:
Model description
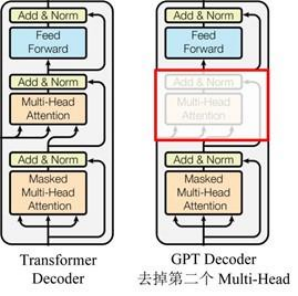
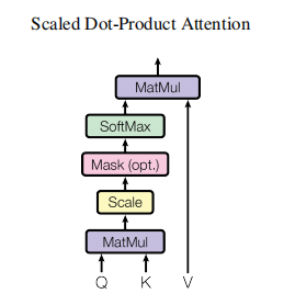
GPT uses Transformer 's Decoder structure and makes some changes to Transformer Decoder. The original Decoder contains two Multi-Head Attention structures, and GPT only retains Mask Multi-Head Attention, as shown in the figure below.
(A lot of data say that it is similar to the decoder structure, because the mask mechanism of the decoder is used, but aside from this, it actually feels more similar to the encoder, so sometimes it is implemented by adjusting the encoder instead. Don’t )
Compared with the structure of the original transformer
stage description
Pre-training phase:



The pre-training stage is text prediction, that is, predicting the current word based on the existing historical words. The three formulas 7-2, 7-3, and 7-4 correspond to the previous GPT structure diagram, and the output P(x) is the output. The probability of each word being predicted, and then use the 7-1 formula to calculate the maximum likelihood function, and construct a loss function based on this, that is, the language model can be optimized.
Downstream task fine-tuning stage

loss function
A linear combination of downstream tasks and upstream task losses

calculation process:
- enter
- Embedding
- Multi-layer transformer block
- Get two output results
- calculate loss
- backpropagation
- update parameters
A specific GPT example code:
You can see that in the forward function of the GPT model, the Embedding operation is performed first, then the operation is performed in the block of the 12-layer transformer, and then the final calculation value is obtained through two linear transformations (one for text prediction) , one for the task classifier), the code is consistent with the model structure diagram shown at the beginning.
Reference: Don't bother
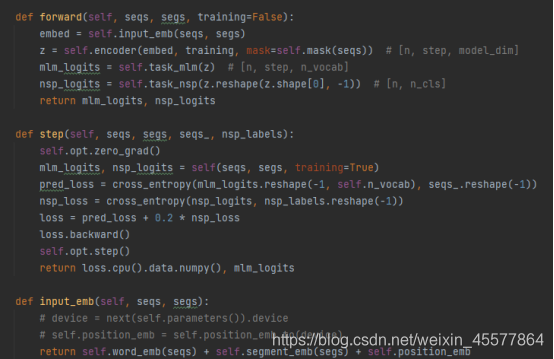
with Python GPT implementation code Let's focus on calculation steps 2 and 3
Calculation details:
[Embedding layer]:
The embedding layer for table lookup operation
is a fully connected layer with one hot as input and intermediate layer nodes as word vector dimensions. And the parameter of this fully connected layer is a "word vector table".

The matrix multiplication of the one hot type is equivalent to a table lookup, so it directly uses the table lookup as an operation instead of writing it into a matrix for calculation, which greatly reduces the amount of calculation. It is emphasized again that the reduction in the amount of computation is not due to the emergence of word vectors, but because the one hot matrix operation is simplified to a table lookup operation.
[Decoder layer similar to transformer in GPT]:
Each decoder layer contains two sublayers
- sublayer1: multi-head attention layer for mask
- sublayer2: ffn (feed-forward network) feedforward network (multilayer perceptron)
sublayer1: mask's multi-head attention layer
输入:q, k, v, mask
计算注意力:Linear (matrix multiplication)→Scaled Dot-Product Attention→Concat (multiple attention results, reshape)→Linear(matrix multiplication)
残差连接和归一化操作:Dropout operation → residual connection → layer normalization operation
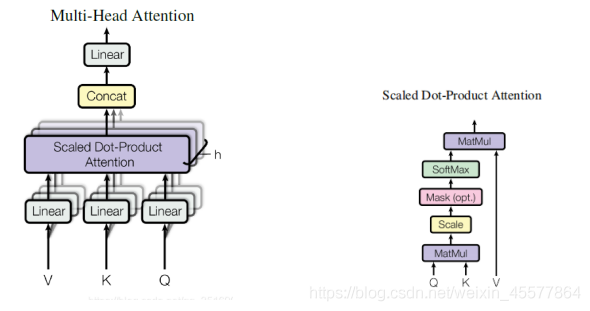
calculation process:
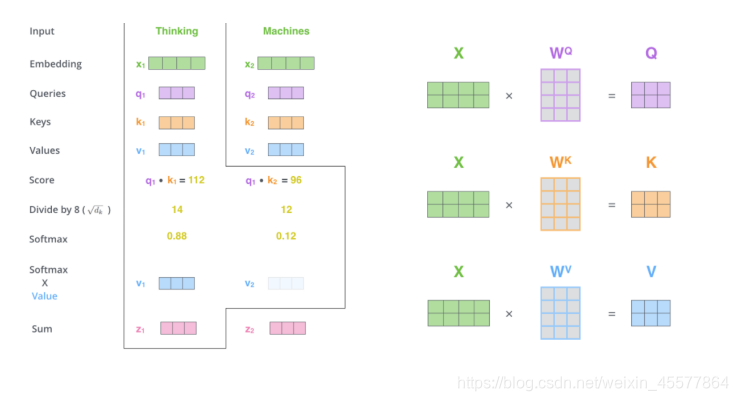
The following paragraph describes the overall process of calculating attention:

