1. Time series data and its characteristics
Time Series Data is a series of indicator monitoring data that is continuously generated based on a relatively stable frequency, such as the Dow Jones Index within a year, the measured temperature at different time points in a day, and so on. Time series data has the following characteristics:
- Invariance of historical data
- data validity
- Timeliness of data
- structured data
- volume of data
Second, the basic structure of time series database
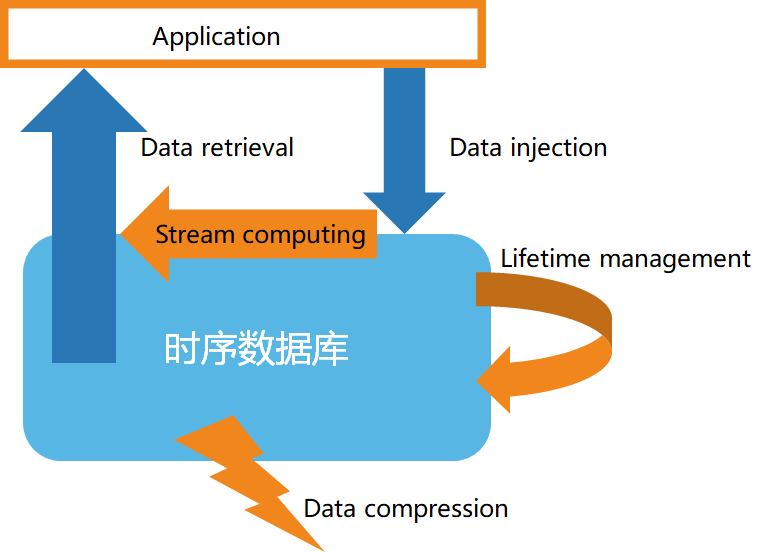
According to the characteristics of time series data, time series databases generally have the following characteristics:
- High-speed data storage
- Data Lifecycle Management
- Stream processing of data
- Efficient data query
- Custom Data Compression
3. Introduction to Stream Computing
Stream computing mainly refers to the real-time acquisition of massive data from different data sources, and real-time analysis and processing to obtain valuable information. Common business scenarios include rapid response to real-time events, real-time alarms for market changes, interactive analysis of real-time data, etc. Stream computing generally includes the following functions:
1) Filtering and conversion (filter & map)
2) Aggregation and window functions (reduce, aggregation/window)
3) Merging of multiple data streams and pattern matching (joining & pattern detection)
4) From stream to block processing
4. Time series database support for stream computing
-
Case 1: Use a customized stream computing API, as shown in the following example:
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
Case 2: Use SQL-like instructions to create stream computing and define stream computing rules, as follows:
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);