Explosion instructions:
Mask Multi-head Attention
1. Matrix multiplication:
Transform the input q, k, v
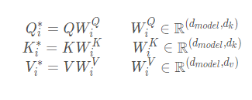
2.Scaled Dot-Product Attention
The main thing is to perform the calculation of attention and the operation of mask.
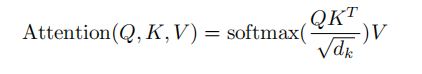
Mask operation: masked_fill_(mask, value)
mask operation, fills the element in the tensor corresponding to the value 1 in the mask with value. The shape of the mask must match the shape of the tensor to be filled. (Here, -inf padding is used, so that the softmax becomes 0, which is equivalent to not seeing the following words)
The mask operation in the transformer
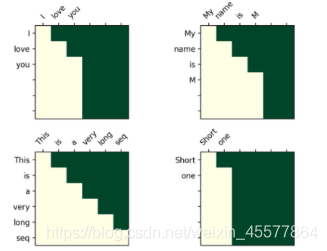
Visualization matrix after mask:
The intuitive understanding is that each word can only see the word before it (because the purpose is to predict the future word, if you see it, you don’t need to predict it)
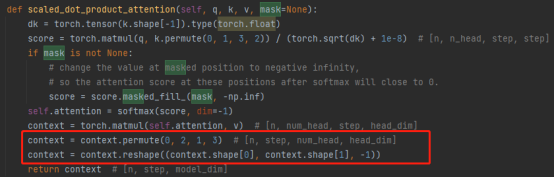
3. Concat operation:
Combining the results of multiple attention heads actually transforms the matrix: permute, reshape operations, and dimensionality reduction. (As shown in the red box in the figure below)
4. Matrix multiplication: a Linear layer, which linearly transforms the attention results
The multi-head attention layer of the entire mask 代码:
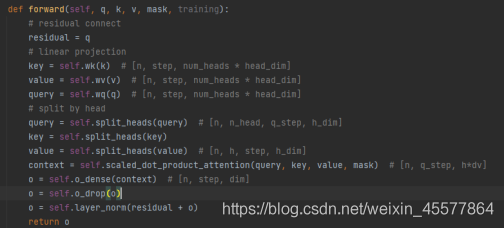
Note: the following lines in the above code are to 残差连接和归一化操作
explain the process of attention results:
Residual connection and normalization operations:
5.Dropout layer
6. Matrix addition
7. Layer normalization
Batch normalization is the normalization of a single neuron between different training data, and layer normalization is the normalization of a single training data among all neurons of a certain layer.
Input normalization, batch normalization (BN) and layer normalization (LN)
代码展示:
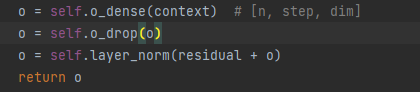
sublayer2: ffn (feed-forward network) feedforward network
1. Linear layer (matrix multiplication)
2. Relu function activation
3. Linear layer (matrix multiplication)
4. Dropout operation
5. Layer normalization
[Linear layer]:
The output results of the multi-layer block are put into two linear layers for transformation, which is relatively simple and will not be described in detail.
Supplement: Attention layer flow diagram
References
1. Reference paper: Radford et al. "Improving Language Undersatnding by Generative Pre-Training"
2. Reference book: "Natural Language Processing Based on Pre-training Model Method" Che Wanxiang, Guo Jiang, Cui Yiming
3. The source of the code in this article : Don't bother with Python GPT implementation code
4. Other reference links (parts mentioned in the blog post):
Word embedding calculation process analysis
Transformer's matrix dimension analysis and Mask detailed explanation